
See also: part 1, part 2, part 3, part 4, part 5, part 6, part 7, part 8 and part 9.
Variable Placement
Last year, I posted an article dealing with Optimizing Color BASIC. In it, I covered a variety of techniques that could be done to speed up a BASIC program. While this was specifically written about the Microsoft Color BASIC on the Radio Shack Color Computers, I expect it may also apply to similar BASICs on other systems.
James J. left an interesting comment:
Oh yeah. If anyone cares to experiment with modifying the BASIC interpreter, it might be fun to make the symbol table “adaptive”. When you find a variable in the symbol table, if it’s not the first one, swap it with its predecessor. The idea is that the more frequently looked up symbols migrate towards the front and thus are more quickly found. The question is whether the migration improves things enough to make up for the swapping. – James J.
This got me curious as to how much of a difference this would make, so I did a little experiment.
In this Microsoft BASIC, variables get created when you first use them. Early on, I learned a tip that you could define all your variables at the start of your program and get that out of the way before your actual code begins. You can do this with the DIM statement:
DIM A,B,A$,B$
Originally, I thought DIM was only used to define an array, such as DIM A$(10).
I decided to use this to test how much of a difference variable placement makes. Variables defined first would be found quicker when you access them. Variables defined much later would take more time to find since the interpreter has to walk through all of them looking for a match.
Using the Xroar CoCo/Dragon emulator, I wrote a simple test program that timed two FOR/NEXT loops using two different variables. It looks like this:

As you can see, with just two variables, A and Z, there wasn’t much difference between the time it takes to use them in a small FOR/NEXT loop. I expect if the loop time was much later, you’d see more and more difference.
But what if there were more variables? I changed line 10 to define 26 different variables (A through Z) then ran the same test:

Now we see quite a bit of difference between using A and using Z. If I knew Z was something I would be using the most, I might define it at the start of the DIM. I did another test, where I defined Z first, and A last:
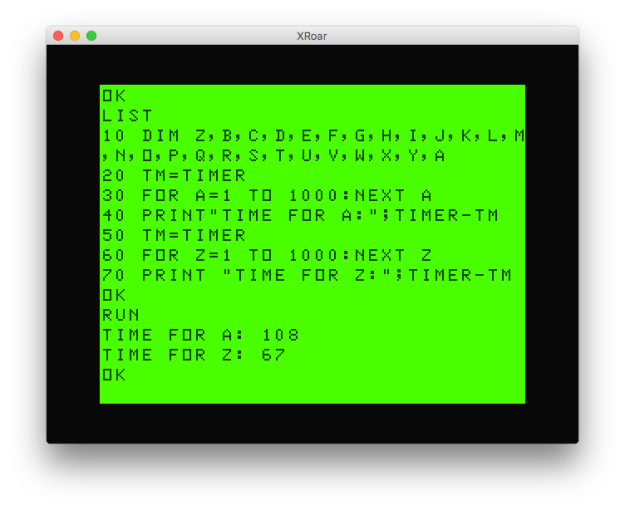
As expected, now the Z variable is faster than A.
Every time BASIC has to access a variable, it makes a linear (I assume*) search through all the variables looking for a match.
Side Note: * There is an excellent Super/Disk/Extended/Color Basic Unraveled book set which contains fully commented disassemblies of the ROMs. I could easily stop assuming and actually know if I was willing to take a few minutes to consult these books.
However, when I first posted these results to the Facebook CoCo group, James responded there:
Didn’t realize it made that much difference–doesn’t the interpreter’s FOR loop stack remember the symbol table entry for the control variable? – James J.
Indeed, this does seem to be a bad test. FOR/NEXT does not need the variable after the NEXT. If you omit the variable (just using NEXT by itself), it does not need to do this lookup and both get faster:

I guess I need a better test.
How about using the variable directly, such as simple addition?

Z, being defined at the end, is slower. And if we reverse that (see line 10, defining Z first), Z becomes faster:

You can speed up programs by defining often-used variables earlier.
James’ suggestion about modifying the interpreter to do this automatically is a very interesting idea. If it continually did it, the program would adapt based on current usage. If it entered a subroutine that did a bunch of work, those variables would become faster, then when it exited and went back to other code, those variables would become faster.
I do not know if the BASIC language lasted long enough to ever evolve to this level, but it sure would be fun to apply these techniques to the old 8-bit machines and see how much better (er, faster) BASIC could become.
Thanks for the comment, James!
Pingback: Optmizing Color BASIC, part 4 | Sub-Etha Software
Pingback: Optimizing Color BASIC, part 5 | Sub-Etha Software
As a point of information on modifying the interpreter to somehow shuffle more frequently used variables to the front of the variable table, that is actually harder than it sounds. It would require storing extra information (access count, for instance). On a system that is already limited in memory, that would probably be intollerable. I could see how you could then use the access count to swap a variable with its preceding one if its access count is higher without too much of a performance hit. However, that tiny extra time would have to apply to every single variable access. Also, you would have to have a periodic sweep that would reset the counters somehow to prevent overflows from creating table churn.
Probably a better solution would be to use an ordered list of variables which would allow using a binary search to find variable entries. Doing that would give O(log n) for lookup times and, so, would be a lot more predictable with a substantially better worst case. That would make creating a variable entry slower but that only happens once. It also wouldn’t require any extra storage space compared to what is currently used. To make things even more fun, as long as the list is always kept ordered, adding a new variable would be at worst O(n).
What if you simply swapped places with the variable before you? No counts needed, but items accessed more often would work their way to the top.
Then you’re going to be swapping variable table entries for every variable access that isn’t the first in the table. I haven’t benchmarked it, but I think that’s going to have a fairly substantial net slowdown in the average case where a program accesses a few variables randomly rather than just the same variable over and over. Swapping 7 bytes takes cpu cycles and it will add up. It takes 16 instructions to do the swap (two loads and two stores per swap, maximum two bytes at a time) barring some truly diabolical optimization scheme, and that’s on top of the two instructions needed to decide if the variable entry should be swapped. That will add up substantially in a non-trivial program.
(7 bytes comes from two bytes for the variable name and 5 bytes for the value or string descriptor.)
I think the overall best case on average would be an ordered variable list and a binary search. Potentially slow variable creation but quite fast searches. (7 comparisons on a variable table with 128 entries, for instance.)
Obviously, bubbling variables to the front of the line (your described solution) will be faster in some cases. Even the existing system is faster in some cases. The ordered list with a binary search is more predictable, though, and not prone to accidentally creating a worst case.
Pingback: Interfacing assembly with BASIC via DEFUSR, part 5 | Sub-Etha Software