

See Also: part 1, part 2, part 3, part 4 and part 5.
A maze of ideas
Ready to fall down a rabbit hole, exploring ways to represent a maze screen efficiently?
Neither was I.
Somewhere on this site is an article series I wrote about programming a simple maze type game on the CoCo. In it, I presented an ASCII version of the Pac-Man maze. The arcade maze looks like this:

And you can learn a ton about how the game works on the Pac-Man Dosier website. But basically, the game screen is a grid of 28 x 36 tiles. In the arcade original, each tile is 8×8 pixels. With the CoCo 1/2s text screen being 32×16, this means we could fit 28 tiles horizontally with room to space, but we’d be 20 tiles short vertically. (Pac-Man used a monitor mounted sideways to get this aspect ratio.) My solution was to scroll the maze up and down. I also removed the top and bottom rows that showed score and such, so this will be using only 31 of the games original 36 rows.
A portion displayed in ASCII text would look like this:
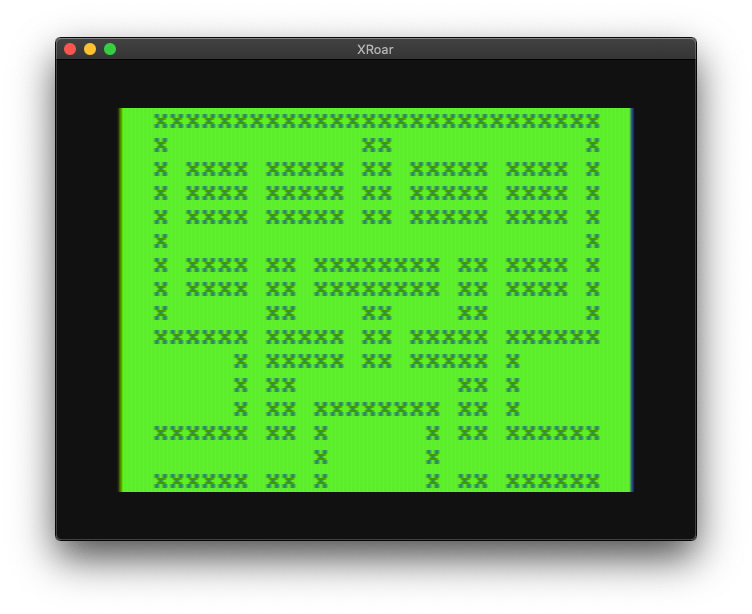
Though it wouldn’t look like the arcade, this is an accurate representation of the 28×36 tiles of the original game (well, 28×16 seen any any time). There are elements of Pac-Man that couldn’t really be recreated with this low resolution (such as the way Pac can hug to corners to go around them faster), but at least the maze layout could be accurate.
But ASCII is ugly, so we’d probably want to use the semigraphics characters (128-255). Using CHR$(175) for a blue block looks like this:

That’s better, but still a bit ugly. The background could at least be made black:

That’s more better, but it looks more reminiscent of blocky Atari VCS games like Adventure.
By taking advantage of the 64×32 resolution semigraphics, the corners could be at least “rounded” a bit (if round meant “still square”), and the centers of the areas could be opened up like the arcade original:

At this resolution, I’m not sure if we can really do any better than that ;-)
The maze data could be represented as ASCII strings, either directly PRINTed on the screen, or read from DATA statements to be PRINTed or POKEd:
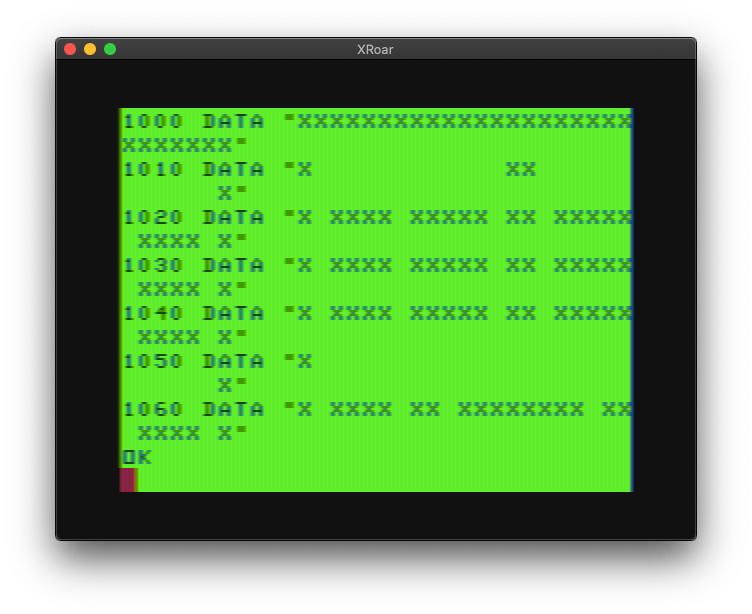
This would make creating new mazes and levels as easy as typing. But storing 28 x 26 characters is 1008 bytes of memory. Imagine trying to do that on a 4K Color Computer or a 5K Commodore VIC-20. (The highest resolution graphics screen on a CoCo 1/2 takes up 6144 bytes, compared to the 512 bytes of the text screen.)
Here’s the ASCII DATA:
1000 DATA "XXXXXXXXXXXXXXXXXXXXXXXXXXXX" 1010 DATA "X XX X" 1020 DATA "X XXXX XXXXX XX XXXXX XXXX X" 1030 DATA "X XXXX XXXXX XX XXXXX XXXX X" 1040 DATA "X XXXX XXXXX XX XXXXX XXXX X" 1050 DATA "X X" 1060 DATA "X XXXX XX XXXXXXXX XX XXXX X" 1070 DATA "X XXXX XX XXXXXXXX XX XXXX X" 1080 DATA "X XX XX XX X" 1090 DATA "XXXXXX XXXXX XX XXXXX XXXXXX" 1100 DATA " X XXXXX XX XXXXX X " 1110 DATA " X XX XX X " 1120 DATA " X XX XXXXXXXX XX X " 1130 DATA "XXXXXX XX X X XX XXXXXX" 1140 DATA " X X " 1150 DATA "XXXXXX XX X X XX XXXXXX" 1160 DATA " X XX XXXXXXXX XX X " 1170 DATA " X XX XX X " 1180 DATA " X XX XXXXXXXX XX X " 1190 DATA "XXXXXX XX XXXXXXXX XX XXXXXX" 1200 DATA "X XX X" 1210 DATA "X XXXX XXXXX XX XXXXX XXXX X" 1220 DATA "X XXXX XXXXX XX XXXXX XXXX X" 1230 DATA "X XX XX X" 1240 DATA "XXX XX XX XXXXXXXX XX XX XXX" 1250 DATA "XXX XX XX XXXXXXXX XX XX XXX" 1260 DATA "X XX XX XX X" 1270 DATA "X XXXXXXXXXX XX XXXXXXXXXX X" 1280 DATA "X XXXXXXXXXX XX XXXXXXXXXX X" 1290 DATA "X X" 1300 DATA "XXXXXXXXXXXXXXXXXXXXXXXXXXXX"
If we tried to use numeric DATA statements to represent the screen blocks, it would be 4 times longer since every entry would be a three digit number with a comma:
DATA 175,175,175,175,175,175,175,175,175,175,175,175,175,175,175,175,175,175,175,175,175,175,175
But, if we were just using blocks and spaces, we could have a number represent eight of them. Each number could represent a byte (0-255) and each byte contains 8 bits, therefore each number could represent 8 character blocks.
In a DATA statement with numbers, the top row would look like:
1000 DATA 255,255,255,240
The storage space for “255,255,255,240” is 15 bytes which is less than the 28 string characters (plus quotes, if needed — like if the line started with spaces or had special characters in it like a comma or ‘ REM abbreviation, which this won’t).
I suppose we could use numbers representing 16-bit values (0-65535) and have only two numbers to represent that line:
1000 DATA 65535,65520
That brings us down to 11 bytes to represent the 28 block row.
The 4K CoCo BASIC did not have hexadecimal numbers, but on Extended BASIC machines we could convert to HEX:
1000 DATA &HFF,&HFF,&HFF,&HF0
…but that is 19 bytes. While that would be better than ASCII, it would be worse than two decimal values. Doubling up to 16 bit values results in:
1000 DATA &HFFFF,&HFFF0
That gets us down to 12 bytes so it looks like needing that &H at the start loses out — 65535 versus &HFFFF. Even worse when 1 has to be three times larger as &H1. Though 15 is only one by larger as &HF. But always larger.
Hex values could be written as a string without the &H, and that could be added by the READ routine:
1000 DATA FF,FF,FF,F0
…which gives us 11 bytes, matching the two decimal values. But reading those would require some extra code which might negate the savings:
READ A$:V=VAL("&H"+A$)
…versus just reading a decimal value…
READ V
Using hex without the “&H” requires an extra 15 bytes of code space (actually, maybe a little less, since the “VAL” keyword probably tokenizes in to one or two bytes).
But, we could also pack the hex values together:
1000 DATA FFFFFFF0
That would only take 8 bytes to represent a row. But even more code would be needed to parse that:
READ A$:FOR A=1 TO LEN(A$) STEP 2:V=VAL("&H"+MID$(A$,A,2)):NEXT
The code gets even longer. However, if we had enough data (and 36 rows of data probably is enough), the code space savings should be smaller overall. And clever programming could be done to have one massive hex string and decode it knowing how many bytes go to each line.
But this only gets us to displaying the maze in ASCII or as colored blocks. If we wanted to get that “rounded” corner look of a 64×32 display, we’d need twice as many bytes.
Or we could just make the computer do it for us.
To be continued…