See also: part 1, part 2, part 3, part 4, part 5, part 6 and part 7.
The story so far…
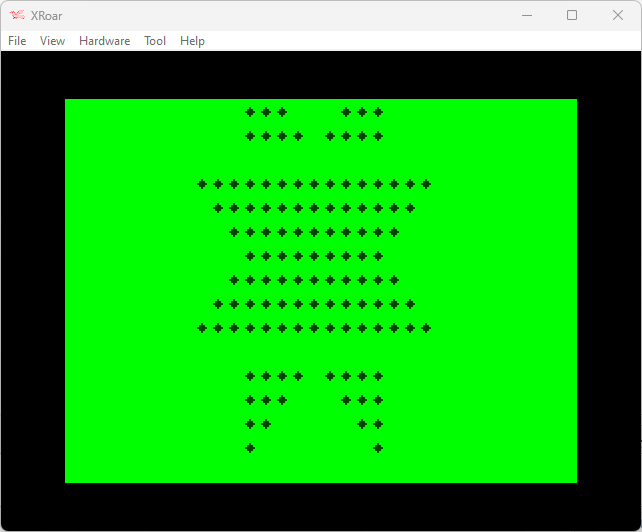
In the beginning Logiker offered up a programming challenge to produce this simple image:

From its humble beginnings as a bunch of PRINT statements, to a DATA driven output routine, we have now ended up with code that can print the top half of the symmetrical image by only having data to describe one quarter of the image.
When we last left off, I had code that would read this data, print the left half, then print the right half, mirroring the same data. It worked well, but only printed the top half of the image.

I showed that code to OpenAI and asked how it would accomplish the task of reversing the data to print the bottom portion:
To make the program print the rows in reverse order after it has finished printing all of the rows, you will need to make some changes to the code. One way to do this would be to add another loop after the main loop that reads the data from the DATA statements and prints the rows in reverse order. You can use the “REVERSE” statement in BASIC to reverse the order of the rows in the DATA statements, and then use the same code as in the main loop to read the data and print the rows. This will cause the program to print the rows in the original order, and then again in reverse order.
– chat.openai.com
I’ve never heard of the REVERSE keyword, and the CoCo’s BASIC doesn’t have it. But if I did have it, this task would be pretty easy. I informed the A.I. that I had no such command, and it said:
If your BASIC does not have a REVERSE command, you can still print the rows in reverse order by using a different approach. One way to do this would be to store the data from the DATA statements in an array, and then loop through the array in reverse order to print the rows. In BASIC, you can use the “DIM” statement to create an array, and the “READ” statement to read data from the DATA statements into the array. You can then use a loop to iterate through the array in reverse order, using the same code as in the main loop to print the rows. This will cause the program to print the rows in the original order, and then again in reverse order.
– chat.openai.com
That’s the approach I was thinking of taking, so… okay!
Side Note: I did ask the A.I. to modify my program to do this, and it gave me something that would have been a good starting point for the rest of this article. I could have then discussed things with the A.I. a bit more and encouraged it to evolve the program until it met the requirements. (One issue with BASIC is that the A.I. inevitably tries to do things from other dialects of BASIC that Color BASIC does not have, such as the REVERSE command.) I hope to demonstrate one of these co-programming sessions in a future article series, provided access to ChatGPT remains available to me.
I changed my routine so it loaded all the DATA values in to a dimension. Since I knew how many entries there would be (27), I could eliminate the need for having a -1 to mark the end of data.
Then, in the PRINT routine, instead READing A, B and C and looking at them, I’d use the D() dimension variable as D(x), D(x+1) and D(x+2) to get to the same three values.
At the end of each line (three numbers, or two numbers followed by a zero), I would increment my index by three so it starts at the next set of numbers in the array.
I used a new variable, M, to indicate the mode (forward or reverse). When it reaches the end of the data (D goes past the 27 entries), it sets that variable to 1, and other code now runs decrementing the index by 3 each time until it reaches the top (0).
Here is my new code:
0 ' LOGIKER11.BAS
10 CLS:DIM D(26)
11 FOR I=0 TO 26:READ D(I):NEXT:D=0:M=0
15 PRINTTAB(6);
20 PRINT STRING$(D(D),32);
25 IF D(D+2)=0 THEN PRINT STRING$(D(D+1)*2-1,42);STRING$(D(D),32);:GOTO 40
30 PRINT STRING$(D(D+1),42);STRING$(D(D+2)*2-1,32);STRING$(D(D+1),42);
40 IF M=0 THEN D=D+3:IF D<27 THEN PRINT:GOTO 15 ELSE M=1
41 IF D>0 THEN PRINT:D=D-3:GOTO 15
50 DATA 5,1,4
60 DATA 5,2,3
70 DATA 5,3,2
80 DATA 5,4,1
90 DATA 1,9,0
100 DATA 2,8,0
110 DATA 3,7,0
120 DATA 4,6,0
130 DATA 5,5,0
220 GOTO 220OpenAI describes it as follows:
This program is similar to the previous ones, but it uses a slightly different approach to read the data from the DATA statements and print the rows. The program starts by defining an array
Dto store the data from the DATA statements, and then reads the data into the array. The program then enters a loop that prints the rows of the pattern. In each iteration of the loop, the program prints a row of the pattern by printing a string of spaces, followed by a string of asterisks, and then another string of spaces. The number of spaces and asterisks in each string is determined by the data in the array.After the program has printed all of the rows in the original order, it enters another loop that prints the rows in reverse order. In each iteration of the loop, the program prints the same row as in the previous loop, but in reverse order. This causes the program to print the rows of the pattern in the original order, and then again in reverse order. However, without more information about the data in the DATA statements, it is not possible to say exactly what the output of the program would look like.
– chat.openai.com
Nicely done, A.I.
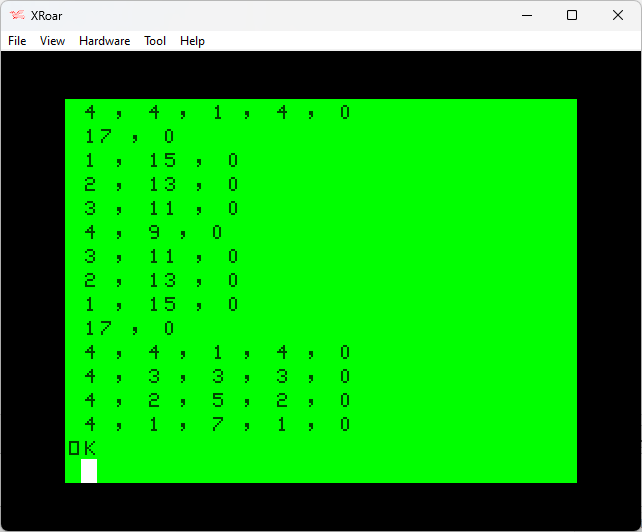
When I run this program, I get the desired output!
It is, of course, slower than the original brute-force PRINT version. But, we are going for size. And speaking of size, lets try to pack this down as much as possible and see where we stand:
0 ' LOGIKER12.BAS
10 CLS:DIM D(26):FOR I=0 TO 26:READ D(I):NEXT:D=0:M=0
15 PRINTTAB(6);STRING$(D(D),32);:IF D(D+2)=0 THEN PRINT STRING$(D(D+1)*2-1,42);STRING$(D(D),32);:GOTO 40
30 PRINT STRING$(D(D+1),42);STRING$(D(D+2)*2-1,32);STRING$(D(D+1),42);
40 IF M=0 THEN D=D+3:IF D<27 THEN PRINT:GOTO 15 ELSE M=1
41 IF D>0 THEN PRINT:D=D-3:GOTO 15
50 GOTO 50:DATA 5,1,4,5,2,3,5,3,2,5,4,1,1,9,0,2,8,0,3,7,0,4,6,0,5,5,0Loading the first version gives me 22431 bytes free. Loading the second gives me 22499 – about 68 bytes smaller! Compare that to the original brute-force PRINT version (which was 22309 free), we have saved 190 bytes so far.
And, we could remove spaces, get rid of the REM comment at the start, and save even more.
But is that enough for the challenge? One thing the challenge says it you are not required to clear the screen, and you can return to an OK/Ready prompt. That means I could remove the CLS and the GOTO loop at the end, saving even more.
But saving even more is not enough. I think there’s a few more things we can do, especially now that I understand what it takes to draw this shape.
Until next time, take a look at what I have done in LOGIKER11.BAS and see what suggestions you can come up with.