Whelp, the 360-degree camera rumor mill is running wild. Every since some registration paperwork was discovered about unannounced camera models, everyone is suddenly an expert on what the new models will be like – yet again.
Pro tip*: If you want to save some time, just block any influencer that is currently using photos showing fake images of hands holding the unreleased cameras, or boxes, or anything else. You can be assured these folks are not there to show truth – they are creating fake images for clicks. DO NOT TRUST.
You will then see your feed becomes much quieter.
Good luck, fakefluencers.
* There is nothing “professional” about a tip. Unless the person is a professional at giving tips, I guess…
NOTE: The author of this work will be referred to as Abraham Lincoln ;-) per this comment: “Thanks! But I’m terribly modest and shy away from attention. So, I humbly request that you refer to me as “Abraham Lincoln”.” ;-)
TRSDOS was the name of the disk operating system that Radio Shack used on their TRS-80 computers.
There were alternative DOSes available, but TRSDOS is where it started, and what shipped with the original machines. As I write this post, I see that the last version of TRSDOS was released 42 years ago.
When the TRS-80 Color Computer came out in 1980, it was a T.I.N.O. – “TRS-80 In Name Only”. The 80 in TRS-80 came from the Zilog Z-80 processor, and the Color Computer used a Motorola 6809 processor. I assume Tandy just wanted to leverage the popularity of the TRS-80 brand and continue using that name. The use of TRS-80 continued even into 1983 when Tandy brought out its first PC-compatible-ish machine, the Tandy 2000. Officially called the “Tandy” 2000, the badge on the front of the machine still read “Tandy TRS-80.” This was, according to the always-accurate Wikipedia, the final use of TRS-80 branding on a Radio Shack computer. When the more-PC-compatible-ish Tandy 1000 came out in 1984, it was solely a Tandy-branded machine.
But I digress.
TRSDOS was never a thing for the CoCo. There was no disk operating system. Instead, the CoCo booted into a ROM BASIC. When a Disk Controller was added, it contained another ROM that extended the basic with new disk-related commands. DISK EXTENDED BASIC was not an operating system, but most of us referred to it as “RS-DOS” (Radio Shack DOS, one would presume). I am unsure when we started calling it RS-DOS. This would be a good side quest to research. I assume by the time OS-9 (an actual disk operating system) was released, we would have needed some way to tell if a program ran from DISK BASIC or required OS-9.
But I digress, again.
Color TRSDOS was a thing.
Color TRSDOS did exist, but perhaps it was another T.I.N.O. – this time meaning “TRSDOS In Name Only”. Color TRSDOS was included with the DISK EDTASM 6809 assembler. In the manual was a source code listing and on the disk was a DOS.BIN binary and DOS.BAS loader program that was Color TRSDOS.
DISK EDTASM – directory
But what was Color TRSDOS?
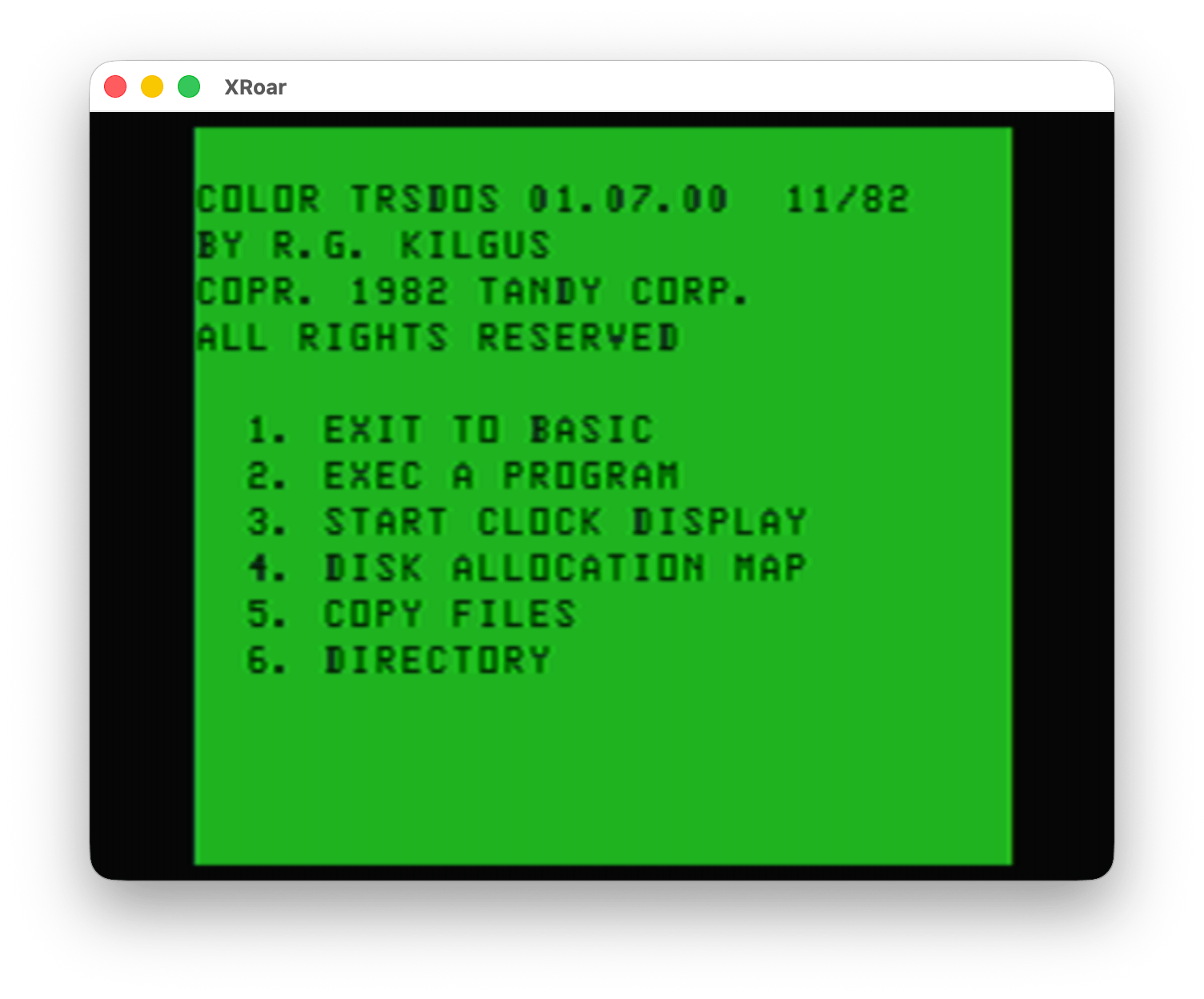
What was Color TRSDOS?
If you do a RUN”DOS” form the Disk EDTASM disk, you are greeted with a menu:
Color TRSDOS – menu
The name “R.G. Kilgus” is instantly recognizable to early adopters of the CoCo. R.G. created some of the earliest Radio Shack programs for to CoCo, including the infamous Dino Wars!
As you may be able to tell from the screenshot, Color TRSDOS was not a DOS like we might expect. Normally, a DOS boots up into a command line that lets you run programs. MS-DOS is probably the most iconic DOS that comes to mind for me:
Instead, Color TRSDOS seemed to be more of a library of disk routines that one could use with their own 6809 assembly programs. BASIC documented a few “official” ROM calls that could be called from assembly routines to do things like print a character to the screen or input a character from the keyboard. DISK BASIC added one that could read or write raw data to a disk. This was very low level, and there was no ROM call to do things like read a directory, create a new file, delete an existing file, or anything else. This means assembly language programmers had to figure that out and write all that code themselves.
Color TRSDOS appears to have been Radio Shack’s official solution for this. You could use the Color TRSDOS assembly language routines in your own programs and get higher level disk functionality, such as the things shown in the Color TRSDOS menu.
Side Note: What was the license agreement for Color TRSDOS? Could that code be included in commercial sold software, or was it only allowed to be used for personal programs? Anyone know?
Maybe I ran into Color TRSDOS in some CoCo program I used over the years. There were certainly many programs that could load/save files to disk and show directories. Maybe some of these made use of the Color TRSDOS routines. Does anyone know of any program that ever used the Color TRSDOS routines?
What could Color TRSDOS do?
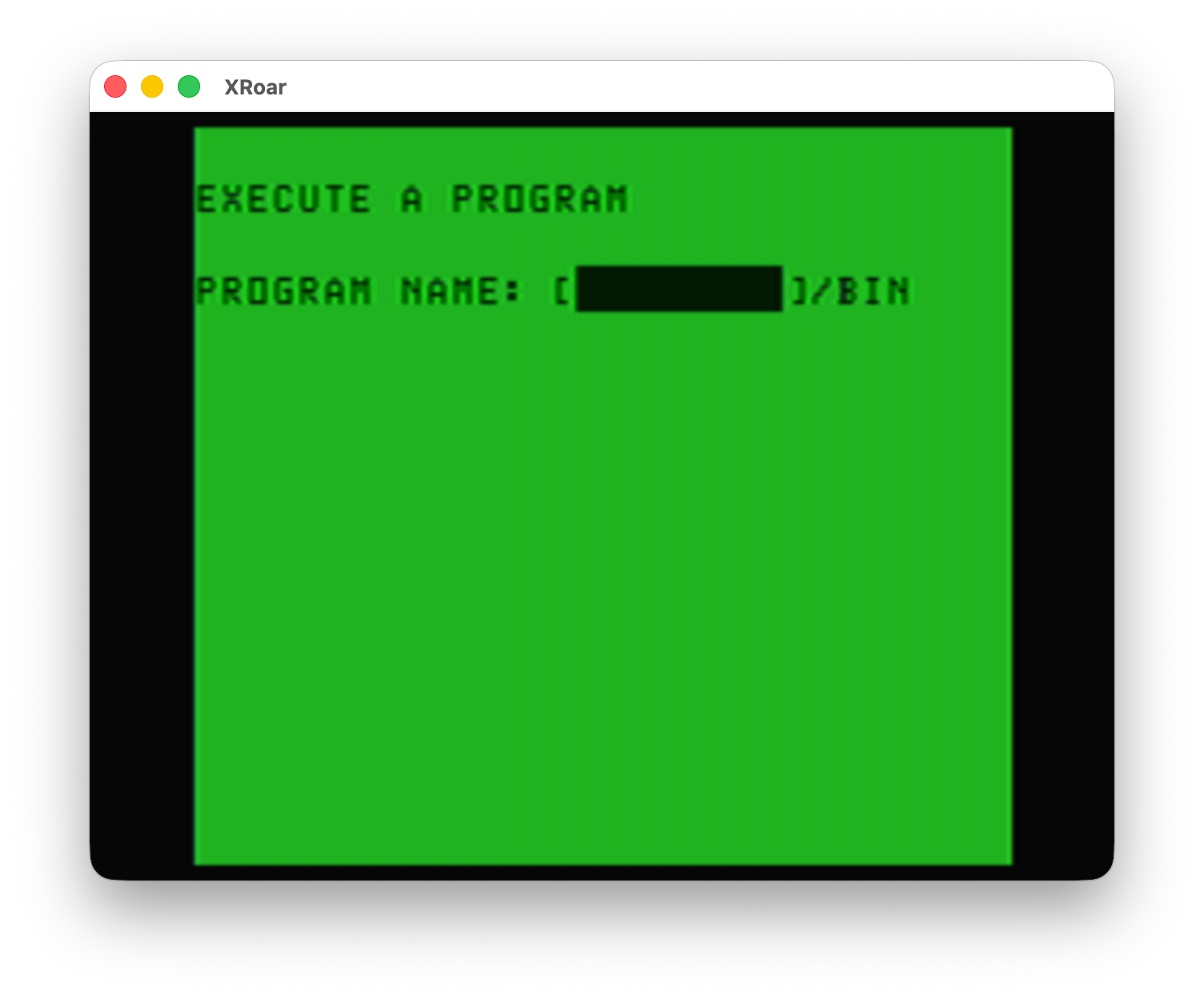
It appears Color TRSDOS has a way to load and execute a binary program, as demonstrated from menu option #2:
Color TRSDOS – Exec a Program
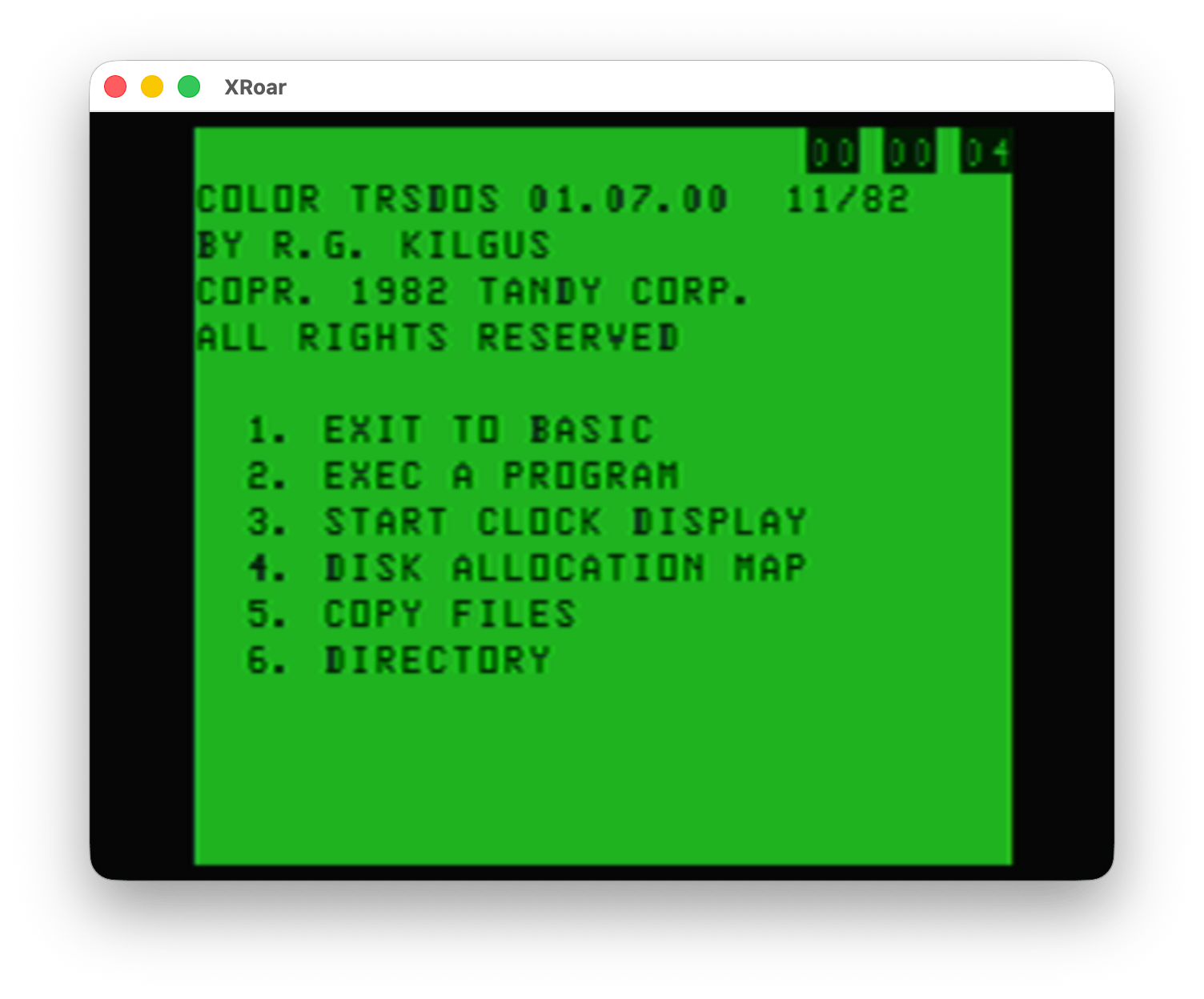
There was also support for a software clock, as demonstrated by menu option #3. It would put an incrementing Hour/Minute/Second value in the top corner of the screen:
Color TRSDOS – Start Clock Display
The Color Computer used the video circuitry to generate a 60Hz signal (also used by the TIMER command in BASIC). It was common for software clocks to make use of this and track time, though this time would drift any time interrupts were masked — such as when accessing a disk.
I have not explored the code myself, but I assume Color TRSDOS just provided a simple software clock for programs to use.
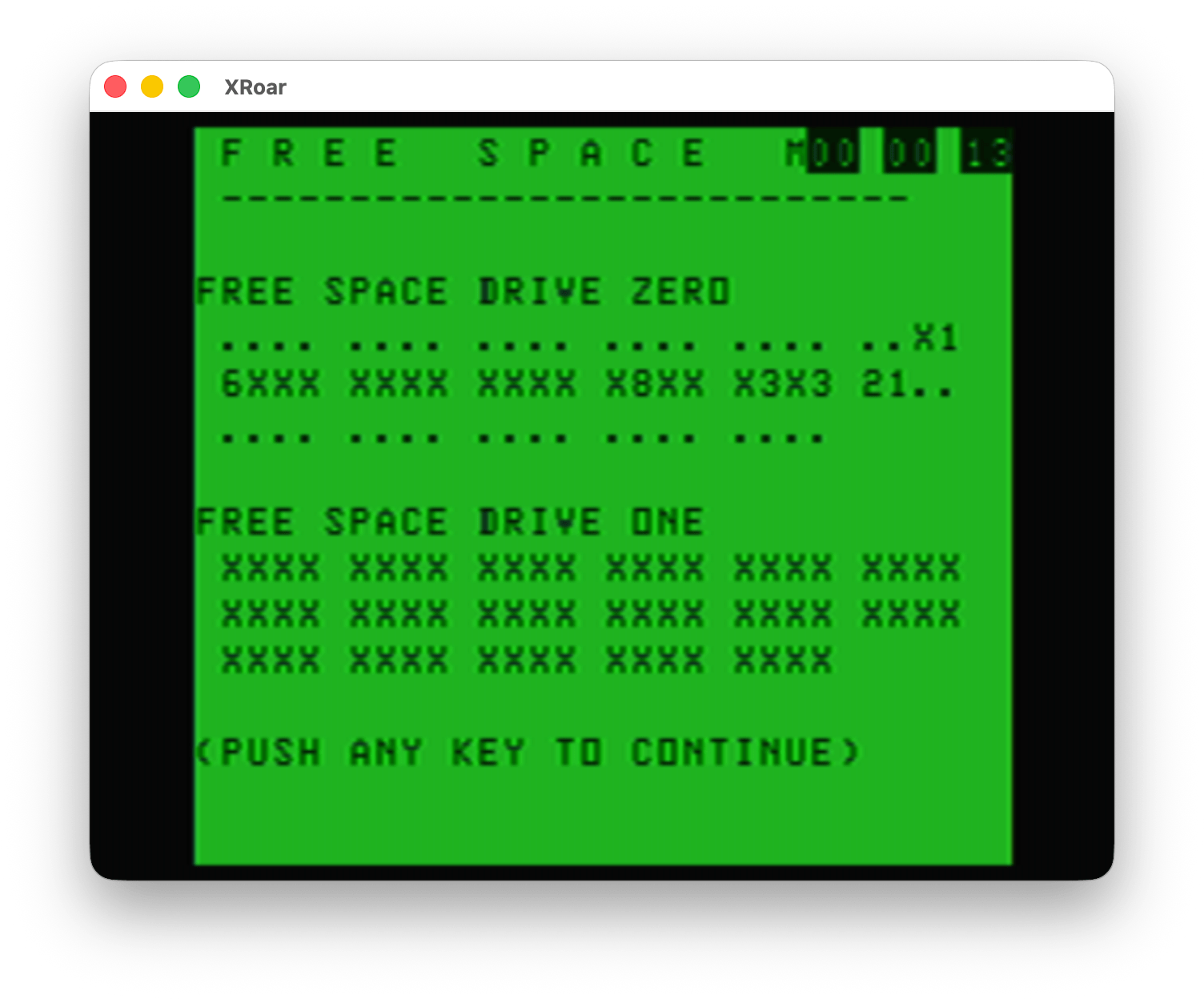
Option #4 would display the Disk Allocation Map. This display showed which granules on the disk were in use. From looking at the display, you can see it represents the 68 granules (9 256-byte sectors, 2304 bytes) that make up an RS-DOS disk. It looks like “.” indicates the granule is free, “X” may indicate all of the 9 of the 256-byte sectors in that granule are used, and a number may indicate how many sectors are used (if less than 9).
Color TRSDOS – Disk Allocation Map (DAM)
I have discussed DISK EXTENDED BASIC’s format and this Disk Allocation Map in previous blog posts. Check that link to learn more about granules and such.
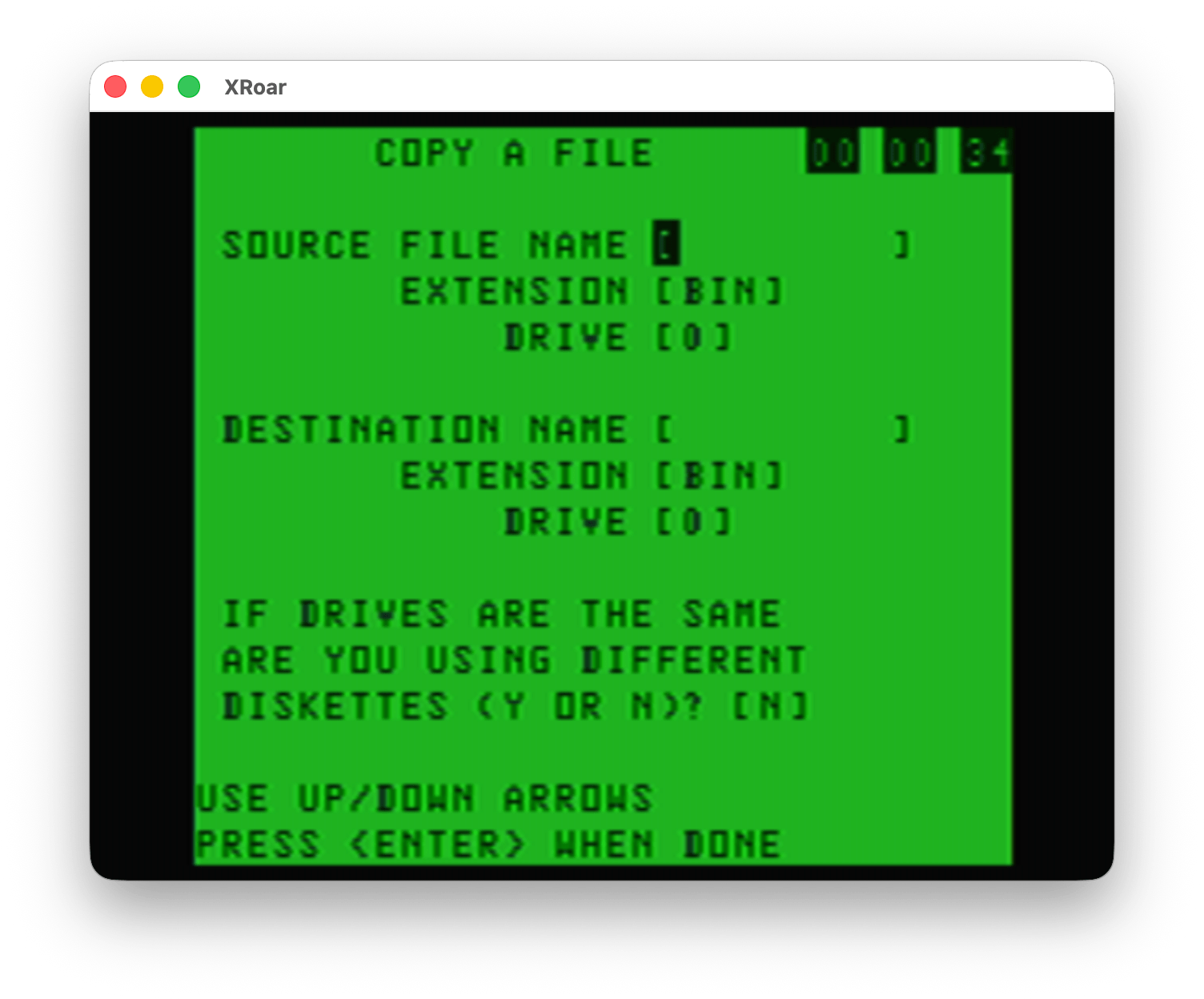
Option #5 showed a simple interface to copy a file, either between the same disk or to separate disks. To copy a file to the same disk in Disk BASIC, you’d do something like this:
COPY "FILE.BAS" TO "NEWFILE.BAS"
This basically duplicated the file, and required a different name for the copy.
To copy a file from Drive 0 to Drive 1:
COPY "FILE.BAS:0" TO "FILE.BAS:1"
But BASIC had no way to copy between separate disks if you only had one disk drive. It looks like this Color TRSDOS program may have a way to do that, where it would read data from the disk, then tell you to swap in the second disk, then write it out there. (I did not test this.)
Color TRSDOS – Copy Files
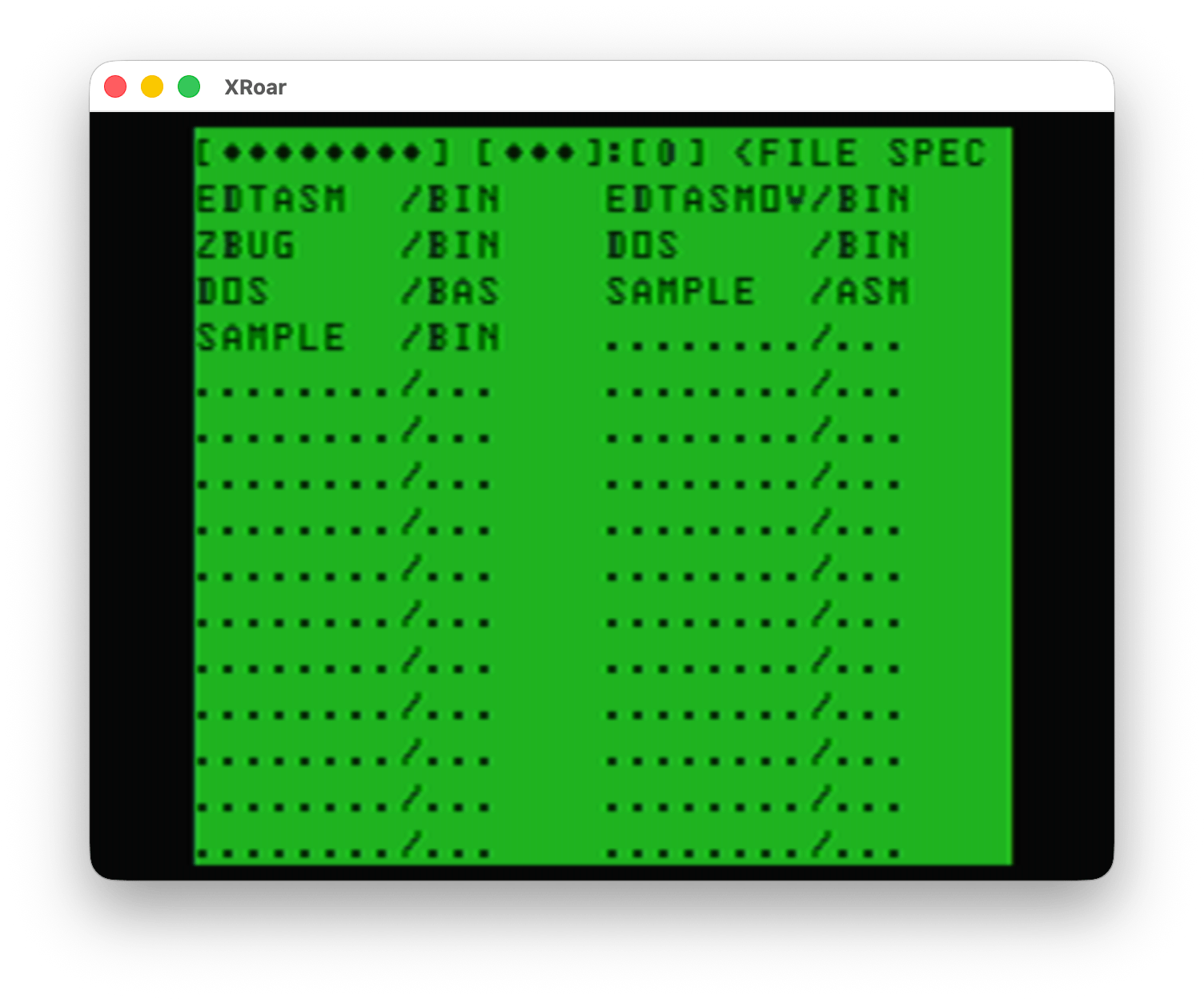
Last, option #6 performed a disk directory. I am unsure how this works, since it initially shows nothing and has some fields where you can type. Perhaps this supported some level of wild cards?
UPDATE: After I wrote this, I went back to try it. You can arrow over to the extension field and enter “BAS” then it only showed the “DOS.BAS” file. Neat! Perhaps wildcard support is built in to the Color TRSDOS routines?
Color TRSDOS – Directory
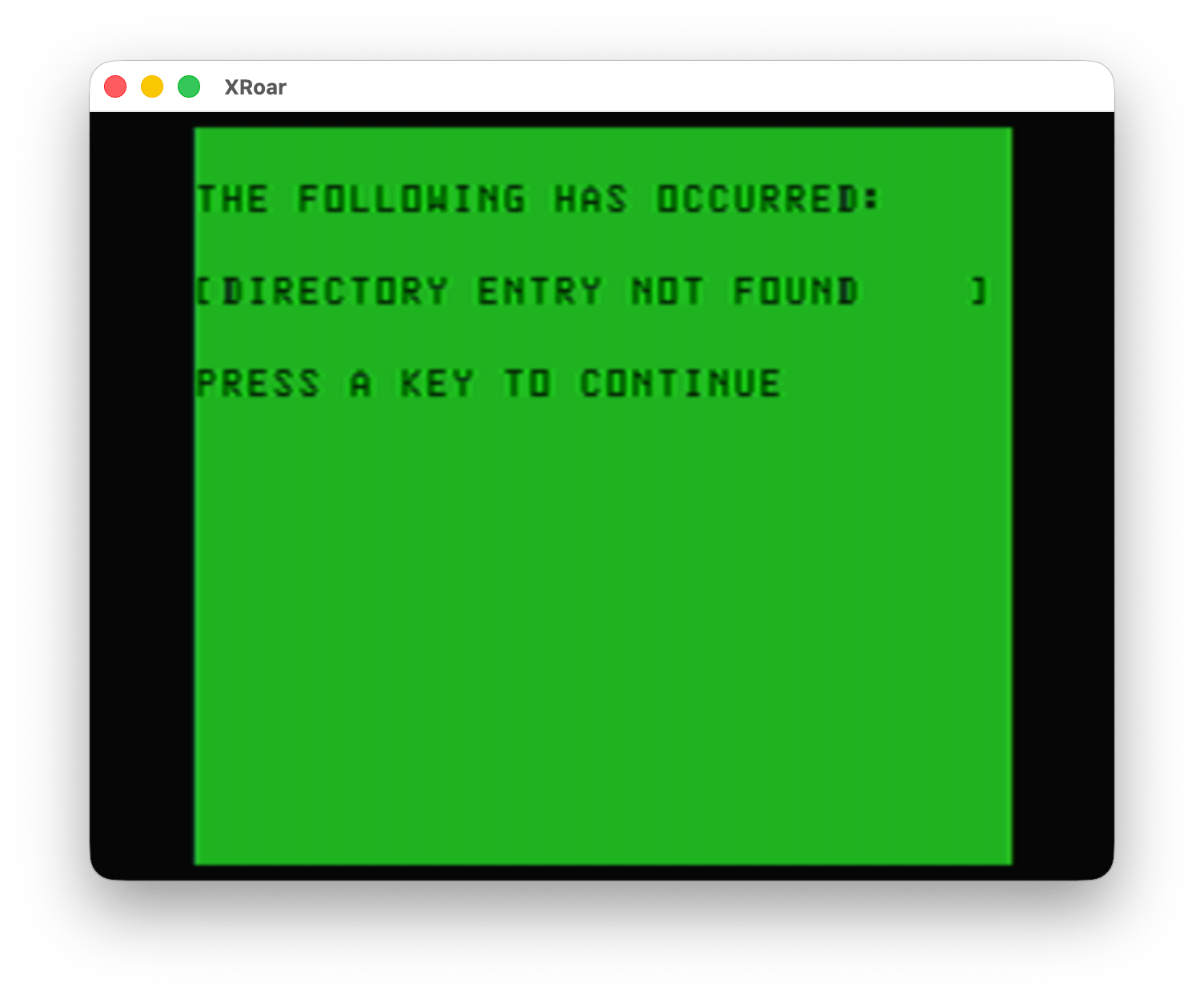
And, of course, error handling…
Color TRSDOS – Error
It looks kinda neat. Had I realized this back then, I could have been adding disk support to my own assembly programs. I really didn’t know it was a thing.
Color TRSDOS is a thing, again!
Well, maybe I get a second chance now. Thanks to the tireless efforts of Abraham Lincoln, Color TRSDOS has been archived to GitHub. In a Facebook CoCo group post dated June 20 2026, he wrote:
“. . . I found an OCR scan of the Disk EDTASM manual and was able to copy-paste the source code from that. There were LOTS and LOTS and LOTS of errors introduced via the OCR scanning process, but I was able to resolve everything, and even correct a bug that was in the original manual (as determined from the non-OCR version) but subsequently fixed in the DOS.BIN executable that shipped with Disk EDTASM.
Now we can generate the exact DOS.BIN executable from source. I went through this exercise so that anyone who is interested can study, learn from, and incorporate the code into their projects, if they’d like. For me, in particular, I wanted to be able to explore it to understand the interface that Tandy expected assembly language developers to use for accessing the disk files so that I could create a command shell that provides the same interface to the programs that it launches.”
– “Abraham Lincoln” on Facebook
Thank you for your service, Abraham! You can find the result of Abraham’s work, as well as progress on a new command line interface, on his GitHub page:
Abraham has also shown the beginning of a command line TRSDOS interface. I look forward to seeing how this turns out. Maybe we will end up with a “real” TRSDOS for the CoCo thanks to his efforts.
When the Insta360 X4 came out, it upgraded the recording format from 5.7K to 8K — basically a 4K image for each of the two lenses. When folks tried to upload these files to YouTube, apparently early on 8K would appear as a choice.
Then something happened.
For the past few years I have seen this topic come up time and time again in 360 forums on Facebook, REDDIT, etc. Folks cannot get their videos to show in 8K. Up to 4K is all it offers:
Time and time again, folks in the forum that got it to work just say “sometimes it takes awhile before it shows up.” However, the majority of us seemed to NEVER see this as an option, even months (or a year) later.
Recently, I began investigating this again. I label all my 8K videos as “8K” and it felt misleading to do so if no one could watch them in 8K.
Then I learned: YouTube used a different size for 8K, or so various “experts” claimed. Even though the Insta360 8K size of 7680×3840 worked fine as 8K in the past (for some), apparently now you had to resize the video to 7680×4320 and then and only then would YouTube show it as 8K. At least, according to many folks who were trying to make the work. Here is part of a detailed series of posts on REDDIT about this:
My attempts to do this did not produce 8K. Meanwhile, others still insisted that 8K “just worked” when directly uploading the file exported from Insta360 Studio (and, I would assume, the same size file from the DJI desktop app for the DJI Osmo 360 camera).
But not for most of us.
Does it work for anyone?
I ran into a YouTuber that was posting some 360-degree videos from amusement parks, and noticed they labeled them as 8K in their thumbnails. Yet, no 8K option when I viewed it. This led to a few exchanges in the comments, and them saying they could even see my videos show 8K.
I guess that 7680×4320 suggested by some was not important, after all… even though that is the resolution YouTube specifically mentions for 8K:
When the experts disagree, you know we don’t really know what the rules are.
So why is it so many of us cannot see 8K, and others can see it just fine? I was today years old when I actually saw an 8K option or the very first time:
And, then I checked using a different browser on a different operating system (Edge on a Windows 11 machine) and saw it there, too.
Did something get flipped?
Please let me know if you can see an 8K option on the following video — and if you can (or can’t), tell us your browser and operating system. The PC I used was just a low end DELL with no special graphics card, and I am seeing it on an M2 Mac even though I just found a new post saying you needed an M3 or above to see them.
No one seems to know the rules. But one of you may, so let us all know. Thanks!
Hat tip to L. Curtis Boyle for pointing this one out to me. Published in The World of ’68 Micros back in 1995 was an article by John “SockMaster’ Kowalski demonstrating how to do smooth horizontal scrolling on the CoCo 3 in the 320×200 16-color graphics mode.
In BASIC.
With no assembly.
You can find this demo in Volume 2, Number 5 in an article called “The Seven-line demo: an amazing achievement with DECB!” I must have been fully into OS-9 by this point since this article does not seem familiar to me. I was not really keeping up with any BASIC stuff by that point, having moved to OS-9 assembly and C programming.
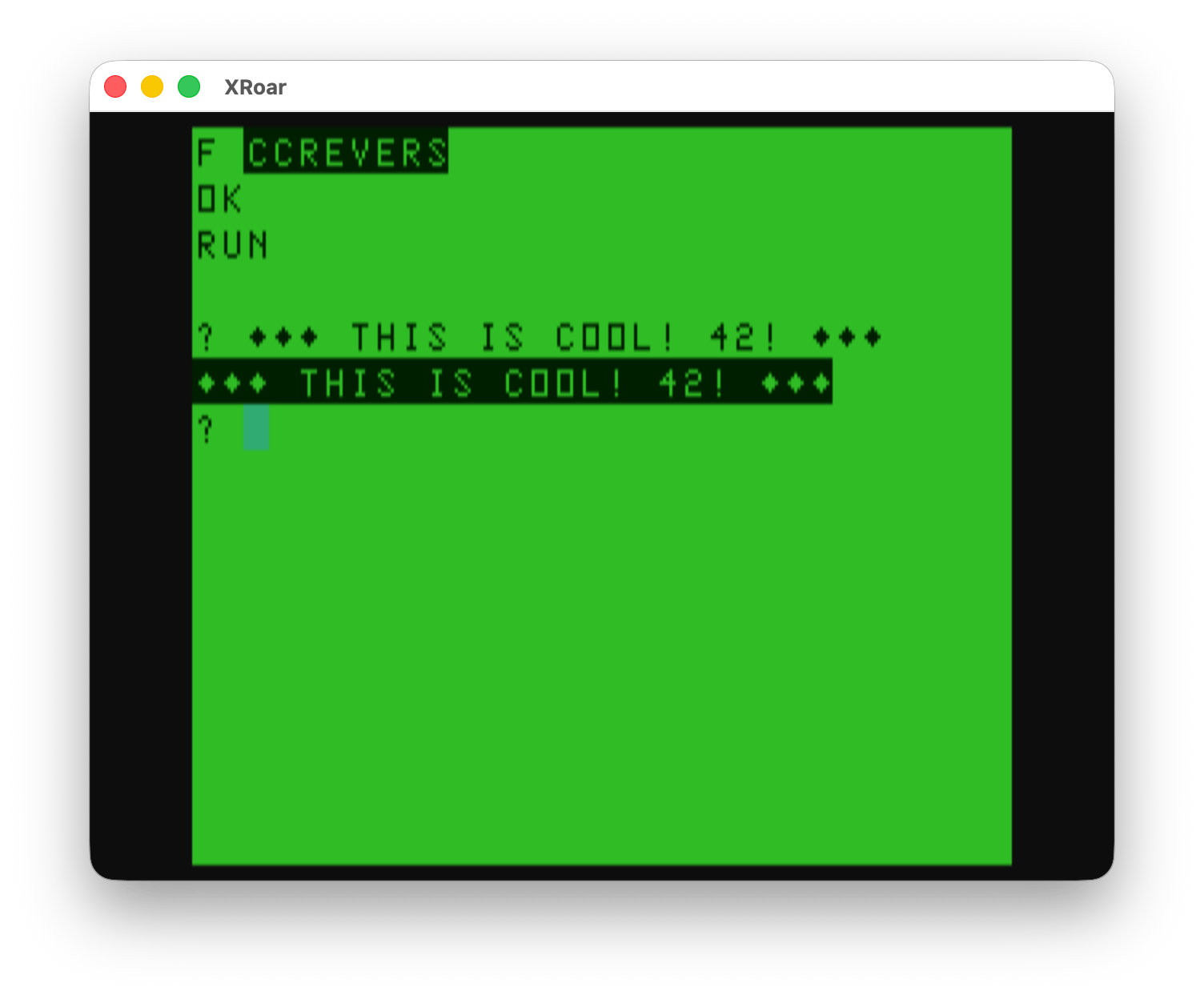
Here is that program as I typed it in and adjusted some spacing, with a few comments added by me. The only crucial part is line 70 which must have 11 colons and five spaces after that POKE Q,G line.
0 'The World of '68 Micros 1 'Volume 2, Issue 5 2 REM ** 2WAYSCRL.BAS 4 REM **bySockMaster 10 POKE 65497,0:HSCREEN 2:FOR G=0 TO 15:READ A:PALETTE G,A:NEXT 20 DATA 0,19,22,50,54,52,38,37,44,45,41,13,11,25,27,26 30 FOR G=0 TO 319 STEP .5:HSET(G,RND(191),RND(15)):NEXT 40 C=1:S=40:FOR G=15 TO 1 STEP-1:HCOLOR G 50 HCIRCLE(310-G*5,48),S:HPAINT(310-G*5,48):S=S-2.6:HLINE(RND(110)+210,RND(80)+104)-(RND(110)+210,RND(80)+104),PSET,BF:NEXT 60 Q=65439:W=0:E=127 65 '11 COLONS, 5 SPACES 70 FOR G=0 TO 127:PALETTE W,W:POKE Q,G::::::::::: POKE Q,E-G:NEXT:GOTO 70
I am unsure if the other spaces in line 70 are critical. The original listing looked like it had a lot of spaces between keywords and such, but that should not matter. LINE 70, being a loop, would be made a bit slower with extra spaces. Here is how it was presented in the magazine:
Here is what it does when ran in the XRoar emulator:
Spiffy!
Now I am off to read the full article to better understand how this works.
I sometimes see job listings for “embedded programmers,” but when I discover they are using an OS like Linux and a full file system, that does not quite seem “embedded” to me. I hardly consider a Raspberry Pi an “embedded” system. It is more like a desktop system that is small enough to embed.
See also: semantics, pedantic, and “pedantic a–holes” who love to comment about this stuff ;-)
But I digress.
Sometimes I find code in an open source project for an embedded target — such as an Arduino — that just screams “I don’t care about speed.” And, honestly, in most cases you really don’t. But why intentionally be slow?
I ran across a loop that searches for a target string in an index of strings. It was something like this:
int match (const char *name)
{
int index = -1; // Default to not found.
for (int idx = 0; idx < COUNT; idx++)
{
if (strncmp (array[idx], name, strlen (name)) == 0)
{
index = idx;
break;
}
}
return index;
}
The routine would accept a string and return the index of the first entry in an array that started with the same string. Here is a test program:
/******************************************************************************
Welcome to GDB Online.
GDB online is an online compiler and debugger tool for C, C++, Python, PHP, Ruby,
C#, OCaml, VB, Perl, Swift, Prolog, Javascript, Pascal, COBOL, HTML, CSS, JS
Code, Compile, Run and Debug online from anywhere in world.
*******************************************************************************/
#include <stdio.h>
#include <string.h>
#define COUNT 8
const char *array[COUNT] =
{
"bacon",
"eggs",
"eggs and jam",
"sausage",
"pancakes",
"waffles",
"toast",
"coffee"
};
int match (const char *name)
{
int index = -1; // Default to not found.
for (int idx = 0; idx < COUNT; idx++)
{
if (strncmp (array[idx], name, strlen (name)) == 0)
{
index = idx;
break;
}
}
return index;
}
int main()
{
int index;
index = match ("foo");
printf ("found at: %d", index);
return 0;
}
If the search target is not found, it returns -1. If the search target matched, it returns the index in the array where the match was found.
I noticed there were no NULL checks and it relied on a #define rather than calculating the array size. This was probably done because the author knew their code was perfect and did not need error checking.
Or maybe they just wanted to save a few lines and some code space.
But the part that bugged me was this:
if (strncmp (array[idx], name, strlen (name)) == 0)
The use of strncmp() each time a compare was done seemed … inefficient. If you had a list of 1000 items, and where looking for a string that was 42 characters long, you would be calculating the length of that string 1000 times by starting at the first byte and moving forward until you found the NULL character at the end. The longer your search string, the slower the search would be.
In these modern times, we don’t really care about things like this. It also might be more important to save a few bytes of code space than use a new variable and pre-calculate the string length.
But when I used this code, I changed it to something like:
int match (const char *name)
{
int index = -1; // Default to not found.
size_t length = strlen(name);
for (int idx = 0; idx < COUNT; idx++)
{
if (strncmp (array[idx], name, length) == 0)
{
index = idx;
break;
}
}
return index;
}
I can sleep better now that I know I saved valuable microseconds… ;-)
Exporting an 8K 360 video file that took 43 minutes on an M2 MacBook Air took about 31 minutes on an M4 Mac mini. That is “about 30%” faster, at least for the type of media I am working with.
2026-07-09 – details on the images that cause the problem.
2026-07-12 – “its too big” theory busted.
2026-07-13 – Alpha required!
UPDATE: After some testing, I can now make the export fail simply by exporting a 12001×12001 image (PNG, HEIF, TIFF) from Apple Preview and trying to use that in a simple 1080 FCP project. On the M2, it exports just fine. On M4, the export fails with no error, and a leftover temp file. Someone on Facebook tested this for me, and could replicate it on their M4, but found that using an image exported from a different tool worked. It may be an Apple Preview bug (creating a bad image) and some M4 difference in image handling that cause this issue. (Fails: Preview, Graphics Converter, Gimp. Works: Affinity Photo)
UPDATE 2: Thanks to more testing by others (see this Apple forum thread) we now know you can make 30000×30000 and it works just fine on the M4, so it is not related to size. And, you can make 12016×12016 and it works just fine, so it is more of a math thing. A posted in that thread also found a smaller image size that can create the problem. To me, it now looks like it is back to an FCP but rather than an underlying image processing bug since other tools (command line utilities, even Safari which should use the same rendering engine) and process the “bad” images just fine on the M4. Onward!
UPDATE 3: More from Apple’s forum — 8048×8065, 8048×8079, 8192×8193, and 8000×8321 are more examples that cause failures, and apparently only when there is an alpha channel (transparency). My logo is round, and used alpha transparency. Nice progress, joema!
While the recent Final Cut Pro 12.3 update seems to have fixed my recent crash problem when editing 360 video projects, I now find a new problem: I cannot export my projects on an M4 Mac mini, while they export just fine on an M2 MacBook Air.
I recently took on the task of taking a bunch of Macs from an office that is closing and getting them factory reset and ready to sell. Most of them were quite old – the oldest being a 2010 Mac mini (!) with 2 GB of RAM that was still being used as a daily desktop! I find it amazing how a 16 year old Mac can still be useful in a business environment.
Then I got to what must be their newest machine – a tiny Mac mini in a form factor I had never seen. (I have not followed Apple closely for many, many years.) This was the 2024 Mac mini with an M4 processor. It also had a 1TB SSD and 24GB of RAM.
I wondered… “how much faster would this be at exporting my Final Cut Video projects?”
I factory reset this M4 back to a generic install of the current macOS. I completed setup, making a new local account, and then logged in to my Apple Store account so I could download Final Cut Pro.
Nothing else is on the system. This is as basic and pristine as it gets.
For years I have done all my FCP editing on an external USB-C Sandisk drive. I connected that drive to this M4 and opened my most recent project. I clicked export and then it started … then stopped a second later. No error. No dialog box. Nothing. It just stopped. It left a weird named temporary mp4 file on the output location.
Odd. This project works fine on the M2.
I then went through the typical steps, copying the file to the local hard drive (NOT in an iCloud folder) and had the same issue. It will start to export, then just stop a few seconds later.
Lather, rinse, repeat. File Access, Full Disk Access, etc., etc. where checked. And, like the bug in the previous FCP, normal non-360 projects opened and exported just fine. Yet, all the projects I spot checked that work fine on my M2 where not exporting on this M4.
I have an open case with Apple Support about this, and the best we figured out during a remote diagnosing session was that a PNG file I have — which I have used for years — seems to cause the problem. Remove it and it exports. Add it back and it does not. Yet, that same PNG exports in a non-360 just fine. And, it works fine not he M2.
Very weird bug. Anyway, I am just posting this here to get it in the search engines. When I learn more, I will update this with a solution in case anyone else runs into this.
You will find dozens … hundreds … thousands (?) of programs there for the Radio Shack TRS-80 MC-10 computer, as well as the Color Computer. I believe he is by far the most prolific programmer in our community.
Recently, he shared a video on his YouTube channel of a 1979 Star Trek game he ported to the MC-10:
I am always fascinated at his porting efforts. He has done some amazing arcade conversions scaled down to fit the 32×16 text screen (ahem, 64×32 “graphical” blocks).
What caught my attention on this one was how he prints out the header row and column:
The Motorola MC6847 VDG chip used by the MC-10 and the Color Computer had a limited font of uppercase letters and numbers, with no lowercase versions. Instead of lowercase, the VDG contained the same set of characters but in reverse mode. I’ve posted about this in the past:
Now, I knew that the Micro Color BASIC of the MC-10 had some extra features we never got on Color BASIC for the CoCo. The MC-10 keyboard had the 2×2 graphic block characters by the keys, and you could type them with the keyboard. Here is what the MC-10 keyboard looks like, via an image from the online MC-10 emulator:
I believe SHIFT+LETTER would produce that graphical block. To change the colors, CONTROL-0 would toggle through them. This allowed you to embed these colorful block characters in a PRINT statement or string. Nice!
Heck, the CoCo didn’t even HAVE a Control key until the CoCo 3 came out in 1986, and our “Super” Extended Color BASIC did nothing with the extra keys they added.
But I digress.
I thought maybe there was some way to type reverse video directly from the keyboard. On the CoCo and MC-10, SHIFT-0 toggles between UPPERCASE and lowercase (which is represented by reverse video). BUT, spaces, numbers, and special characters still print normally. It is a “lowercase” mode, after all, and there is no such thing as a lowercase 7.
I left a comment to the video, asking how this is done. Jim responded with this:
It appears to be a custom display routine that will take what is in M$ and POKE the values to the screen in inverted format. I expected the 136 and 137 locations had something to do with screen cursor position. I headed over to Color BASIC Unravelled to take a look…
136 is 0x88 in hex (eh, &H88 to Extended BASIC), so I searched for that in the book’s memory map and confirmed:
LINE 0 – Pre-allocated variables C1, C2 and M$. BASIC will dynamically allocate variables when they are first used, but you can use DIM to allocate them ahead of time, and in the order you specify. Variables at the start of the variable table are found quicker than variables at the end because BASIC has to scan through table to find the variable each time it is used. M points to the start of the text screen on the MC-10 (that would be 1024 for the CoCo). GOTO10 would be replaced by whatever line number is the program startup/initialization. Jim is very aware of how the BASIC interpreters work, so he puts his subroutines at the top of the pgoram. Anywhere you are in the program, whether that is line 100 or line 63000, GOSUB 7 will be able to find that routine by only having to skip through any lines from 0-6 to get there. Sadly, we learned to put subroutines at the end of our programs, so every GOSUB had to scan forward through every line until it found the subroutine line.
LINE 10 – Skipping ahead, this is the “program” for this example. PRINT to skip a line, then INPUT to input a string, then a GOSUB 7 to display that string, and GOTO 10 to repeat.
LINE 7 – Now the fun begins. C1 is … uh … okay, let’s take a quick break.
In Jim’s YouTube comment, he mentioned that 136/137 are the CoCo values, and 17024/17025 were the MC-10 values. These correspond to the 16-bit value stored there, which represents where in memory the cursor currently is. On a CoCo, if you use CLS to clear the screen and home the cursor, that position will be 1024. Let’s see if that matches:
CLS:PRINT PEEK(136)*256+PEEK(137) 1024 OK
Checks out. On the MC-10, that would be “CLS:PRINT PEEK(17024)*256+PEEK(17025)” and that will display 16384 – the start of the MC-10s text screen in memory.
So far so good. Jim’s code starts out by getting those two values and adding 16383 to them for some reason. He also does an “AND 1” to the first peek, which should mask off all the bits in that 8-bit value except for the first one, meaning it should be either a 1 or a 0. But why?
On the MC-10, when the cursor is at the top left of the screen, 17024 and 17025 should represent 16384. That would be 64*256+0. As the cursor moves forward, that second value goes from 0 to 255, halfway in to the screen memory. Then, that second number flips back to zero and the first number goes up by one.
The first half of the screen is 64*256+(0 to 255) then the second half is 65*256+(0 to 255). This program will poke an orange block to the first byte of the screen, and the last byte:
But Jim is doing something with that “AND 1”. 64 AND 1 is 1, since bit 0 is set. 65 AND 1 is zero, since bit 0 is clear for an odd number. Thus, his code is using 0 for the first half of the screen, and 1 for the second half, so he adds 16383 to the value which puts it back into the screen memory range of 16384 to 16895.
But why? If Jim is doing this, there has to be a reason. I wrote this test to find out.
0 REM MC-10 REVERSE1.BAS 10 FOR P=0 TO 510 20 CLS:PRINT@P,".";:PRINT@P,; 30 L=PEEK(17024)*256+PEEK(17025) 40 PRINT@500,L; 50 IF INKEY$="" THEN 50 60 NEXT
This will clear the screen, print a dot at a position, then move the cursor position back to where the dot is. This lets me “see” where the location is. It then PEEKs to get the current cursor position, and prints it on the bottom row. Hit a key, then it repeats. You can see the dot walk across the screen as the value at the bottom increases.
Okay.
Modifying the program to use the AND 1 would look like this:
0 REM MC-10 REVERSE2.BAS 10 FOR P=0 TO 510 20 CLS:PRINT@P,".";:PRINT@P,; 30 L=(PEEK(17024)AND1)*256+PEEK(17025)+16383 40 PRINT@500,L; 50 IF INKEY$="" THEN 50 60 NEXT
And running that looks … the same.
And that’s when I realized what this code does! The AND 1 makes it return values 0-511 for the curious position — the PRINT@ locations. He must use this code with AND 1 (without the +16383) when he is using PRINT@. If he wanted the POKE location, he would leave out the AND 1 and the +16383, and just have the POKE positions.
I feel dumb that I did not realize it. But this was fun anyway. This may be the first MC-10 program I have ever written.
Moving back to the code…
LINE 10
C1 is set to the memory location of the current cursor position.
C2 is then used as a loop from 1 to the length of the M$ to display.
POKE C1 (current cursor position) plus C2 makes the POKE location move forward with the loop.
For what to POKE, he uses ASC to get the ASCII value of the corresponding character in the string. He is using a trick here. We all learned MID$(A$,5,1) to get the 1 character at position 5. But if you leave off that third parameter, it will return a new string that starts at position 5 and goes to the end of the string, the same as a RIGHT$ would do. But ASC doesn’t care. If you ASC(“HELLO”) it gives you ASCII of the first character, “H”. A nice shortcut.
After this, that ASCII value is AND 63 which masks off higher bits, to the value will be 0-63. And if you POKE those values to the screen, you get reversed video. That is the trick to how this works.
After that is a PRINT@ to move the cursor to where the new position should be (POKEing bytes to the screen bypasses BASIC so the cursor would still be where it was). Even though C1 is a screen POKE location, M was the start of the screen, so he can subtract that to turn it back into a PRINT@ location.
Yesterday my news alerts showed me a posting where someone shared screenshots of registrations for the Insta360 X6. There have been rumors of the X6 since (and maybe even before) the moment the X5 model was released.
Beyond adding higher resolution and/or better low light performance, what else would justify someone upgrading from the X5? Rumors are saying this model could have a 1″ lens — something Insta360 already had years ago with the Insta360 ONE RS. That model had 6K resolution (3K per lens) which was resolution worse than the later X4 and X5 “8K” models but the larger sense allowed it to capture better images even if at a lower resolution.
Just keep in mind — there is “what the camera can do” versus “what the camera operator can do.” Someone can take a mediocre camera, play with manual settings, and post-process the image to create something that looks much better than anything you can get from a “better” camera just by pressing the button in automatic mode.
I have mostly been a point-and-shoot user since I got my first digital camera in 1996, so “what the camera can do” is usually more important to me than what some advanced photographer can do with it.
An important reminder:
Be careful trusting an honest review if they don’t disclose they have a hardware sponsor providing them with hundreds or thousands of dollars worth of product to “review”. That, in itself, is dishonest, so how can you trust the rest?
Now we wait for hundreds of vloggers and bloggers to churn endlessly over the same rumors, adding nothing useful except regurgitation.
In 1995, I signed up with an e-mail forwarding service called pobox.com. They would give you e-mail aliases that would then forward to whatever real e-mail account you were using at the time. The basic plan came with three aliases, and at one point I was using six. Super convienient!
They also added the ability to use those aliases to redirect to a webpage. Back then, your web address might be something long like www.geocities.com/SiliconValley/1842 (my original home page at GeoPages) or be something with a “~” in it like http://www.mcs.net/~werner/yester.html (the original location of www.yesterland.com before it had a domain). Pobox allows aliasing those so users only had to know www.pobox.com/~disneyparks and it would redirect to whatever service I was using to host my theme park photos at the time. Super convenient!
Over the years, my e-mail has moved from service to service to service, yet I never had to change any e-mail addresses with any services, or notify any of my contacts about a new address. They just used the same e-mail address I had since 1995. Super convenient!
The way they handle spam filtering is much worse (no e-mail summary, no one-click way to look at items in a web page and release/white list them, etc.). E-mails from my Softaculus (WordPress) service ALWAYS get spam filtered and they have been unable to fix this. E-mails I send to folks bounce back at the Fastmail level due to reasons I haven’t figured out. It’s a mess.
So, while I told everyone about how great POBOX.COM was for 30 years… I cannot recommend FASTMAIL.COM
But they own the e-mail I have had since 1995 so I guess I am sticking with them. At least for now…