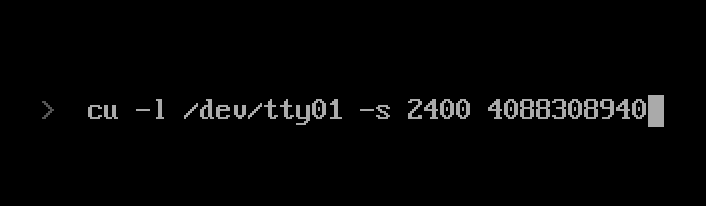The recently released Backrooms movie is set in the old timey year of 1990. Some fun things were used to promote the movie. For example, this TV commercial was released (apparently shown on the Pluto TV streaming service):
In the ads a 408 area code telephone number. Calling that number got you to a fax machine, so folks figured out they could connect using FAX protocol and it would fax back a flyer.
There was also a Bulletin Board System (BBS) set up! Sorta. Since the days of dialup BBSes are long gone, a web site acting as a BBS Archive went live This allowed you to register for an account with the BBS and, once approved, log in via the website. You could then explore this BBS as it existed in 1990:
But how good of a BBS is it? I have thoughts. And, I actually starting using BBSes before I even had my own computer back around 1982. A classmate taught me about them, and we’d go down to a local Radio Shack and they’d let us use their TRS-80 Model 3s to dial in to Houston BBSes. Great times!
Nitpicking the Backrooms BBS
So … how good of a BBS would this have been in 1990? Let’s see…
No 40 column option
It is unsurprising that a BBS from 1990 would be using 80 columns. While there were still plenty of non-PC users (Commodore, Radio Shack, Apple, etc.) calling into BBSes back then, there were plenty of systems that natively displayed 80 columns (Atari ST, Commodore Amiga, and even later 8-bit systems like the Commodore 128 and Tandy Color Computer 3 all had 80 column displays). There were certainly plenty of 80 column only systems by that point, but most flexible BBS software still would let you set your screen width.
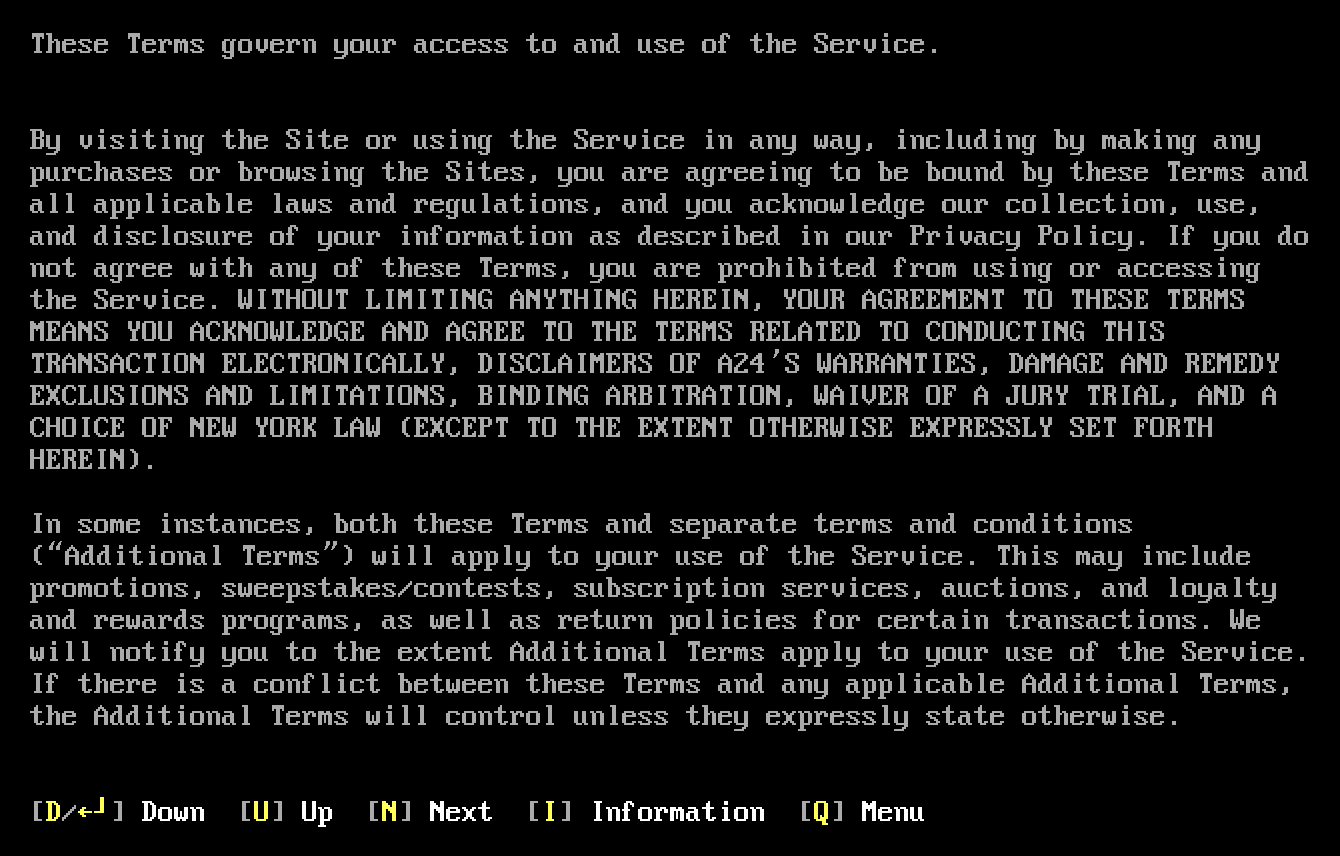
Use of PC-Only character set
What makes this look like a PC was the use of the “enter” symbol (a down then left arrow) found on IBM-PC keyboards of the day. I do not recall ever seeing that on any BBS screens I had visited. Was this common on PC-BOARD or some other MS-DOS BBS system? It was created using a left arrow and a “down and to the left” text character block, so it could have existed on a real PC BBS of the day.
BUT, only the PCs with that character set could have seen this. It would have been some other type of characters for non-PCs. Only some PC emulating terminal program could have displayed it on a Commodore or such. On the CoCo 3, the only one that likely would have worked would be Twilight Terminal by SockMaster, which simulated ANSI colors and IMB PC character sets, and maybe NetMate by Roger Taylor. I am unsure if either of these would have been available in 1990.
But I digress. My point is, I would have expected a BBS in the heart of Silicon Valley to have supported more than just PCs in 1990.
Use of e-mail address for an account
Obviously, a BBS back in 1990 would not have used an e-mail address for an account. Most would let you enter your real name (or an alias), and a password, and perhaps a phone number. Some BBS SysOps (system operators) would call you up to make sure you were real before verifying your account.
But wait, it’s Unix!
The website shows a command prompt:
The “cu” utility is a Unix command (“call unix”) for serial connections. This implies the website is some kind of Unix machine and is dialing a number that is still in service. It is a neat simulation, but not something most of the BBS users in 1990 would have ever used unless they were at a university or some corporation with Unix systems that had modems.
And yes, I did try to alter the command line and change the baud rate. It did not allow it.
Content is key…
And, of course, the main thing is that there was only a handful of messages ;-) Whatever this system was in 1990, it was barely being used by anyone ;-)
Just repeat to yourself: it’s just a show!
But hey, it was a cool promotion, even if it wasn’t likely a BBS any of us would have wanted to use (or even been able to, if we were non-PC users).
For further reading…
Here is a website listing the various things that were done to promote the film:
…that would have been my next computer after my Commodore VIC-20. $600 back in 1983 would be over $2000 in 2026. There was really no way I was talking my grandmother in to buying me a $2000 home computer back when folks were still unsure why anyone would want a home computer.
But, if I did, I’d be much more excited about the return of Commodore. The FPGA recreation, where they are making them using the original molds from the 1980s, has sold over 20,000 units. Likewise, reports of TheC64 (an emulator that looks like a mini C64) estimated to have sold over 300,000 units tells me the love Commodore users had for their 8-bit machines still lives on the same way it does in our CoCo community for our 8-bit systems.
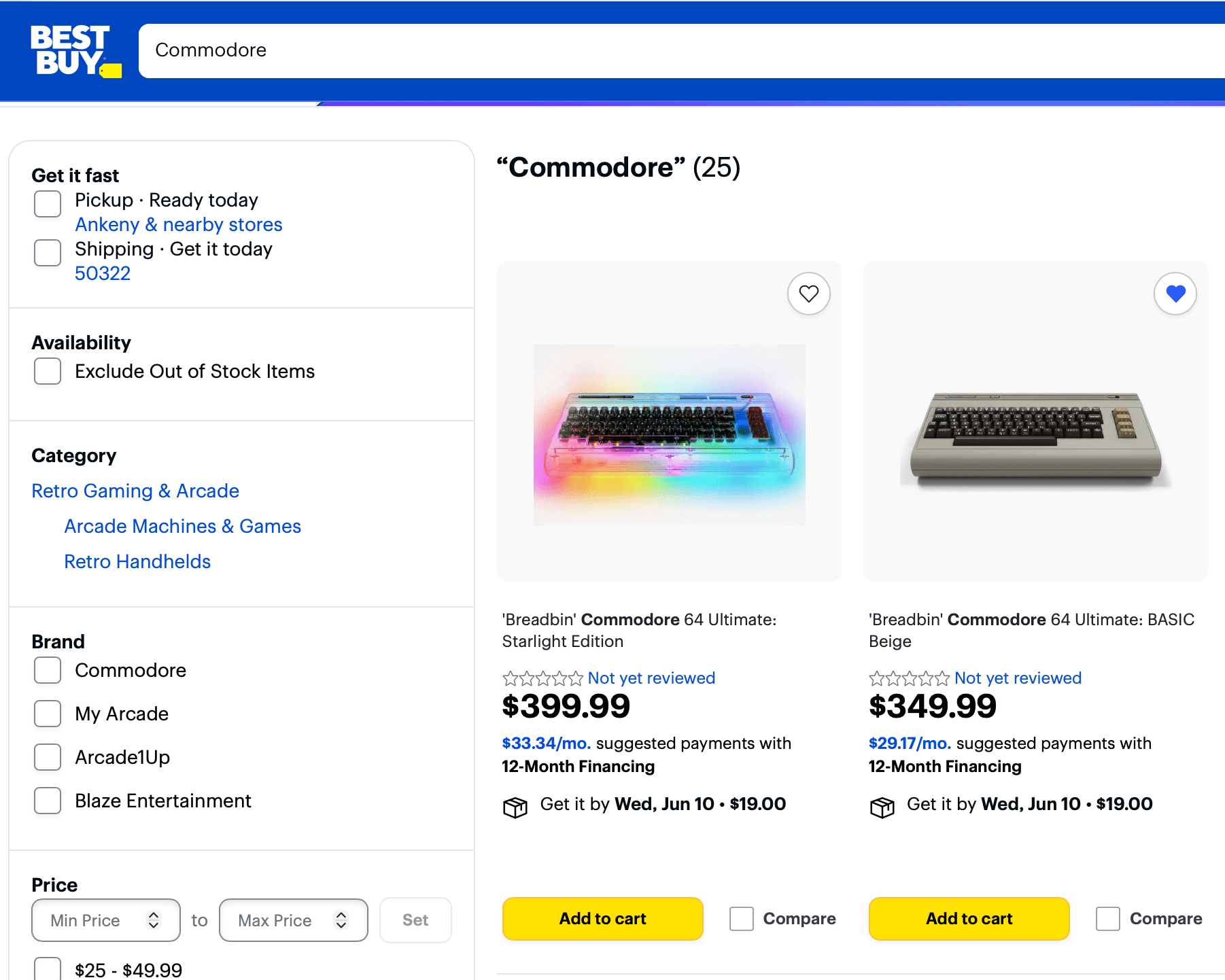
Commodore 64 for sale at Best Buy?
Today I learned that the replica Commodore 64s are for sale at Best Buy (for shipment only, through a third party seller):
Historically, the C64 is the “largest selling computer model of all time” — a feat we will likely never see beaten since modern PCs and Macs have such a short lifespan on store shelves before they are replaced by a different model. While overall there have been more Macs or PCs sold, those have all been different models over the years. (This is the main thing I had against “more PCs sold than Macs” back in the 1990s — you were comparing thousands and thousands of different PC models collectively against a handful of Mac models; but as soon as you compared individual models, the iMac was one of the largest models sold of any computer of its era.)
And the VIC-20, too!
The VIC-20 was far from the best selling system of its era, yet even it got a TheVIC20 release in a full size replica model with an emulator inside. I had to order main from the UK, so it annoyingly has the “correct” spelling of Colour instead of the Americanized version ;-)
Replica Commodore VIC-20: TheVIC20.
There have also been replicas of things like the ZX Spectrum and other “obscure to us in the USA” models.
Maybe one day they will come for our community and we’ll see a mainstream emulator replica of a CoCo.
One can hope.
Congrats, new Commodore. Maybe I can finally get that C64 I would have loved to have 40 years ago.
Click that link to see it run in the web browser. This screen shot does not really show how it looks running:
It shows a CoCo 32×16 text screen smoothy scrolling semigraphics blocks and text characters up the screen. The note that the SAM is not involved is also something I need a child-like explanation of. What does the SAM actually do that would be part of such a technique?
Today we set the wayback machine (kids, ask your grandparents about Rocky and Bullwinkle) to the year of 1996…
But first, I digress.
Some of this will be wrong, but I hope it is at least “directionally accurate.” Feel free to correct (or nit pick, if you prefer) me in the comments.
In 1981, IBM entered the personal computer market with the original IBM-PC. You know the one. It had a cassette port on the back and booted into a Microsoft BASIC. If you were rich enough, you had one with a floppy disk drive and used PC-DOS.
PC-DOS was “created” by Microsoft (kid’s, ask your parents about how Microsoft made a deal with IBM to create a disk operating system for their new computer, then bought an existing disk operating system and sold it to IBM). A bit later, PC-DOS was sold by Microsoft under the name MS-DOS for use with non-IBM-made IBM PC clones.
Thank you for coming to my computer history talk.
8.3: The number that defined a (computer) generation
PC and MS-DOS used 8 characters for the filename with a 3 character extension: FILENAME.BAS, FILENAME.TXT, FILENAME.EXE, etc. This matched the filename convention that the Radio Shack Color Computer Disk Extended Color BASIC (aka, RS-DOS) used, though before PC-DOS, Microsoft used “BIN” for the extension of a binary versus “EXE” and “COM” on the PC-DOS machines. (Maybe BIN was Microsoft’s choice, and EXE was the choice of the original designers of what became known as PC-DOS? I’d look it up, but this has no relevance to this topic at hand.)
Microsoft Windows started out as basically a graphical program that ran from MS-DOS and gave mouse support and a way to run programs. The PCs still booted up into MS-DOS then “ran” the windows program.
Windows 95 and “LFNs”
Windows 95 was a huge change. It altered how “multitasking” would work and, for the first time, allowed long file names on a PC. Instead of being limited to 8.3 for a filename, they could now be up to 255 characters long, with mIxEd CaSe. From the wiki, I see this is called LFN:
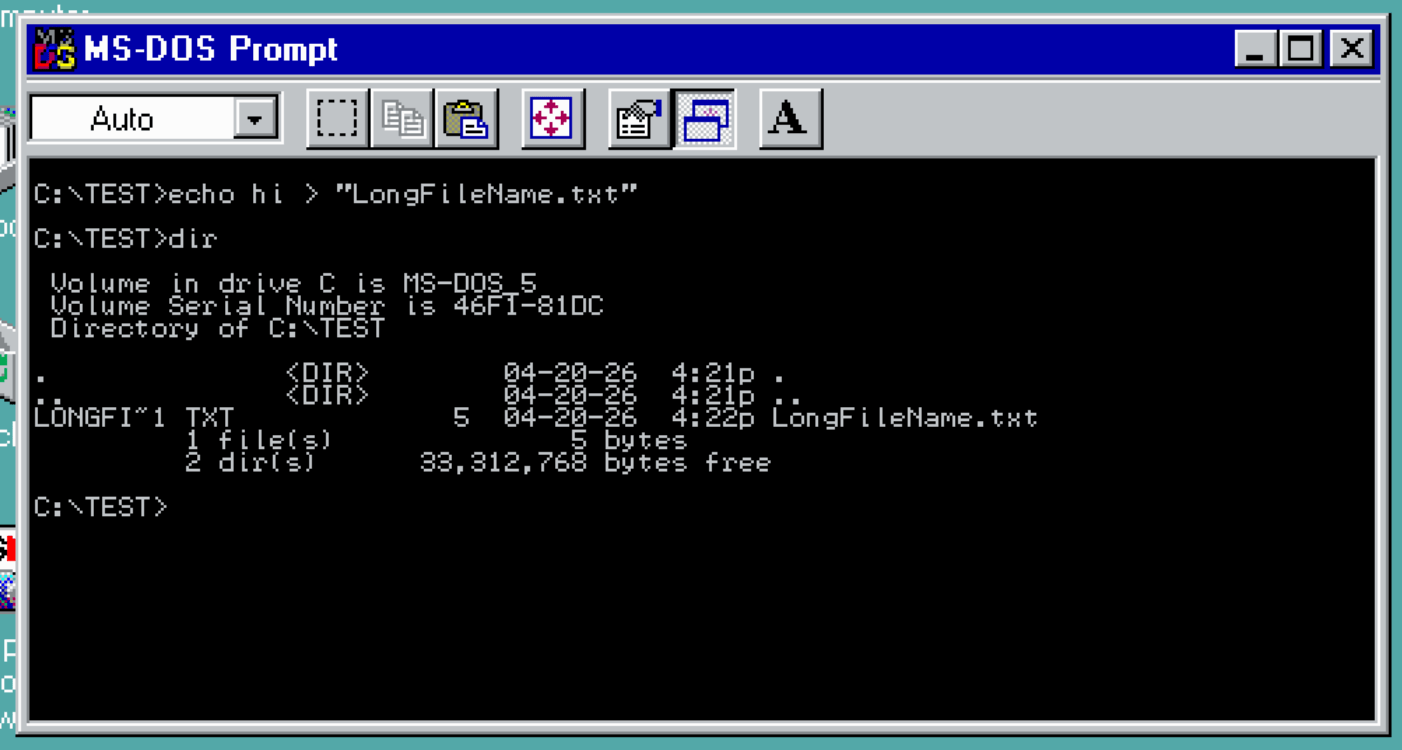
If you created a long filename from Windows 95, it created a backwards compatible 8.3 filename for legacy DOS programs to use. “LongFileName.txt” would be written out as “LONGFI~1.TXT”. The first 6 characters were used, then a tilde and a number.
If you made an 8.3 filename under Windows 95, it would (mostly) work like you expect. Creating “FILENAME.TXT” resulted in “FILENAME.TXT” (and be shown as “Filename.txt” in Windows 95, even if you typed it in all uppercase, for some reason)…
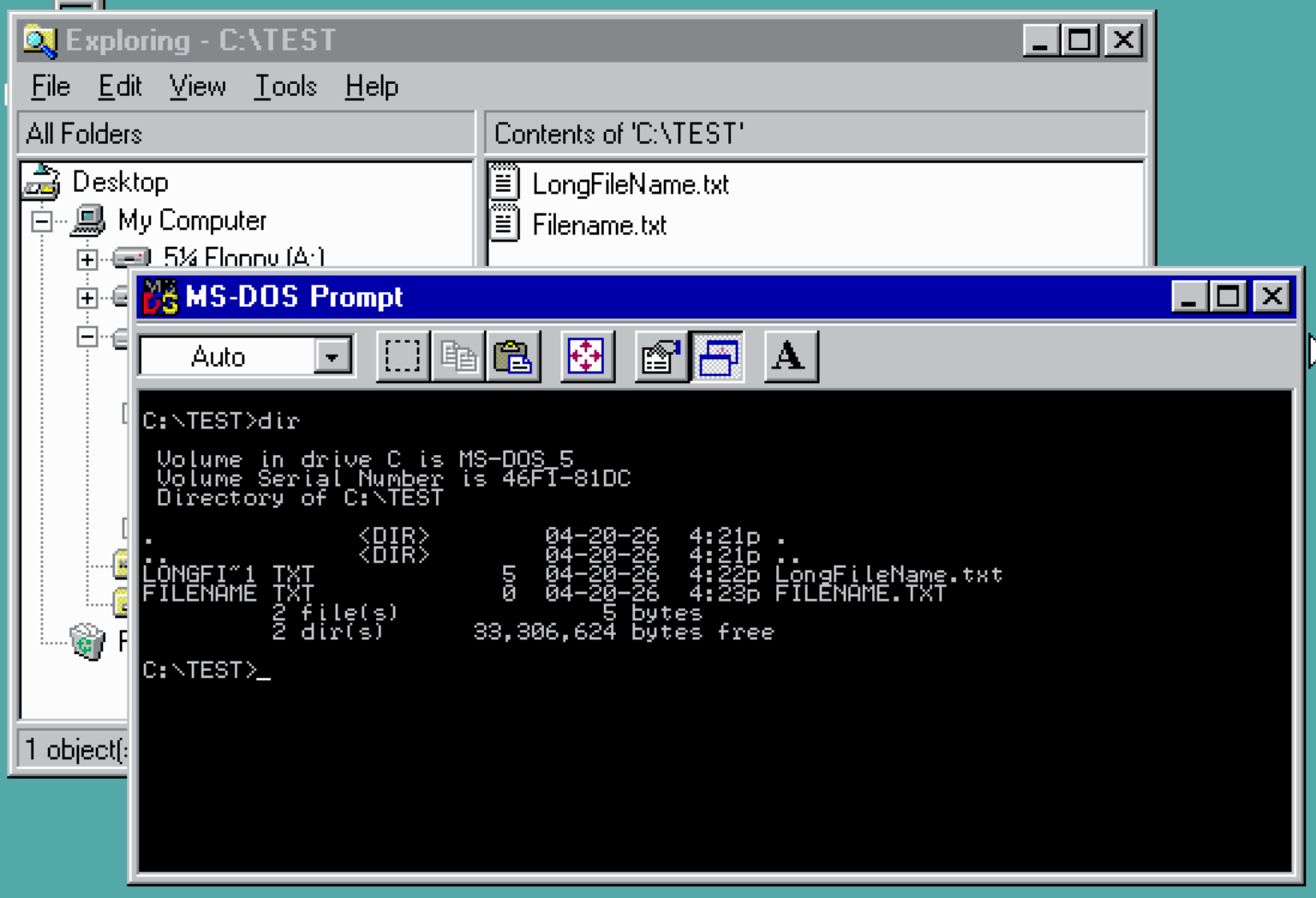
However, some filenames got the “~1” that did not need to. The “~1” should have one been necessary if there was another conflicting file in the directory that matched the first 8 characters and three character extension.
At the time, I was using an MS-DOS C compiler called Power-C. It was not LFN-aware so it only dealt with the 8.3 short filenames. A file like “INDEX.HTML” would become “INDEX~1.HTM” since it had a 4-character extension. But, it could have just become “INDEX.HTM” for the short name (provided there was not another filename that conflicted with).
I got tired of having to deal with “~1” in my website filenames and figured out you I rename them away and make that “INDEX~1.HTM” show up as “INDEX.HTM” (while the long filename was still “INDEX.HTML).
Long filename “index.html” shows up as “INDEX~1.HTM”. rename index~1.htm index.htm
New filename is “index.htm”. rename index.htm index.html
New new filename is “index.html” for long filenames, and “index.htm” for short ;)
Today I bet the wiki entry would explain why it worked that way, but back in 1996 it was just a frustrating mystery.
DIRVERT.EXE
Of course I automated this process… I wrote DIRVERT.EXE, a simple command line program that would loop through a directory and RENAME things to remove the “~1” where possible. Here is what the comments said:
Windows 95 DOS directory converter thingie filter. Takes a Win 95 | directory and renames the 8.3 extentions like they should be… Maybe.
The problem: Pre-Win95 DOS programs don’t know how to deal with long filenames, which end up as “FILENA~1.TXT” to the DOS side. The only time this should be needed is _if_ the DOS name contains spaces or is a duplicate of another truncated filename. ie, “filename1.txt” could be shown as “FILENAME.TXT” but if a “filename2.txt” exists in the same dir, it would have to be “FILENA~2.TXT”. There is no reason for files such as “index.html” to have to be “INDEX~1.HTML”, so this program tries to fix those by renaming them.
To test: “copy con filename.txt”. If you then rename this to a long name with the same first 8.3 characters the same, the DOS name WILL stay the same. ie, “FILENAME.TXT … filenamethatislonger.txt_sothere” in the DIR listing. If you rename and change any of the characters, such as renaming to “filename.text” it will appear as “FILENA~1.TEX” even though it _could_ be “FILENAME.TEX” just fine. This is, in my opinion, a bug in the approach Microsoft took to the filenames. In the above example, this filter will do two renames to try to fix it back. First, it finds the short version of the Win95 name (ie, “filename.tex”) and it renames the DOS name to that. Then it renames it back to the long version. As long as there are no duplicates (those will generate rename errors and just be left alone), this should work just fine. For example, assume:
INDEX~1.HTM – index.html <- current name
this filter does: rename index~1.htm index.htm
INDEX.HTM – index.htm <- new name
then it does: rename index.htm index.html
INDEX.HTM – index.html <- final name, ~1 now gone :)
This won’t work 100% of the time. If there was also a file in there that was called “index.html2”, it would try to make it “index.htm” which would fail since there is already one. So, it would be left alone. Also, any files that might need a space in them ( AFILE.TXT — “a file.txt”) can not be fixed either. BUT, it seems that most anything else can. Note that when you run this, it may be normal to see some errors return from failed renames. No big deal.
Since this is just a filter, it poses no threat to damaging the directory other than renaming files, which is the only shell command it forks.
I used this program for years – right up until the end of my PC era (I switched full-time to a Macintosh in 2001). It is pointless and useless today, but I thought I’d share it. Here it is on GitHub, along with various other “stupid” utilities I wrote for my own use:
As I look at it today, I see it had a conditional compile for OS-9000, which was Microware’s OS-9 RTOS that ran on x86 PC hardware. I am unsure why this would have even been useful — perhaps for dealing with MS-DOS disks when reading them under OS-9000 using the PCF (PC File System) file manager? Ah, the things I have forgotten…
These were fun times. Until next time…
/*---------------------------------------------------------------------------|
| Dirvert V1.08 by Allen Huffman (allenh@pobox.com) |
| Copyright (C) 1996,97 by Sub-Etha Software |
|----------------------------------------------------------------------------|
| Syntax: dir {directory} | dirvert -z |
| dirvert {directory} |
| dirvert -z < {dirfile.txt} |
| Usage : Win95 directory long filename fixer (and filter). |
| Opts : -? or /? = display this message |
| -L or /L = lowercase directory filenames.
| -Z or /Z = read directory output from standard input (filter). |
|----------------------------------------------------------------------------|
| NOTE: It seems this does not work under OSR2! Any ideas why it doesn't? |
| |
| Windows 95 DOS directory converter thingie filter. Takes a Win 95 |
| directory and renames the 8.3 extentions like they should be... Maybe. |
| |
| The problem: Pre-Win95 DOS programs don't know how to deal with long |
| filenames, which end up as "FILENA~1.TXT" to the DOS side. The only time |
| this should be needed is _if_ the DOS name contains spaces or is a |
| duplicate of another truncated filename. ie, "filename1.txt" could be |
| shown as "FILENAME.TXT" but if a "filename2.txt" exists in the same dir, |
| it would have to be "FILENA~2.TXT". There is no reason for files such as |
| "index.html" to have to be "INDEX~1.HTML", so this program tries to fix |
| those by renaming them. |
| |
| To test: "copy con filename.txt". If you then rename this to a long |
| name with the same first 8.3 characters the same, the DOS name WILL stay |
| the same. ie, "FILENAME.TXT ... filenamethatislonger.txt_sothere" in the |
| DIR listing. If you rename and change any of the characters, such as |
| renaming to "filename.text" it will appear as "FILENA~1.TEX" even though |
| it _could_ be "FILENAME.TEX" just fine. This is, in my opinion, a bug in |
| the approach Microsoft took to the filenames. In the above example, this |
| filter will do two renames to try to fix it back. First, it finds the |
| short version of the Win95 name (ie, "filename.tex") and it renames the |
| DOS name to that. Then it renames it back to the long version. As long |
| as there are no duplicates (those will generate rename errors and just be |
| left alone), this should work just fine. For example, assume: |
| |
| INDEX~1.HTM - index.html <- current name |
| this filter does: rename index~1.htm index.htm |
| INDEX.HTM - index.htm <- new name |
| then it does: rename index.htm index.html |
| INDEX.HTM - index.html <- final name, ~1 now gone :) |
| |
| This won't work 100% of the time. If there was also a file in there that |
| was called "index.html2", it would try to make it "index.htm" which would |
| fail since there is already one. So, it would be left alone. Also, any |
| files that might need a space in them ( AFILE.TXT --- "a file.txt") can |
| not be fixed either. BUT, it seems that most anything else can. Note |
| that when you run this, it may be normal to see some errors return from |
| failed renames. No big deal. |
| |
| Since this is just a filter, it poses no threat to damaging the directory |
| other than renaming files, which is the only shell command it forks. |
| |
| COMPILING NOTE: This source defaults to compile in "debug mode" unless |
| you pass in/define "NODEBUG", ie "cc -dNODEBUG dirver.c" to generate the |
| actual "working" version. |
|----------------------------------------------------------------------------|
| Ed # Date What Happened Who |
| -- -------- ------------------------------------------------ --- |
| 01 96/09/25 Created ach |
| 02 96/10/06 Bug fix for filenames with spaces in them ach |
| 03 96/10/09 Fixed function style mistakes (see comments) tc |
| Added proper include file for string functions tc |
| Fixed no command line option bug tc |
| 04 96/10/09 Fixed "fix" to no command line option bug to make |
| it work again like it did in the first place :) ach |
| 05 96/10/23 Debug updates, startup output, and bacon. ach |
| 06 96/12/19 Updated comments, "-z" or "auto" operation. ach |
| 07 97/08/20 Added "-l" lowercase mode. ach |
| 08 98/01/29 Use "stdout" instead of "stderr" now for DOS. ach |
|---------------------------------------------------------------------------*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
void usage(void);
#define MAXLEN 80 /* max dir line length to accept */
#define WINLEN 80 /* won't work on win names longer than this :) */
#ifndef TRUE
#define TRUE 1
#endif
#ifndef FALSE
#define FALSE 0
#endif
int main( int argc, char *argv[] )
{
char line[MAXLEN];
char dosname[13];
char newname[13];
char win95name[WINLEN];
char cmd[160];
int count = 0;
int i,j;
char *ptr;
char doit = FALSE;
char lowerit = FALSE;
for ( i=1 ; i<argc ; i++ ) {
if ( argv[i][0] == '-' || argv[i][0] == '/' ) { /* option found! */
switch( toupper(argv[i][1]) ) {
case '?': /* request for help? */
case 'H':
usage();
case 'L':
lowerit = TRUE;
break;
case 'Z': /* filter mode? */
doit = TRUE;
break;
default:
fputs( "\nUnrecognized option: ", stdout );
fputs( argv[i], stdout );
fputs( "\n", stdout );
usage();
}
} else { /* must be a directory path? */
strcpy( cmd, "dir " );
strcat( cmd, argv[i] );
#ifdef _OS9000
strcat( cmd, " ! " );
#else
strcat( cmd, " | " );
#endif
strcat( cmd, argv[0] );
strcat( cmd, " -z" );
if ( lowerit == TRUE ) strcat( cmd, " -l" );
#ifndef NODEBUG
fprintf( stdout, "--- fork: %s\n", cmd );
#endif
i = system( cmd ); /* forgive me, father, for I have sinned... */
return( i ); /* get outta here */
}
}
if ( doit != TRUE ) { /* if we aren't in auto mode, we can bail */
usage();
}
fputs( "dirvert: Processing directory output.\n", stdout );
/*--------------------------------------------------|
| Read as many lines as we can from standard input. |
|--------------------------------------------------*/
while( !feof( stdin ) ) {
fgets( line, MAXLEN+1, stdin );
if ( strlen(line)<44 ) continue; /* ignore short lines */
line[strlen(line)-1] = '\0'; /* convert CR into a NULL */
/*----------------------------------------------------|
| Check to see if the line contains filename entries. |
|----------------------------------------------------*/
if (( line[39] == ':' ) && ( line[15] != '<' )) {
if ( lowerit != TRUE ) { /* skip bad names only if not lowerit mode */
i = strcspn( line, "~" ); /* extended name? */
if ( i == strlen(line) ) continue; /* no, so skip */
}
/*--------------------------------|
| Build existing DOS name string. |
|--------------------------------*/
i = strcspn( line, " " ); /* find first space */
strncpy( dosname, line, i ); /* copy up to the space */
dosname[i] = '\0'; /* NULL terminate */
strcat( dosname, "." ); /* append "." */
strncat( dosname, line+9, 3 ); /* append extension */
/*---------------------------|
| Build the new name string. |
|---------------------------*/
ptr = line + 44; /* point to long filename */
strncpy( win95name, ptr, WINLEN ); /* copy it over */
if ( lowerit == TRUE ) {
for ( i=0; i<strlen(win95name) ; i++ ) {
win95name[i] = (char)tolower( win95name[i] );
}
}
i = strcspn( ptr, "." ); /* find extension */
if ( i > 8 ) { /* extension past first 8? */
j = 8; /* yes, crop there */
} else {
j = i; /* no, crop at extension */
}
strncpy( newname, ptr, j ); /* copy filename */
newname[j] = '\0'; /* NULL terminate */
strcat( newname, "." ); /* append "." */
if ( i < strlen(ptr) ) { /* if it has an extension, */
strncat( newname, ptr+i+1, 3 ); /* append it */
}
#ifndef NODEBUG
fprintf( stdout, "DOSname : %s\n", dosname );
fprintf( stdout, "WINname : %s\n", win95name );
fprintf( stdout, "NEWname : %s\n", newname );
#endif
/* this check could and should be done earlier somehow since none of this
needs to be done of the resulting 8.3 filename is still invalid for DOS,
such as containing spaces */
/* if new name contains a space, it's not valid so ignore */
if ( strcspn( newname, " " ) != strlen(newname) ) {
#ifndef NODEBUG
fprintf( stdout, "--- This file cannot be changed.\n\n");
#endif
continue;
}
/*--------------------------|
| Fork the rename commands. |
|--------------------------*/
strcpy( cmd, "rename " ); /* build command line */
strcat( cmd, dosname );
strcat( cmd, " " );
strcat( cmd, newname );
#ifndef NODEBUG
fprintf( stdout, "--- fork: %s\n", cmd );
#else
system( cmd ); /* forgive me, father, for I have sinned... */
#endif
strcpy( cmd, "rename "); /* build command line */
strcat( cmd, newname );
strcat( cmd, " \x22" );
strcat( cmd, win95name );
strcat( cmd, "\x22" );
#ifndef NODEBUG
fprintf( stdout, " %s\n\n", cmd );
#else
system( cmd );
#endif
count++; /* increment counter :) */
}
}
#ifndef NODEBUG
fprintf( stdout, "%d directory entries processed.\n", count );
#endif
return 0;
}
void usage(void)
{
fputs( "\nDirvert V1.08 by Allen Huffman (allenh@pobox.com)\n", stdout );
fputs( "Copyright (C) 1996-1998 by Sub-Etha Software\n\n", stdout );
fputs( "Syntax: dir {directory} | dirvert -z\n", stdout );
fputs( " dirvert {directory}\n", stdout );
fputs( " dirvert -z < {dirfile.txt}\n", stdout );
fputs( "Usage : Win95 directory long filename fixer (and filter).\n", stdout );
fputs( "Opts : -? or /? = display this message.\n", stdout );
fputs( " -L or /L = lowercase directory filenames.\n", stdout );
fputs( " -Z or /Z = read directory output from standard input (filter).\n", stdout );
#ifndef NODEBUG
fputs( "\n*** DEBUG VERSION ***\n", stdout );
#endif
exit(0);
}
In GFXFLIP.BAS, instead of the ‘flip through them’ code, try this:
1000 ‘GO DO THE ROTATION 1010 GOTO 1050 1020 FOR P=2 TO 5:GOSUB 1070:PMODE 4,P:SCREEN1:NEXT 1030 IF INKEY$=”” THEN 1030 1040 FOR P=4 TO 1 STEP -1:GOSUB 1070:PMODE 4,P:SCREEN1:NEXT 1050 IF INKEY$=”” THEN 1050 1060 GOTO 1020 1070 FOR TT=0 TO 40:NEXT:RETURN “
– Juan Casto via CoCo Mailing list
So let’s take a look and see what it does. Replacing my code from 70-110 with a GOSUB to this routine gives us this:
0 'GFXFLIP2.BAS 1 'Juan Castro 10 PCLEAR 8 15 ' DRAW FIRST SCREEN 20 PMODE 4,1:PCLS:SCREEN 1,1 30 CIRCLE(128,96),50 35 ' DRAW SECOND SCREEN 40 PMODE 4,5:PCLS:SCREEN 1,1 50 LINE (10,10)-(245,171),PSET,B 60 ' FLIP THROUGH THEM 70 GOSUB 1000 110 GOTO 70
1000 'GO DO THE ROTATION 1010 GOTO 1050 1020 FOR P=2 TO 5:GOSUB 1070:PMODE 4,P:SCREEN1:NEXT 1030 IF INKEY$="" THEN 1030 1040 FOR P=4 TO 1 STEP -1:GOSUB 1070:PMODE 4,P:SCREEN1:NEXT 1050 IF INKEY$="" THEN 1050 1060 GOTO 1020 1070 FOR TT=0 TO 40:NEXT:RETURN
…and when you run it, you will see it takes the PMODE 4 screen (which is 4 blocks of graphics memory) then goes in a loop where it starts the displayed screen at block 2, then 3, then 4, then 5. With a small delay in-between each change, it shows (initially) the first PMODE 4 screen (blocks 1-4), then it toggles the memory displayed through each block until the start is block 5. This makes the screen appear to scroll up in chunks (1/4th of the screen each time). The process is then reversed to scroll back down.
Trigger warning: This post will show some examples that “just work” and “just work fine” but may not be correct. I am posting this because I’d like to hear how you do this. Show us all a much better way.
I was today years old when I “learned” (possibly incorrectly) something (possibly) wrong that I have seen “always” done in the C debug print macros I’ve encountered.
Debug Macros: Basic
To enabled or disable debugging printf output, I often see macros like this:
This allows debug printfs to appear in code when debug is enabled or not exist at all when debugging is not enabled:
DEBUG_PRINTF ("Starting up system...\n");
Debug Macros: Intermediate
There is a fancier version of this macro. Instead of just using a #define DEBUG_ENABLED (present means enabled), the code uses a #define set to a number. That number is used to tell when to include the debug print:
If you “#define DEBUG_LEVEL 1”, the above code will not be part of the program. If the DEBUG_LEVEL is defined to be greater than 1, it will.
That also “just works” but makes the source code messier with all those extra “#if (DEBUG_LEVEL > x)” and #endif” lines.
Debug Macros: Advanced
This leads to the even fancier version which builds the level check into the macro itself. Those get used like:
DEBUG_PRINTF (2, "This will only print at level 2 and above.\n");
The downside of that approach is that a #define macro cannot contain preprocessor #if to check another #define macro inside of it. You can NOT do this:
The problem with this is that even with debugging disabled (where you may not want the bulk of printf included in your program) it will still include all that macro C code in your program. With DEBUG_LEVEL enabled:
#define DEBUG_LEVEL 1
DEBUG_PRINTF(0, "Starting system up...\n")
…you get:
if (0 < 1)
{
printf ("Starting system up...\n");
}
But if you do not want debugging, and set the debug level to 0, you’d get this:
#define DEBUG_LEVEL 0
DEBUG_PRINTF(0, "Starting system up...\n")
if (0 < 0)
{
printf ("Starting system up...\n");
}
That is more like using some syslog() library that is always present, even if you are logging things below the level that go to the system log. But the point of using macros is so you can have the code NOT included at all when you don’t want to use it.
A bit more work is needed, which leads to something like this:
Now we get what we want when we want it, and get nothing when we don’t.
But that’s really not important to this story…
The above macros are things that “just work” which may explain why I see things like that often.
But today I learned they are actually not fine. Our good robot friend Copilot “taught” me that the macro above should really look like this, with the code wrapped in something like a do/while:
#define DEBUG_LEVEL 1
#if (DEBUG_LEVEL > 0)
#define DEBUG_PRINTF(level, ...) \
do { \
if (level < DEBUG_LEVEL) \
{ \
printf(__VA_ARGS__); \
} \
} while (0)
#else
#define DEBUG_PRINTF(level, ...) \
do { } while (0)
#endif
I found it odd that it suggested an empty “do / while(0)” and had to research this a bit. You may already know this, but since I had never seen it, I was unaware of the issue(s). Here is what Copilot says about this:
It forces the macro to behave like ONE statement
It makes the trailing semicolon safe
It prevents `if/else` breakage
It prevents partial execution
It compiles away to nothing when disabled
I could argue with the robot about #5 since I have certainly used compiler that where happy to leave in unused variables and functions without even a warning about them. ;-)
Of that list, #3 is really the only oneI think that applies to this specific debug macro. As Copilot points out, this example will not work with the non-do/while version of the macro:
if (flag)
DEBUG_PRINTF(1, "msg");
else
do_other_thing();
That would translate into this:
if (flag)
if (level < DEBUG_LEVEL) \
{ \
printf(__VA_ARGS__); \
}
;else
do_other_thing();
And that won’t compile.
However, the coding standards where I have worked all forbid if/else usage like that. Without having curly braces around the statements, someone might later introduce a bug like this:
if (flag)
DEBUG_PRINTF(1, "msg");
else
do_other_thing();
this_will_always_run();
…because without the braces, the compiler is basically seeing the code like this:
if (flag) DEBUG_PRINTF(1, "msg"); else do_other_thing();
this_will_always_run();
The curly braces ensure the code runs the statements as intended.
If you use that original “bad” macro with the same code but add braces:
if (flag)
{
DEBUG_PRINTF(1, "msg");
}
else
{
do_other_thing();
}
It looks like this, and works fine:
if (flag)
{
if (level < DEBUG_LEVEL) \
{ \
printf(__VA_ARGS__); \
}
;
}
else
{
do_other_thing();
}
But, the addition of the “useless” do/while loop (or similar logic) around the macro would make it work with the non-curly brace version:
if (flag)
do { \
if (level < DEBUG_LEVEL) \
{ \
printf(__VA_ARGS__); \
} \
} while (0)
;else
do_other_thing();
#include <stdbool.h>
#include <stdio.h>
#define DEBUG_LEVEL 1
#if (DEBUG_LEVEL > 0)
#define DEBUG_PRINTF(level, ...) \
do { \
if (level < DEBUG_LEVEL) \
{ \
printf(__VA_ARGS__); \
} \
} while (0)
#else
#define DEBUG_PRINTF(level, ...) \
do { } while (0)
#endif
void do_other_thing () { return; }
int main()
{
bool flag = true;
if (flag)
DEBUG_PRINTF (0, "Hello\n");
else
do_other_thing();
return 0;
}
Here’s where you come in…
What have you seen? I know modern PC/Linux/Mac environments don’t care about a few extra K of code space, so far fancier debug logging is likely common. But for embedded space, have you ran into the macros like I have, or do you always see the “do / while(0)” ones or something else?
A recent e-mail exchange with CoCo user Torsten D. inspired me to try something stupid.
The Radio Shack Color Computer gained the VARPTR command in the Extended BASIC ROM. As has been discussed here many times, VARPTR returns the memory location of a 5-byte variable descriptor. There are actually seven bytes total, since the two bytes before the VARPTR address is the two byte variable name.
0 'MAKE42-1.BAS 10 DIM A,B,C:A=42:B=VARPTR(A) 20 FOR C=B-2 TO B+4 30 PRINT C,PEEK(C):NEXT
Running this will show the full seven bytes required to represent the A variable:
VARPTR is returning 9792 as the location of the start of the 5-byte floating point value for the numeric A variable. The two bytes before it are the variable name: 65 (uppercase “A”) and 0 (no second letter). Had the variable name been “AA” that would be 65 65.
The five bytes of 134, 40, 0, 0 and 0 are the floating point representation of 42.0.
If you got the VARPTR address of one numeric variable, and of a second numeric variable, you could just copy those five bytes and clone the variable value:
0 'MAKE42-2.BAS 10 DIM A,B,I 20 A=42:B=0 30 PRINT "A =";A,"B =";B 40 FOR I=0 TO 4:POKE VARPTR(B)+I,PEEK(VARPTR(A)+I):NEXT 50 PRINT "A =";A,"B =";B
If you run this, you will see output showing “A = 42” and “B = 0”, followed by output showing “A = 42” and “B = 42”. The code in line 40 copies the five bytes (offset 0 to 4) from the VARPTR address of variable A into the VARPTR address of variable B.
And if you can clone a variable, you could also change a variable if you knew what five bytes represented the number you wanted. In the first example, we saw that the five bytes that represent 42.0 are 134, 40, 0, 0 and 0. Knowing that, you could do something like this:
0 'MAKE42-3.BAS 10 DIM A,V 20 PRINT "A =";A 30 V=VARPTR(A):POKE V,134:POKE V+1,40: POKE V+2,0:POKE V+3,0:POKE V+4,0 40 PRINT "A =";A
The “DIM” is not really needed in this example, but it is a good habit to get into if you want to control the order your variables exist in the variable table. Variables that need to be the fastest should be at the front of the list, and variables use infrequently or ones that can be slow can be at the end.
But I digress.
The point of this stupid code is that an “A” variable is created with 0 as its default value, then VARPTR is used to see where that variable is in memory. Five POKE commands put that floating point representation of 42.0 into that variable’s storage… So when you print A, you get a value of 42, even though A=42 (or indeed, A= ANYTHING) was nowhere in the program.
The author recently joined the Cocopedia.com and has updated some technical sections with information he has learned in adding support for the CoCo. Clock Signal is described as:
“A latency-hating emulator of: the Acorn Electron, BBC Micro and Archimedes, Amstrad CPC, Apple II/II+/IIe and early Macintosh, Atari 2600 and ST, ColecoVision, Enterprise 64/128, Commodore Vic-20 and Amiga, MSX 1/2, Oric 1/Atmos, early PC compatibles, Sega Master System, Sinclair ZX80/81 and ZX Spectrum, and Thomson MO5/6.”
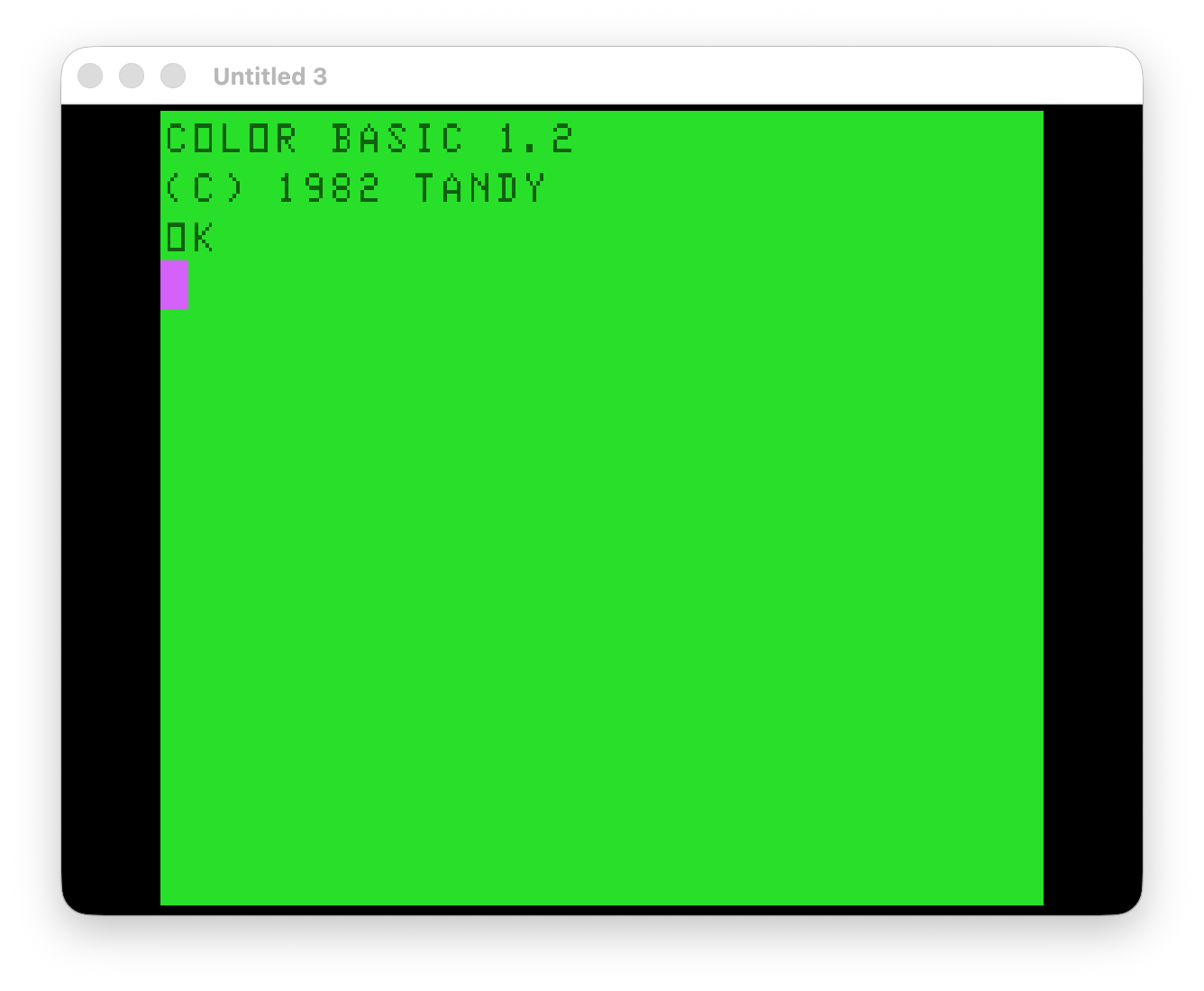
The author is adding CoCo to this list. As someone who started out with a Commodore VIC-20, then went to the CoCo, I am intrigued to find another emulator that will do both. (MAME/MESS also does both.) There is currently early support for the CoCo in there, but it only boots a CoCo Color BASIC 1.2 ROM:
I was able to download Clock Signal from GitHub, then open the Xcode project on my Mac, change one setting, then build and run. Neat!
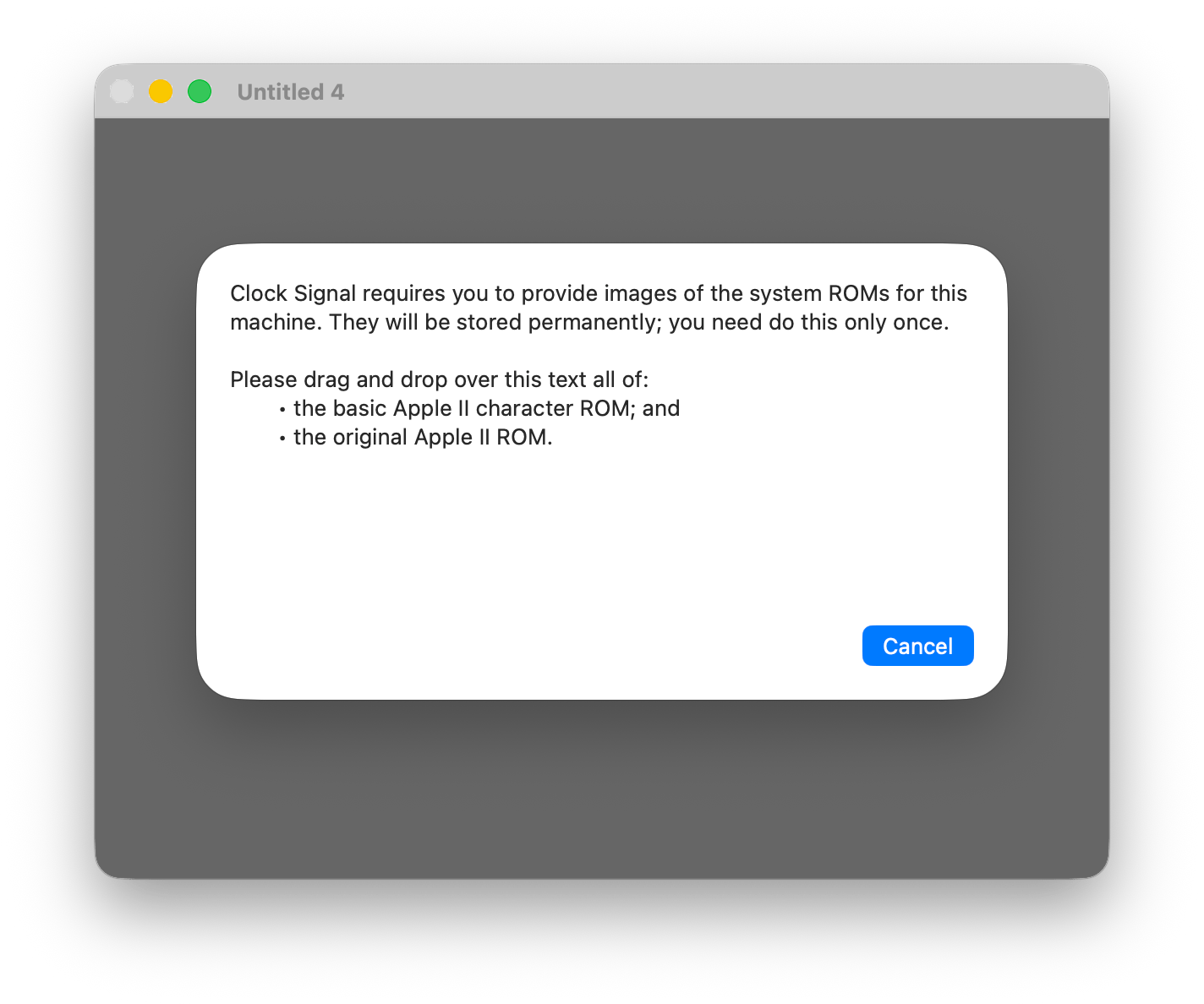
When you first run one of the emulators, it will prompt you to drag in the needed ROMs:
Drag them into that window, then it’s ready to go. Pretty easy.
I know little beyond this, but plan to play with this a bit and try to get some of the other systems up and running.
One downside is that it looks like there may not be a Windows version.
I have worked with a variety of C compilers at my day jobs over the years. Although they try to be “real” compilers, they often have limitations that would drive “real” C programmers crazy.
Like, one tool I used did not allow constant strings longer than 80 characters. The error it gave was unhelpful, but eventually support was able to figure out what was going on.
Imagine my surprise to find that this would simply not build:
…but removing one character allowed it to build just fine.
Another compiler did not allow constants to be passed as arguments to a function. You could not do this:
strcpy (buffer, "Hello"); // This wouldn't work.
…and had to do this instead:
char *temp = "Hello";
strcpy (buffer, temp); // This is the way.
And that was just the start of it. In that world, the “const” keyword was basically off-limits to use as you might be used to using it. A function that is not supposed to mess with a buffer passed in might look like this:
…but since you cannot pass const data into functions on that compiler, that code will not compile.
And if you are trying to use code between a modern system (like a PC) and this compiler, removing “const” then has the modern compiler — with strict warnings turned on — will issue warnings if you pass a “constant string” into that function because it removes that “const” protection since it is a “char *” instead of a “const char *”.
My career is fun. Let’s use say I use “#ifdef” more than most C programmers ever have to…
If you don’t have to deal with this type of stuff, I hope you appreciate that. Embedded programmers have to do so much more work with so much less resources to get something done ;-)