See also: part 1, part 2, part 3, part 4, part 5, part 6 and part 7.
The challenge continues. From humble beginnings of using PRINT, to fancier methods of encoding the image as a series of spaces and asterisks, we eventually ended up with an even fancier method that used only 1/4 of the image data to represent the entire symmetrical image.
That approach could work for any image that is symmetrical vertically and horizontally, and typically general purpose routines are not as small as custom routines that know what they will be doing.
Knowing what we now know…
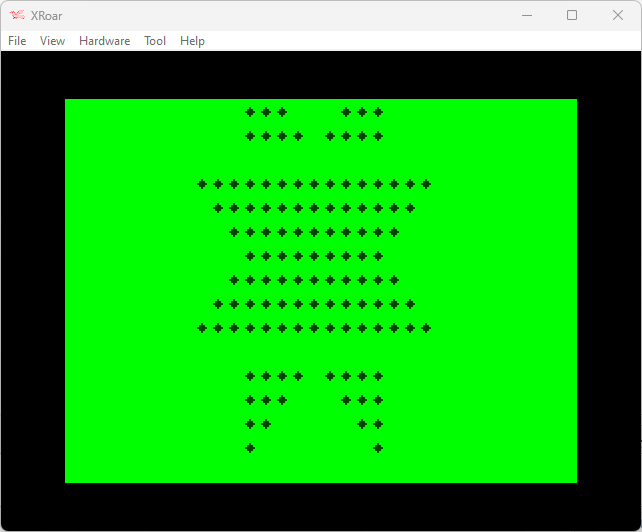
WIth that said, looking at this image, there is another shortcut that I missed:

The entire image is centered over one column… This means the amount of spaces on the left is unimportant — we just need to center the following lines:
* * ** ** *** *** **** **** ***************** *************** ************* *********** ********* *********** ************* *************** ***************** **** **** *** *** ** ** * *
And, since we know it’s symmetrical both vertically and horizontally, we really only need to worry about this:
* | <- 1 asterisk, 4 spaces ** | <- 2 asterisks, 3 spaces *** | <- 3 asterisks, 2 space **** | <- 4 asterisks, 1 space *****************| 17 ***************| 15 *************| 13 ***********| 11 *********| 9
I’m not sure what the pattern is as I type this, but I am expecting there is one. Here is a quick program that prints the rows of the shape using FOR/NEXT loops (uncentered):
0 ' LOGIKER13.BAS
10 FOR I=1 TO 4
20 PRINT STRING$(I,"*");STRING$(1+(4-I)*2," ");STRING$(I,"*")
30 NEXT
40 FOR I=17 TO 9 STEP-2
50 PRINT STRING$(I,"*")
60 NEXT
70 FOR I=11 TO 17 STEP 2
80 PRINT STRING$(I,"*")
90 NEXT
100 FOR I=4 TO 1 STEP-1
110 PRINT STRING$(I,"*");STRING$(1+(4-I)*2," ");STRING$(I,"*")
120 NEXTIf each of those lines were centered, we’d have our shape. Let’s try that by creating a string for the row, and then using the LEN() of that string to know how to center it using TAB().
0 ' LOGIKER14.BAS
10 FOR I=1 TO 4
20 A$=STRING$(I,"*")+STRING$(1+(4-I)*2," ")+STRING$(I,"*")
25 PRINT TAB(16-LEN(A$)/2);A$
30 NEXT
40 FOR I=17 TO 9 STEP-2
50 A$=STRING$(I,"*")
55 PRINT TAB(16-LEN(A$)/2);A$
60 NEXT
70 FOR I=11 TO 17 STEP 2
80 A$=STRING$(I,"*")
85 PRINT TAB(16-LEN(A$)/2);A$
90 NEXT
100 FOR I=4 TO 1 STEP-1
110 A$=STRING$(I,"*")+STRING$(1+(4-I)*2," ")+STRING$(I,"*")
115 PRINT TAB(16-LEN(A$)/2);A$
120 NEXT
130 GOTO 130That produces our desired shape (though it does leave a blank line at the end, which our original version avoided by having a semi-colon on the PRINT and just breaking lines when we went to the next one).
The first thing I see it that the centering code on line 25, 55, 85 and 115 is the same. Subroutine!
0 ' LOGIKER15.BAS
10 FOR I=1 TO 4
20 A$=STRING$(I,"*")+STRING$(1+(4-I)*2," ")+STRING$(I,"*")
25 GOSUB 150
30 NEXT
40 FOR I=17 TO 9 STEP-2
50 A$=STRING$(I,"*")
55 GOSUB 150
60 NEXT
70 FOR I=11 TO 17 STEP 2
80 A$=STRING$(I,"*")
85 GOSUB 150
90 NEXT
100 FOR I=4 TO 1 STEP-1
110 A$=STRING$(I,"*")+STRING$(1+(4-I)*2," ")+STRING$(I,"*")
115 GOSUB 150
120 NEXT
130 GOTO 130
150 PRINT TAB(16-LEN(A$)/2);A$:RETURNNext, we see that the string building code for the top and bottom are the same, so 20 and 110 are the same (it’s the value of I that changes how it prints), and then 50 and 80 are the same. Subroutines!
0 ' LOGIKER16.BAS
10 FOR I=1 TO 4
20 GOSUB 200
25 GOSUB 150
30 NEXT
40 FOR I=17 TO 9 STEP-2
50 GOSUB 250
55 GOSUB 150
60 NEXT
70 FOR I=11 TO 17 STEP 2
80 GOSUB 250
85 GOSUB 150
90 NEXT
100 FOR I=4 TO 1 STEP-1
110 GOSUB 200
115 GOSUB 150
120 NEXT
130 GOTO 130
150 PRINT TAB(16-LEN(A$)/2);A$:RETURN
200 A$=STRING$(I,"*")+STRING$(1+(4-I)*2," ")+STRING$(I,"*"):RETURN
250 A$=STRING$(I,"*"):RETURNNext, I notice the subroutines of 200 and 250 both have the centering PRINT called after them, so maybe we change it up a bit…
0 ' LOGIKER17.BAS
10 FOR I=1 TO 4
20 GOSUB 200
30 NEXT
40 FOR I=17 TO 9 STEP-2
50 GOSUB 250
60 NEXT
70 FOR I=11 TO 17 STEP 2
80 GOSUB 250
90 NEXT
100 FOR I=4 TO 1 STEP-1
110 GOSUB 200
120 NEXT
130 GOTO 130
200 A$=STRING$(I,"*")+STRING$(1+(4-I)*2," ")+STRING$(I,"*"):GOTO 300
250 A$=STRING$(I,"*")
300 PRINT TAB(16-LEN(A$)/2);A$:RETURNWhat else? The FOR/NEXT loops are basically all the same, except for the start and end value and the step value… Maybe we could come up with a way to have only one, and feed it those values using DATA statements?
10 FOR I=1 TO 4 ... 40 FOR I=17 TO 9 STEP-2 ... 70 FOR I=11 TO 17 STEP 2 ... 100 FOR I=4 TO 1 STEP-1 500 DATA 1,4,1 510 DATA 17,9,-2 520 DATA 11,17,2 530 DATA 4,1,-1
If they all went to the same GOSUB routine this would be easy, but they don’t. The go 200, 250, 250, 200. We could add a fourth element in the DATA that tells it which routine to go to and “IF X=1 THEN GOSUB Y ELSE GOSUB Z” or something. That adds more code. Perhaps we don’t need the DATA since we know it alternates? Still, we’d have to track it ourselves with an IF or something. For now, let’s just try this:
0 ' LOGIKER18.BAS
10 FOR J=1 TO 4
20 READ A,B,C,D
30 FOR I=A TO B STEP C
40 IF D=0 THEN GOSUB 200 ELSE GOSUB 250
50 NEXT I
60 NEXT J
70 GOTO 70
200 A$=STRING$(I,"*")+STRING$(1+(4-I)*2," ")+STRING$(I,"*"):GOTO 300
250 A$=STRING$(I,"*")
300 PRINT TAB(16-LEN(A$)/2);A$:RETURN
500 DATA 1,4,1,0
510 DATA 17,9,-2,1
520 DATA 11,17,2,1
530 DATA 4,1,-1,0And that still produces your original shape. But is it any smaller?
In part 4, we had a version that (using my default XRoar emulator running DISK EXTENDED COLOR BASIC) showed 22499 bytes free after loading. This new version shows 22567 bytes free. So yes, it is smaller! And, we can pack those lines and make it even smaller than that. (And NEXT doesn’t near the variable — in fact, using “NEXT I” is slower than just saying “NEXT” so I’ll remove those here as well.)
0 ' LOGIKER19.BAS
10 FOR J=1 TO 4:READ A,B,C,D:FOR I=A TO B STEP C:IF D=0 THEN GOSUB 200 ELSE GOSUB 250
50 NEXT:NEXT
70 GOTO 70
200 A$=STRING$(I,"*")+STRING$(1+(4-I)*2," ")+STRING$(I,"*"):GOTO 300
250 A$=STRING$(I,"*")
300 PRINT TAB(16-LEN(A$)/2);A$:RETURN:DATA 1,4,1,0,17,9,-2,1,11,17,2,1,4,1,-1,0That version shows me 22609 free, which is even smaller — and we could still make this a bit smaller by getting rid of unnecessary spaces in the code.
Side note: I am being lazy and just showing the BASIC “PRINT MEM” values rather than calculating the actual size of the program. On my configuration, 22823 is how much memory is there on startup. So, 22823-22609 shows that this program is 214 bytes. It uses more memory for the strings when running, but I don’t think that matters for this challenge.
What else can we do to save a few bytes? Well, STRING$() takes two parameters. The first is the count of how many times to repeat the second parameter. The second parameter can be a quoted character like “*”, or a number like 42 (the ASCII value of the asterisk). 42 is one by smaller than “*” so we can do that as well as use 32 (the ASCII value for space) instead of ” “:
200 A$=STRING$(I,42)+STRING$(1+(4-I)*2,32)+STRING$(I,42):GOTO 300
250 A$=STRING$(I,42)Another thing we know is that in the shape there are always the same number of spaces before the top and bottom sections, so we really don’t need to center it. We could just hard code a PRINT TAB for that instead of building a string and calling a center subroutine:
200 PRINT TAB(11);STRING$(I,42);STRING$(1+(4-I)*2,32);STRING$(I,42)
210 RETURNThe middle section is similar. Since we know the length, we could calculate how many spaces to tab using that number:
250 PRINT TAB(16-I/2);STRING$(I,42)
260 RETURNAnd that removes a subroutine, leaving us with this (not line packed yet):
0 ' LOGIKER20.BAS
10 FOR J=1 TO 4
20 READ A,B,C,D
30 FOR I=A TO B STEP C
40 IF D=0 THEN GOSUB 200 ELSE GOSUB 250
50 NEXT
60 NEXT
70 GOTO 70
200 PRINT TAB(11);STRING$(I,42);STRING$(1+(4-I)*2,32);STRING$(I,42)
210 RETURN
250 PRINT TAB(16-I/2);STRING$(I,42)
260 RETURN
500 DATA 1,4,1,0
510 DATA 17,9,-2,1
520 DATA 11,17,2,1
530 DATA 4,1,-1,0Two FOR/NEXT loops, a READ, an IF, and two PRINT subroutines.
Maybe we don’t need those subroutines, now that we have an “IF” in line 40 that decides what to do?
0 ' LOGIKER21.BAS
10 FOR J=1 TO 4
20 READ A,B,C,D
30 FOR I=A TO B STEP C
40 IF D=0 THEN PRINT TAB(11);STRING$(I,42);STRING$(1+(4-I)*2,32);STRING$(I,42) ELSE PRINT TAB(16-I/2);STRING$(I,42)
50 NEXT
60 NEXT
70 GOTO 70
500 DATA 1,4,1,0
510 DATA 17,9,-2,1
520 DATA 11,17,2,1
530 DATA 4,1,-1,0That’s an ugly line 40, but it got rid of two GOSUBs and two RETURNS. Plus every line takes up 5 bytes, so by removing two of those (each subroutine must start on its own line) we saved even more.
Not only is this smaller, it’s faster, too, since it doesn’t have to spend time seeking through the program looking for a subroutine line number for each line it prints.
If we pack this version, removing unnecessary spaces and semicolons and such, and remove the “GOTO” loop (the challenge does not require the screen to be cleared, and says it can return to a prompt after running), we get:
0 ' LOGIKER22.BAS (don't include this line)
1 FORJ=1TO4:READA,B,C,D:FORI=A TOB STEPC:IFD=0THENPRINTTAB(11)STRING$(I,42)STRING$(1+(4-I)*2,32)STRING$(I,42)ELSEPRINTTAB(16-I/2)STRING$(I,42)
2 NEXT:NEXT:DATA1,4,1,0,17,9,-2,1,11,17,2,1,4,1,-1,0151 bytes of BASIC code!
Is there more that can be done? Comment with your ideas! I think I’m out of them, here.
Until next time…