I initially tested the machine out on my old Lenovo Windows 10 machine. It was pretty easy to figure out how to do the basic things.
Next, I wanted to run it on my Mac, but LaserGRBL is Windows only. Since I run Windows 11 (Arm) on my Mac, I thought I could just do that. While LaserGRBL runs, the CH340 serial driver is not compatible with Windows/Arm. I was not able to find an Arm version of that driver, so it looks like it’s only possible to use this on an Intel PC (or Intel Mac). I guess I didn’t realize Arm windows machines like the Surface tablets couldn’t run all the same software.
Next I moved on the LightBurn, which is a commercial program available for Windows, And and Linux:
I played with the trail a bit on an Intel Windows PC and it looked like it offered a lot of extra features that LaserGRBL did not have. When I tried it on the Mac, I couldn’t talk to the engraver because it needed the CH340 driver.
I did some searching and found a Sparkfun page with a download to “some” CH340 driver. That worked, but I wondered how up to date the driver was. I did some searching and found all kinds of places with random Chinese device drivers for the CH340.
I *think* the source of the CH340 (maybe the company that created it, originally) is this:
They also have Windows versions, but I did not see a Windows/Arm installer.
This version is much more updated from the one I got through Sparkfun. It installs an app that, when it runs, installs the driver. On modern Macs you have to do the normal “restart, tell the computer it’s okay to run this unsigned mystery driver from China” stuff to be able to use it. I found it interesting that, once it’s installed, it has an application that you just delete to remove the driver. I’m not sure how that works, unless it’s installing something that points to that application somehow.
But anyway, in case anyone else is looking for the CH340 driver for Mac, that’s where I found it.
Good luck.
And if you find an Arm version for Windows, leave a comment and let me know where you found it.
On a 64K Color Computer, the BASIC ROMs configure it so the first 32K is RAM and the second 32K is ROM. It is easy to change a memory location and cause the upper 32K to be RAM, too, but if you did that from BASIC you would suddenly find yourself without the ROM and would have a nice crash.
Machine language programs that did not rely on any ROM calls could enable the 64K RAM mode and use the full 64K memory as they wished.
At some point, someone was the first to figure out they could copy the ROMs in to RAM, and then switch to RAM mode. This would allow them to be running BASIC from RAM, and thus it would be possible to use POKEs to modify the BASIC code and do patches.
In an effort to see who first figured this out and published details, I did some searching…
March 1982 – Frank Hogg
I found something on page 18 of the March 1982 issue of Color Computer News. The article was called “MORE ON 64K by Frank Hogg of Frank Hogg Labs.
Last month we showed you how to access the other 32K in your Color Computer bringing it up to the full 64K, This month we’re going to discuss some additional uses for that memory, plus a program to copy the ROM Basic into RAM and run it there;
– Frank Hogg, Color Computer News, March 1982
Included was a BASIC program that loaded the machine code, with example POKEs used to modify BASIC (such as changing the PRINT command to be WRITE).
The assembly code was listed in comments:
1820 ' THE MACHINE LANGUAGE
1830 ' PROGRAM TO MOVE BASIC TO
1840 ' RAM IS AS FOLLOWS:
1850 '
1860 '
1870 ' EP ORCC #$50 DIS. INTS.
1880 ' LDX #$8000 1ST ADDR.
1890 ' LOOP LDA ,X
1900 ' STA $FFDF MAP TYPE 1
1910 ' STA ,X+ IN RAM!
1920 ' STA $FFDE MAP TYPE 0
1930 ' CMPX #$FFOO LAST +1
1940 ' BNE LOOP
1950 ' STA $FFDF MAP TYPE 1
1960 ' ANDCC #$AF ENBL INTS
1970 ' RTS
Was this the first such program published?
April 1983 – Frank Hogg revisted
Frank had a follow-up in the April 1983 issue, as well, on page 19. It looks like an article, but it was labeled as a paid ad called “64K KORNER“:
The code listed was the same, but with updated comments. He also added a copyright notice as well as a small standalone BASIC loader:
1 ' Copyright 1983 by Frank Hogg Permission to use is
2 ' given for all but commercial use.
10 CLEAR 999
20 DATA 26,80,190,128,0,183,255,222,166,128
30 DATA 183,255,223,167,31,140,224,0,37,241,57
40 FOR I=1 TO 21:READ A:A$=A$+CHR$(A):NEXT I
50 P=VARPTR(A$)+1
60 POKE P,126
70 EXEC P
80 PRINT "NOW IN RAM!"
Frank chose to store the machine language bytes as characters of a string. He then gets the pointer to the 5-byte string descriptor and adds one to it. That makes P point to the unused byte which is directly in front of the two byte address of the string in string space. The string descriptor looks like this:
Addr of String in Mem
|
+-----+
| |
[Siz] [N/A] [MSB] [LSB] [N/A]
|
P points here
He then POKEs a 126 at that P location, which I believe is a machine language JMP instructions. Then he EXECutes P, which makes for a very clever way to execute this code!
[Siz] [JMP] [MSB] [LSB] [N/A]
I would have done it the long way like this:
P=VARPTR(A$)
EXEC PEEK(P+2)*256+PEEK(P+3)
Frank did much better.
July 1987 – Rainbow article
Another ROM to RAM program showed up in the July 1987 Rainbow on page 97. Joseph Forgione submitted a small utility to change BASIC’s “OK” prompt to say “READY.” In included a short DRIVER.BAS program which was a ROM to RAM routine:
1 DATA 26,80,142,128,0,127,255,222,166,132,127,255,223,167,132,48,1,140,255,0,38,239,28,159,57
2 FORA=&HE00 TO &HE18:READX:POKEA,X:NEXTA:EXEC3584:POKE65503,0:PRINT"OS IS NOW IN RAM!"
I fed those bytes in to the 6809 Simulator at www.6809.uk to see what it looked like:
This is very similar to Hogg’s original, except instead of incrementing X when the byte is stored (STA ,X+) the author chose to not do that, and have a different instruction add one to X (LEAX $01,X). That makes it a few bytes larger and a few clock cycles slower, not that anyone would really notice.
Where did it come from?
I have yet to locate the one I used back on my CoCo 1, but it was probably from my pre-disk drive days and is on some old cassette tape somewhere. I had never seen Color Computer News, so my version probably came from Rainbow Magazine, or perhaps one of the few issues of Color Computer Magazine or Hot CoCo I picked up from the newstand. I was unable to locate anything obvious in the Rainbow indexes except that 1987 article.
Variations of this code seem to pop up, even to this day. In 2016, Juan Castro provided me a routine which I used in an earlier article about 64K. It was a faster one, that copied 6 bytes at a time instead of just one.
If anyone know who did this first (or at least was the first time it was in print somewhere), please leave a comment.
Until then, we’ll say it was Frank Hogg in March 1982.
Due to reasons I discussed at length in an earlier article, the Microsoft BASIC in the Color Computer recognizes no more than 32K of RAM, minus the memory used for BASIC and screen memory.
When folks figured out how to upgrade the original Color Computer to 64K (by piggybacking 32K of RAM on top of the existing chips and running some wires), BASIC could not see or use that extra memory.
Enter the Dragon
Dragon Data, which sold the CoCo “clone” Dragon computers in the U.K., improved on this limitation with their Dragon 64 computer. It would boot up in a compatibility mode with the same memory limitation as the earlier Dragon 32 machines, but allowed entering a new mode that moved things around to allow more memory for BASIC.
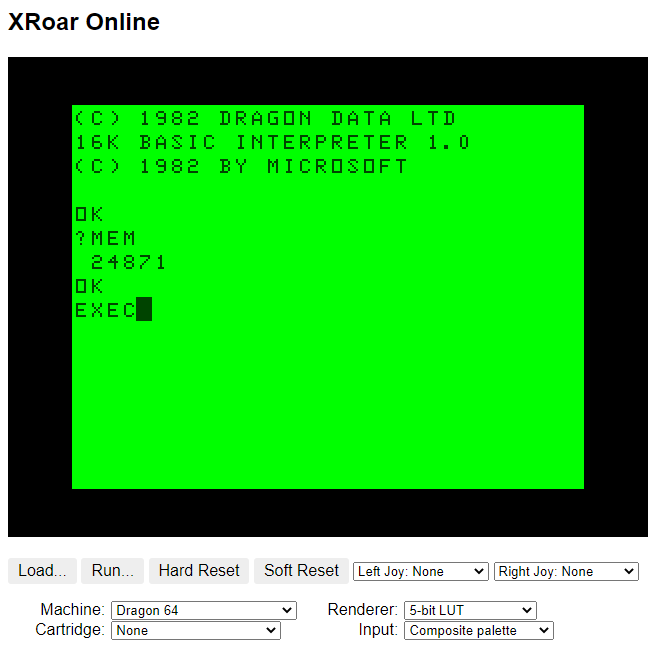
If you start up a cassette-based Dragon 64 in the XRoar Online emulator, you get 24871 bytes available to BASIC:
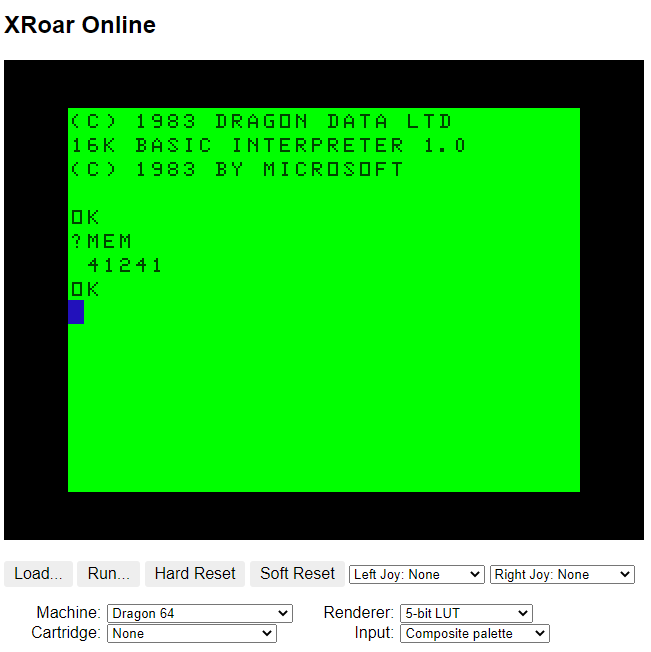
If you then typed EXEC (to execute a machine language routine), the default routine it executed would do some magic to relocate BASIC and restart it with 41241 bytes available. (Both of these values will be less if using a disk system.)
Oh how I wish we had gotten that feature added to the CoCo’s BASIC when 64K machines first came out. (There were rumors that the Deluxe Color Computer 2 would have had something like this as part of it’s new features, but that machine never came to exist beyond some mentions in the BASIC manuals.)
CoCo RAM: Don’t ask, don’t tell.
On the CoCo, once you got to 32K, the machine would show the maximum amount of memory available to BASIC — the same 24871 seen by a Dragon 32 machine.
On startup, a cassette-based CoCo has 24871 bytes available for BASIC.
If you had a 64K machine, it would still show the same value since that is all BASIC knew about. The rest of the 64K was hidden.
“Assembly Language or OS-9”
In those early years, it seemed the official line from Radio Shack was that 64K was usable only from assembly language or the OS-9 disk operating system.
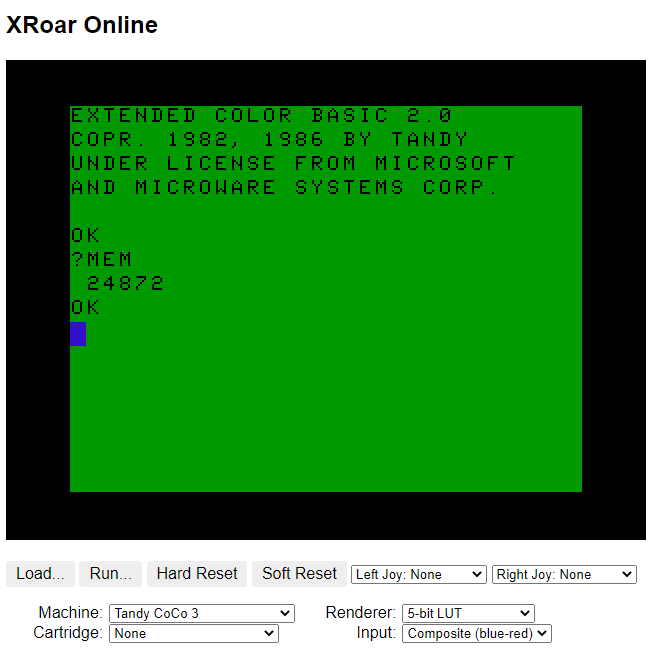
The same was true when the CoCo 3 came out in 1986. It came with 128K but could be expanded to 512K. Even though BASIC was enhanced to support the new graphics modes of the machine, it still only saw 32K available for BASIC programs. On a 512K CoCo 3, free memory for BASIC was reported as 24872:
…and now I am very curious to see where that extra byte came from.
Show me the mem’ry!
And here we are in 2022, over four decades after the first CoCo was sold in 1980, and folks are still wondering how to tell how much memory is in their machine.
One of the most suggested ways of determining if a CoCo 1 or 2 has 64K is to try to run the game Saylor Man from Tom Mix Software. It is notable for being the first CoCo game to require 64K, so if it runs … you have 64K and not just 32K.
But loading up a large program just to do a memory test isn’t the efficient way to do a memory check (even if it is the most fun way).
The second method is to run a short BASIC program that attempts to copy the BASIC ROMs in to RAM. If it works, and you can POKE to the BASIC ROM locations and change things, it proves you have 64K.
This test is convenient because it can be done by typing in a very short program in BASIC, rather than needing a way to download and transfer a tape or disk image of Sailor Man over to a CoCo.
In part 2, I’ll discuss several implementations of this “ROM to RAM” program, and then present a super simple 64K test program.
In the first part, the following Color BASIC program was shared:
5 CLEAR 100*255
10 MX=99
20 DIM A$(MX):AL=0:DL=-1
30 SZ=RND(255):SZ=255
40 A$=STRING$(SZ,"X")
50 GOSUB 1000:GOTO 30
999 END
1000 REM
1001 REM ADD NEW STRING
1002 REM
1010 IF AL=DL THEN GOSUB 2000
1020 GOSUB 3000:IF Z<1024 THEN GOSUB 2000
1030 PRINT "ADDING";LEN(A$)"BYTES AT";AL;Z
1040 A$(AL)=A$
1050 AL=AL+1:IF AL>MX THEN AL=0
1060 IF DL=-1 THEN DL=0
1070 RETURN
2000 REM
2001 REM DELETE OLD STRING
2002 REM
2010 PRINT ,"DELETING";DL
2020 A$(DL)=""
2030 DL=DL+1:IF DL>MX THEN DL=0
2040 GOSUB 5000
2050 RETURN
3000 REM
3001 REM GET FREE STRING SPACE
3002 REM
3010 Z=(PEEK(&H23)*256+PEEK(&H24))-(PEEK(&H21)*256+PEEK(&H22))
3020 RETURN
5000 REM
5001 REM PAUSE
5002 REM
5010 PRINT"[PAUSE]";
5020 IF INKEY$="" THEN 5020
5030 PRINT STRING$(7,8);:RETURN
The program allocates enough string space to hold 100 strings of 255 bytes each. It then starts adding line after line until it detects string memory is getting low. When that happens, the oldest line is deleted (set to “”). The process continues…
The “gut feeling” was that this program should have been able to hold 100 full sized strings, but since it did use a temporary A$ (created to be 255 strings line, and the string we would be adding to the array), it seemed logical that it would have to start purging lines maybe a few entries before the end.
But instead, it starts deleting lines at around entry 47. And, the memory usage being printed out shows it drops by 510 byes each time instead of 255.
510 is an interesting number. That is 255 * 2. That makes it seem like each time we add a 255 byte string, we are using twice that memory.
And we are!
Strings may live again to see another day
The key to what is going on is in the main loop starting at line 30. We create a new A$ and set it to a string of 255 X’s. That string has to be stored somewhere, so it goes in to string memory. Then we do the GOSUB and add a string to the array, which copies our A$ in to the array A$(AL) entry.
When we go back to 30 for the next round, we create A$ again. The old copy of A$, in string memory, is deallocated, and a new A$ is created at the current string memory position. BASIC does not see if the old string space is large enough to be re-used. It just moves on to a new allocation of string space.
It looks like this… And note that strings fill from the end of the memory and move lower. Let’s say we have 16 bytes of reserved string memory (just to keep things fitting on this screen).
FRETOP points to where reserved string memory begins. MEMSIZ is the end of string memory. If we had done CLEAR 16, then FRETOP would be MEMSIZ-16.
STRTAB is where the next string will be added. It looks like this:
Later in the code, we assign that to the array, such as A$(0)=A$. Now A$(0) gets a copy of A$, and it looks like this (using lowercase ‘x’ to represent the copy of A$ that was put in A$(0)):
When we go back to do this again, a new A$ is created, and it gets stored next. The old string data is still there, but A$ has been updated to point to the new entry.
…and so on. As you can see, the way this loop was written, it is creating a new A$ every time through, copying it to the array (a new entry for that) and so on. That is why we see 510 each time through instead of just 255.
Now, if the string was short, we could have done A$=”XXXXXXXXXXXXX”. If we did that, the string would exist in program space and not in string memory. But we wanted a 255 byte string, and you can’t type a line that long in BASIC so STRING$() was used instead, which requires putting the string in string memory.
However, since in THIS version we are just using the same 255 character A$ over and over again, let’s make one change so we don’t create it every time through the loop. Just change the GOTO 30 in line 50 to be GOTO 50:
Now the program will create one A$, which will store at the start of string memory, and then loop over and over just making new entries in the array.
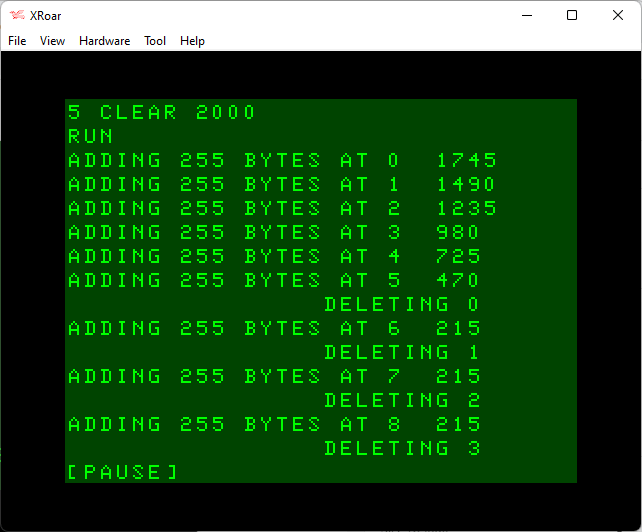
That small change will instantly change the results to be more like we might have expected. Now we get all the way to entry 94 before any string deleting happens:
And, from looking at that screen, each number is dropping by 255 bytes as we expected.
By the time it reached line 94, it saw that there were less than 1024 bytes of free string space left. 1024 would have held another four 255 byte strings, meaning actually had enough memory to have gotten to line 98 — just one line short of our max 99 before it rolls over. And that memory is where the initial 255-byte A$ is stored.
Tada! Mystery solved.
But wait! There’s more…
The reason I chose 1024 as a threshold was to allow for other temporary string use in the program. Things like LEFT$, MID$, STRING$ all make temporary strings. When you add two strings together it creates a third string that combines the first two. Be sure to check out my string theory article for more details on this — I learned quite a bit when researching it. I also learned that some things required strings that I did not expect to. Fun reads. Helps put you to sleep.
If I modify line 1020 to check for 255 bytes remaining instead of 1024, then re-run, I get this:
…and that is as perfect as it gets. Array is filled with strings 0-98, plus the temporary string, which is a total of 100 strings of 255-bytes each — and that is how much memory we set aside with CLEAR!
Now how much would you pay?
And because this program is self-aware when it comes to knowing how much string space is there, it can actually operate with much less string space. It will just delete old strings sooner.
You can change the CLEAR in line 5 to something smaller, like 2000, and it will still work. But, 2000/255 is 7, so it has room for the A$ plus six array entries. I expect it would DELETE every 6 lines. Let’s try…
Bingo! After lines 0-5 (six lines) it deleted and old one, then since everything was now full, it had to delete every time it added something new.
And the point is…?
Well, let’s just say I wish I knew about this back in 1983 when I wrote my cassette-based Bulletin Board System, *ALLRAM*.
This program demonstrates Color BASIC’s string garbage collection. As strings are manipulated, string memory used will continue to grow until BASIC decides to clean up the string space and move things around a bit.
The program creates a string array and fills each entry up with string data. Using code that checks how much string space is remaining, it will delete old strings if string memory is low.
Watching it run reveals some curious things…
The Program
On an Extended or Disk BASIC system, you will need to do a PCLEAR 1 to get enough memory to run it.
Initialization
Line 5 – We CLEAR enough string space to hold 100 lines at their largest size of 255 characters. Note that when you use DIM to set an array size, it is base-0. Doing a DIM A$(99) gives you A$(0) to A$(99) — 100 elements. Thus, the CLEAR uses 100, but the DIM in the next line uses 99.
Line 10 – MX represents the maximum number of lines in the array.
Line 20 – DIM A$(MX) creates an array of 0-99 entries (100). AL is set to 0, and will be the line (array entry) we will ADD next. DL will be used to track the next line (array entry) we need to delete. DL is set to -1 for “nothing to delete yet.”
Main Loop
Line 30 – SZ is set to the length of the string we want to add. It has an unused RND at the start, but then SZ is hard-coded to 255. The program was designed to test random lengths of strings, but for this demo, we will be overriding that and making every string the maximum size.
Line 40 – GOSUB 1000 goes to a routine that will ADD a line. Then we GOTO 30 to create a new line and do it again.
Add New String subroutine
Line 1010 checks to see if the ADD line has caught up to the DELETE line. If it has, we GOSUB 2000 to handle deleting the delete line.
Line 1020 – GOSUB 3000 will return the amount of free string space in Z. If Z is less than 104, GOSUB 2000 is called to delete a string.
Line 1030 – It prints how long of a string is being added to which line, followed by the current free string space before the add.
Line 1040 – The string is added to the A$ array at position AL.
Line 1050 – AL (add line) is incremented by 1, moving it to the next line of the array. If AL is larger than the MX (max array entries), it will wrap around to entry 0.
Line 1070 – Returns.
Delete Old String subroutine
Line 2010 – Print which line is about to be deleted (set to “”).
Line 2020 – The A$ entry at position DL is set to “”, releasing the string memory it was using.
Line 2030 – DL (delete line) is incremented by one. If DL is larger than MX (max array entries), it will wrap around to entry 0.
Line 2040 – GOSUB 5000 is a pause routine so we can see what just happened.
Get Free String Space routine
Line 3010 – Z is calculated as the difference between the FRETOP (start of string storage) memory location and the STRTAB (start of string variables) in the reserved string area. This gives us how many bytes of unused string memory is available.
Line 2030 – Returns.
Pause subroutine
Line 510 – Print the message “[PAUSE]” with no carriage return at the end.
Line 5020 – If INKEY$ returns nothing (no key pressed), keep checking.
Line 5030 – Prints a string of 7 CHR$(8)s (backspace character) which will erase over the “[PAUSE]” prompt.
Based on the intent, one might think that running this would fill strings up to around entry 100, and then it would start deleting the old string
But is that what it will do?
Let’s run it and find out.
5 CLEAR 100*255
10 MX=99
20 DIM A$(MX):AL=0:DL=-1
30 SZ=RND(255):SZ=255
40 A$=STRING$(SZ,"X")
50 GOSUB 1000:GOTO 30
999 END
1000 REM
1001 REM ADD NEW STRING
1002 REM
1005 IF AL=DL THEN GOSUB 2000
1006 GOSUB 3000:IF Z<1024 THEN GOSUB 2000
1010 PRINT "ADDING";LEN(A$)"BYTES AT";AL;Z
1020 A$(AL)=A$
1030 AL=AL+1:IF AL>MX THEN AL=0
1040 IF DL=-1 THEN DL=0
1050 RETURN
2000 REM
2001 REM DELETE OLD STRING
2002 REM
2010 PRINT ,"DELETING";DL
2020 A$(DL)=""
2030 DL=DL+1:IF DL>MX THEN DL=0
2035 GOSUB5000
2040 RETURN
3000 REM
3001 REM GET FREE STRING SPACE
3002 REM
3010 Z=(PEEK(&H23)*256+PEEK(&H24))-(PEEK(&H21)*256+PEEK(&H22)):RETURN
5000 REM
5001 REM PAUSE
5002 REM
5010 PRINT"[PAUSE]";
5020 IF INKEY$="" THEN 5020
5030 PRINT STRING$(7,8);:RETURN
Running the Program
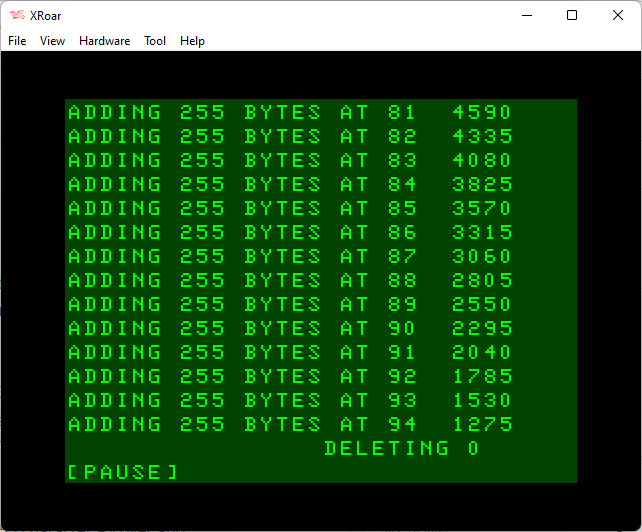
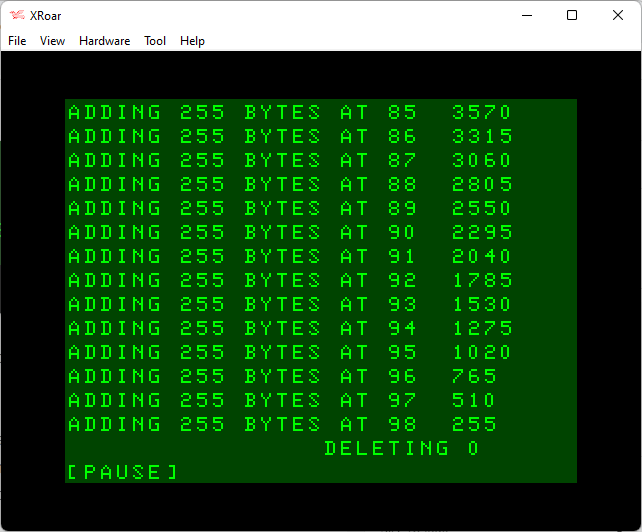
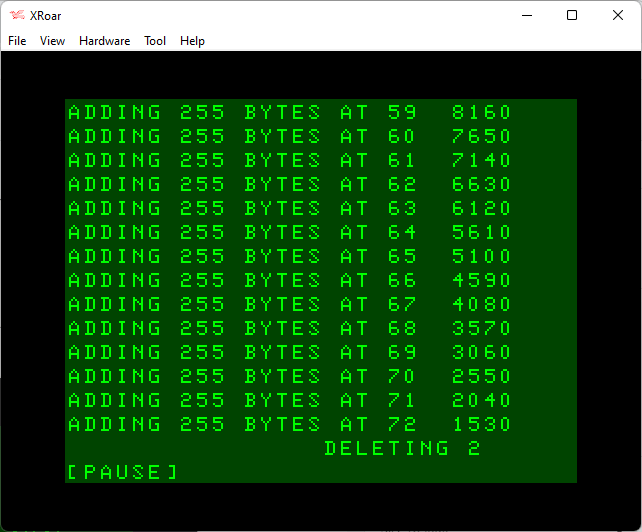
After a PCLEAR 1 and RUN, the program starts filling lines and we can see string memory going down. When it gets to line 47, there is only 1275 bytes of string space left.
And if we check those values, the difference between each one isn’t the 255 we might have expected. We clearly added a new 255 byte string, but memory went from 7905 to 7395 (510 bytes less) and continued down to 1785 to 1275 (510 bytes less). It appears each time we add a 255 byte string, it takes 510 bytes of string memory.
As we get to line 47, we must have had less than 1024 bytes of string memory left and the DELETE LINE subroutine is called. It deletes the oldest line, which is currently line 0. That should free up 255 bytes of string memory.
After pressing a key, we see the next few entries:
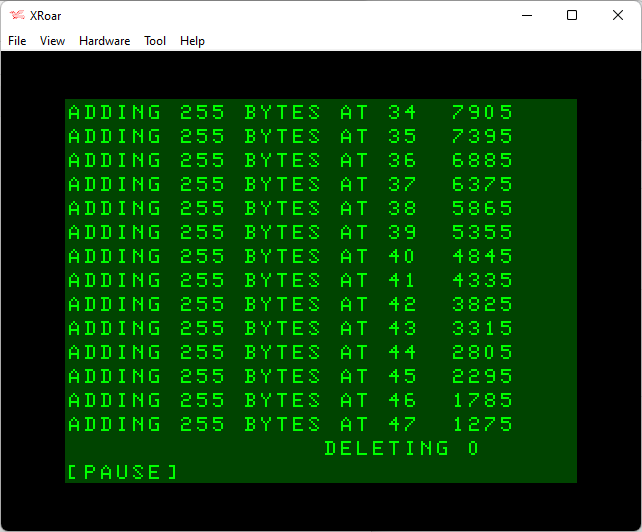
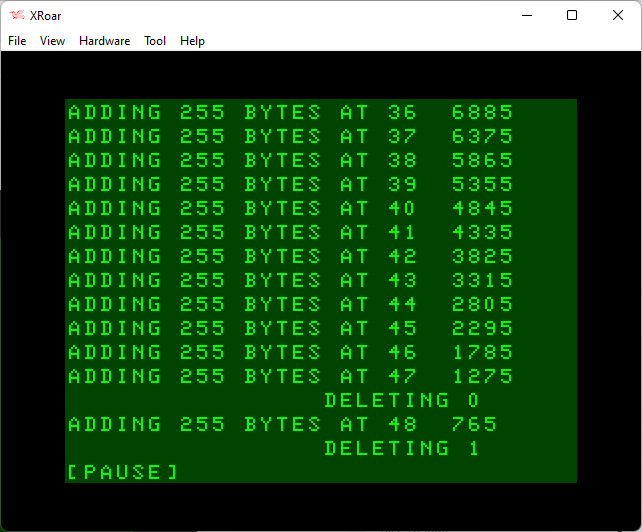
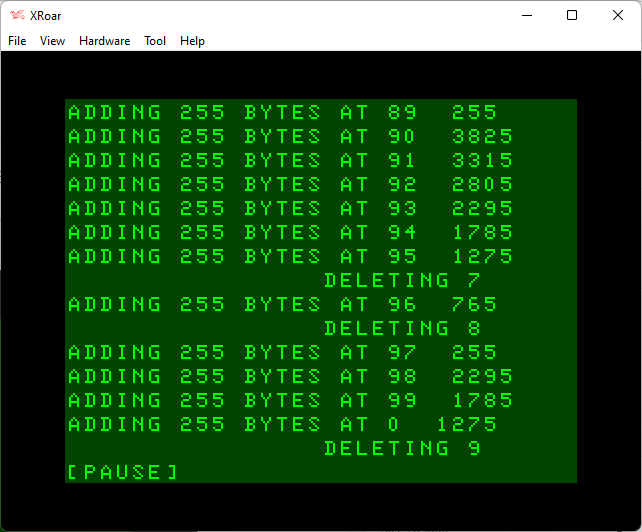
After deleting 0, memory has gone from 1275 to 756 (5120 bytes), so DELETE is called again. This time it deletes line 1.
We press a key and let it scroll a bit more until the next DELETE:
Here we see that, at some point, some string cleanup was done and our free string space grew larger. The trend of reducing by 510 bytes for each ned 255 byte string added continues…
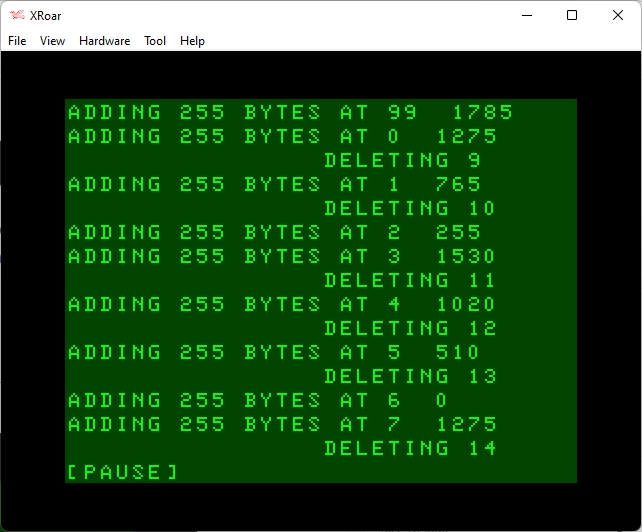
And the process repeats, until eventually we roll over at line 99.
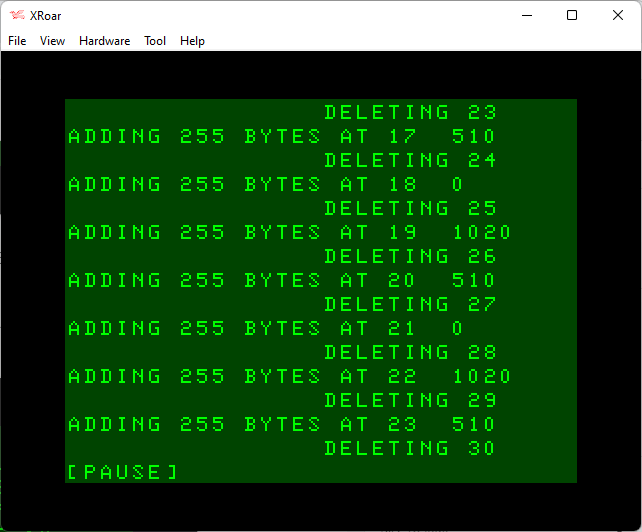
From here on, things get a bit more predictable, with a DELETE happening almost every line — though sometimes every two lines.
Eventually things settle in to a pattern of basically DELETING for every line ADDED.
Is it broken? Is it just poorly implemented? Or is it behaving exactly like it is supposed to?
After migrating from Perforce to Git (BitBucket, in our case) at work, I learned that Git does not support any embedded source code keywords for replacement on check in. In our case, we use things like:
On Submit, Perforce will replace those keywords with useful information, such as the username ($Author$) that did the submit, the data and time of the submit ($DateTime$) and the filename ($File$). I find this very useful when looking at source code outside of Perforce, since it tells me how new or old the code is. (Anyone who’s ever had to print out a ton of code for a group code review knows how easy it is to end up looking at the wrong version of the file… Usually not discovered until someone finds a bug you know you already fixed ;-)
Since Git does not support this, I wanted to at least search/replace “$File$” to be the actual filename of the source file. I am sure there are many ways to do this, but I ended up using a PowerShell script, based on code I found some web searches (probably on Stack Exchange or similar):
In this case, this code specifically targets “.h” files at or below the directory you run the script in. I expect you can make a multi-filter that does .c and .h at one time, but I only needed to do this once so I ran it like this, then edited the “*.h” to be “*.c” and ran it again. (You’d change it to whatever your source file extensions are, like .cs or whatever.)
The [system.io.file] tip came from someone who noticed the other output would always add a blank line at the end of the file. This method re-writes the file as-is.
WARNING: I did notice that some files get messed up if they contain special characters. It would put some garbage (when viewing in a text editor) in place of things like weird apostrophes and such, so if you use this, make sure to diff your files before checking them back in and revert any goofs that “-replace” causes. I had to revert about one dozen blocks in my code.
I also had to run a command to grant my Windows 11 machine permission to even execute a PowerShell script.
Hope this helps someone else, and saves them a few hours of research…
The new InstaX3 was announced on 9/8/2022, and made instantly available on Amazon. It shipped with beta firmware, but had a 1.0.00 update available to install during activation.
If you have found any bugs, please leave a comment with the version and details and I will add them to this list. As workarounds are discovered, I will update this list.
As a new version of firmware is released, these bugs will be re-tested. When they work for some, and not for others, a note will be added to that effect.
Initially, the camera shipped with pre-1.0.00 beta software. It would prompt to upgrade to 1.0.00 on activation from the app.
2022-9-9 – v1.0.00
TBA – various crashes, settings being changed, etc.
2022-09-19 – v1.0.04
TBA
Open WiFi – a poorly implemented WiFi system has the camera broadcast itself as a WiFi hotspot to anyone within range, and allows users that know the default WiFi password all X3 cameras have to access and download any files on the memory card from a web browser… or worse. (Suggested by commenter, yt)
Raw notes… will be cleaned up and made purty with more details, soon.
X3: up to 30 seconds between taking photos via app, and more timing notes.
Some notes on timing, for those who want to compare against your existing camera. This is with the current firmware that the camera will install when you activate it (v1.0.00). Recommended Sandisk Extreme 32GB card.
App (on iPhone 13 Pro):
360 Photo, 72MP, 2:1 – there is nearly 4-5 second delay between the time you press the on screen button and the time the X3 clicks. It takes a total of about 15 seconds before the UI updates and you can take the next photo.
360 Photo, 18MP, 2:1 – 4-5 delay, and a total of about 9 seconds.
360 HDR Photo – 3-4, then about 13 seconds total.
150 Photo, 36MP, 16:9 – 3-4, about 11 seconds total.
150 Photo, 9MP, 16:9 – 3-4, about 8 seconds total.
I did have one instance where it took almost 30 seconds to be ready for the next shot.
Camera Button:
Using the button on the camera is almost instant (within a second) and ready for the next photo in about 6-7 seconds total.
In 360 Photo mode, 72MP, pressing the button on the camera makes the click sound between 2-3 seconds later, and it takes a total of 14 seconds before the screen comes back on for the next photo.
In 360 Photo mode, 18MBP, it takes about a second to take the picture, and a total of about 5-6 before you can take the next shot.
In 360 HDR Photo mode, 18MP, it takes about a second to take the picture, and a total of 9-10 seconds before you can take the next shot.
Some of this feels like the timer is on, which isn’t being shown in the app or on the camera. earlier, I used the Quick button and had selected that mode. It seems it may be remembering settings that have since been turned off.
This is just a (hopefully) short article following up on some tangents I went on while learning about Color BASIC string memory and VARTPR and other related (and nonrelated) items.
The story so far…
Color BASIC has reserved string memory that is located at the very top of the 32K that is accessible by BASIC. There are three 16-bit pointers maintained by BASIC that contain the starting address for this memory, the address where the next string will be inserted (sorta), and the end of this memory.
The Color BASIC Unraveled book called them FRETOP, STRTAB and MEMSIZ.
You can get the address in BASIC by using PEEK(x)*256+PEEK(y) with these memory locations:
FRETOP – 33 and 34
STRTAB – 35 and 36
MEMSIZ – 39 and 40
When digging in to this, I noticed the the MEMSIZ location returned on a 32K CoCo was 32766, and on a 16K it was 16382, and on a 4K CoCo it was 4094. The actual last byte of RAM was one byte higher (32767, 16383, and 4095), making me wonder if this was a mistake.
Indeed, when I checked on a CoCo 3, which had newer patches to BASIC done by Microware, the 32K value “correctly” reported 32767 as would have expected.
… That missing byte is needed so VAL can work on a string stored at the very top of string space. It needs to temporarily put a NUL byte after the string so the number parser knows when to stop. After executing, VAL restores the byte to its original value. Things would fail if the byte after the string data was ROM though. On the Coco3, that byte is in RAM so it didn’t need an extra reserved byte. I suspect, however, that Microware didn’t know that, or thought it was a bug in the original, or just didn’t notice when they replaced the now useless memory scan with a simple LDX. So, it’s not a bug in the original ROM and, accidental or not, … the behavior on the Coco3 [is] also correct.
– William Astle, 7/14/2022
This led me back to the ROM disassembly, where I did indeed locate where the VAL command will load a byte, store 0 there, then restore the original value later.
Color BASIC Unraveled, page B38.
Prove it or lose it.
Since Man cannot code on faith alone, Art “ADOS” Flexser provided a simple way to prove this to be true:
You can demonstrate the need for the extra byte on a 32/64K CoCo 1/2 by the following:
Change the top of string space to $7FFF rather than the usual $7FFE by POKE 40, 255:CLEAR, upping the LSB of MEMSIZ by one.
Then try PRINT VAL(“&H5”) and you get the rather surprising answer of 94! Why 94? Because that’s decimal for hex 5E, and the “E” has arisen from the first byte of Extended Basic at $8000.
On a CoCo 3, the top of string space is already at $7FFF, so you just need to put it into ROM/RAM mode with POKE&HFFDE,0 before entering PRINT VAL(“&H5”) to get the answer of 94.
Art Flexser, 7/17/2022
And there you have it — the reason why MEMSIZE is not actually pointing to the end of usable BASIC memory on a CoCo 1 or 2, and why it still works on a CoCo 3 after being changed to actually point to the end of usable BASIC memory.
The more you know …
Thanks, William and Art. Your knowledge is greatly apprecaited.
From the “wish I knew then what I (almost) know now” department..
On the Color Computer, the first 1K (1024 bytes) of RAM is reserved for the BASIC ROM code to use. In this article, we will look at some memory locations that pertain to our BASIC code, variables, arrays and strings.
Here are the locations as described in the Color BASIC Unraveled book:
Color BASIC Unraveled, page A1.
Each location contains a 16-bit number which is the address in memory of that information. Here are the values we are interested in, translated to decimal:
TXTTAB – 25 and 26
VARTAB – 27 and 28
ARYTAB – 29 and 30
ARYEND – 31 and 32
FRETOP – 33 and 34
STRTAB – 35 and 36
MEMSIZ – 39 and 40
To turn two bytes in to the 16-bit address, we take the PEEK of the first byte, multiply it by 256, then add the PEEK of the second byte. For TXTTAB (Beginning of BASIC program) we would do:
PRINT PEEK(25)*256+PEEK(26)
That value returned will be different depending on the configuration of the Color Computer.
Let’s dig in to what each of these locations means.
TXTTAB: Beginning of BASIC program – 25/26 (&H19/&H1A)
This location represents where in RAM the BASIC program starts.
PRINT PEEK(25)*256+PEEK(26)
On a CoCo with only Color BASIC (no Extended or Disk BASIC), storage for a BASIC program will be right after the 512 bytes of screen memory. The CoCo’s screen is stored at 1024 to 1535, so BASIC programs load at 1536.
START END SIZE DESC
----- ----- ----- --------------
0 1023 1024 ROM USE
1024 1535 512 TEXT SCREEN
1536 32767 31232 BASIC PROGRAM
With Extended BASIC added, some RAM after the text screen is used for high resolution graphics screens. By default, 6K is reserved on startup, but more or less can be specified using the PCEAR command. Since the smallest graphics screen using 1.5K (1536 bytes), allocation is done in multiples of that size. Thus, on startup, Extended BASIC has four 1.5K pages reserved for graphics. This means BASIC would start at 7668 on a CoCo with Extended BASIC.
START END SIZE DESC
----- ----- ----- --------------
0 1023 1024 ROM USE
1024 1535 512 TEXT SCREEN
1536 7679 6144 HI-RES GFX
7680 32767 25088 BASIC PROGRAM
With Disk BASIC, there is an additional 2K of RAM used just after screen memory at 1536, with the high resolution graphics screens after that.
START END SIZE DESC
----- ----- ----- --------------
0 1023 1024 ROM USE
1024 1535 512 TEXT SCREEN
1536 3583 2048 DISK ROM USE
3584 9727 6144 HI-RES GFX
9728 32767 23040 BASIC PROGRAM
NOTE about “START”: As I calculated this, I see that the starting location for BASIC is actually one byte higher than I expected. On a 4K CoCo, I expected BASIC to start at 1536, but PEEK(25)*256+PEEK(27) shows 1537. On an Extended BASIC CoCo, those peeks show 7681 instead of 7680. And on a Disk BASIC system, they show 9729 instead of 9728. I am not sure why it is off by one, but I’m sure someone smarter than I will have the answer in a comment.
NOTE about “END”: You will notice in my table the end location for BASIC is listed as 32766. That would only be true if the machine has 32K or 64K. If the machine had only 4K or 16K, it would be less. (Basically, MEMSIZE – START OF BASIC PROGRAM). And then it’s also off by by one byte for some reason (4094 on a 4K machine, 16382 on a 16K machine, and 32766 on a 32K machine). I’ll have to look in to this. Maybe I’m the one who is off…
NOTE about BASIC Memory: You may note I just said a 32K and 64K CoCo will show the same location for the end of BASIC memory. This is because reasons. See this article for a discussion about getting the most memory for BASIC, or just read this excerpt:
64K NOTE: The reason BASIC memory is the same for 32K and 64K is due to legacy designs. The 6809 processor can only address 16-bits of memory space (64K). The BASIC ROMs started in memory at $8000 (32768, the 32K halfway mark). This allowed the first 32K to be RAM for programs, and the upper 32K was for BASIC ROM, Extended BASIC ROM, Disk BASIC ROM and Program Pak ROMs. Early CoCo hackers figured out how to piggy-pack 32K RAM chips to get 64K RAM in a CoCo, but by default that RAM was “hidden” under the ROM address space. In assembly language, you could map out the ROMs and access the full 64K of RAM. But, since a BASIC program needed the BASIC ROMs, only the first 32K was available.
Note the use of parenthesis around each calculation. I was originally not using them, and was getting bad results because I made, as William Astle noted, “an elementary arithmetic error.”
Math is hard. Just ask Barbie.
Variable Table
The variable table is a series of 7 byte entries. The first two bytes are the variable name.
Variable Name (bytes 1 and 2) – If a variable is “LN”, the first two bytes would be “LN”. But, if the variable is a string such as LN$, the first byte would be “L” and the second byte would be the value of “L” + 128 (high bit set).
Variable Value (bytes 3-7) or String Descriptor (bytes 3, and 5-6)
If the variable is a number, the next five bytes are a floating point representation of the value.
If the variable is a string (high bit of the second name byte is set), the five bytes will be a string descriptor entry that contains the size and location of the string data bytes. A string descriptor only uses three of those five bytes. The first byte will be the length of the string (0-255), the next byte is unused, then the third and fourth bytes are the address of the string data in memory (located in reserved string space, to be discussed later in this article).
Here is a short program that will print out all the variables. The variables MUST be declared before this code runs. If any new variables are created inside the FOR/NEXT loop, it will not work as expected since the table will have been changed.
0 ' SHOWVARS.BAS
5 DIM VS,VE,L,VN$
10 VS=PEEK(27)*256+PEEK(28)
20 VE=PEEK(29)*256+PEEK(30)
30 FOR L=VS TO VE-5 STEP 7
40 VN$=CHR$(PEEK(L))+CHR$(PEEK(L+1) AND 127)
50 IF PEEK(L+1) AND 128 THEN VN$=VN$+"$"
60 PRINT VN$;
70 FOR I=0 TO 4
80 PRINT TAB(5*I+6);PEEK(L+2+I);
90 NEXT:PRINT
100 NEXT
Running this will show a list of all the variables in use, and the five bytes after the name.
Above, the VN$ entry shows that it is a 3 byte string located in memory at location 127*256+236 (32748). More on this later in the article.
You can test this code further by declaring more variables before line 10, such as with the DIM statement, or just adding declarations like A=42 or ZZ$=”TOP”.
6 DIM A,B,C,D,A$,B$,AB$,ZZ$
7 AB$="ABBA":ZZ$="TOP"
ARYTAB: Start of Arrays – 29/30 (&H1D/&H1E)
This location represents where arrays will be stored.
PRINT PEEK(29)*256+PEEK(30)
And if we know the start…
ARYEND: End of Arrays (+1) – 31/32 (&H&1F/&H20)
And this location represents where arrays end (though it returns one byte past the last entry of the arrays).
PRINT PEEK(31)*256+PEEK(32)
Arrays
This part gets a bit complicated and messy, so unless you plan on doing stuff with arrays, feel free to skip this section completely… :)
Arrays get stored in their own block of memory. Each array entry starts with a 5-byte header that contains the name of the array (2-bytes), the length of the array (2-bytes) and how many dimensions the array is (1-byte). It looks like this:
ARRAY TABLE ENTRY HEADER (5 bytes)
--------------------
[ ][ ][ ][ ][ ] - numeric array "NM"
N M AB CD #D - ABCD = memory used (header to end)
#D = number of dimension
DIM(X)=1 DIM(X,Y)=2
This is followed by one or more 2-byte entries that contain the dimension size for each dimension. A one dimensional array such as DIM X(10) would have two bytes representing 11. Remember that in BASIC, DIMensions are base 0. DIM X(10) gives you X(0) through X(10) for a total of 11 entries.
Since an array has to have at least one entry, the header will really always have at least 7 bytes. Here is an example for a two dimension array like DIM X(10,20)
ARRAY TABLE ENTRY HEADER (5 bytes + at 2 bytes per each dimension)
------------------------------------
[ ][ ][ ][ ][ ][ ][ ][ ][ ]- numeric array "LN"
N M AB CD #D D1 D1 D2 D2 - ABCD = memory used
- #D = number of dimensions
- D1D1 = number of dimension 1 entries
- D2D2 = number of dimension 1 entries
And, dimensions are backwards from how they are entered in BASIC. If you had this:
DIM AB(1,2,3,4)
You would have an array table entry that would be 15 bytes and look like this:
[65][66] [xx][xx] [4] [0][5] [0][4] [0][3] [0][2] [0][1]
[65][66] - name "AB"
[xx][xx] - total bytes used from header to end
[4] - four dimensions
[0][5] - DIM (x,x,x,4)
[0][4] - DIM (x,x,3,x)
[0][3] - DIM (x,2,x,x)
[0][2] - DIM (1,x,x,x)
After each header are a series of 5-byte entries (one for each element in the array) in the same format as variables – either 5-bytes representing a floating point number, or 5-bytes that make up the string descriptor (size and location of string data).
The blocks of entries are in the order listed in the array table. i.e, if you have DIM(1,2) you will first have 3 5-byte entries for the second dimension DIM(x,2) followed by 2 5-byte entries for the first dimension DIM(1,x).
I think.
Here is a program that shows the Array Table:
0 ' SHOWARRAYS.BAS
5 DIM SA,EA,L,AN$,I,AL
6 DIM X(1),Y(10),XY(2,3),ZZ(10,15,20),A$(10),UL$(10,3)
10 SA=PEEK(29)*256+PEEK(30)
20 EA=PEEK(31)*256+PEEK(32)
30 IF SA=EA THEN PRINT "NO ARRAYS":END
40 PRINT "ARRAYS FROM";SA;"TO";EA
45 PRINT "NAME TSIZE DIM .. .. .. .."
50 L=SA
60 AN$=CHR$(PEEK(L))+CHR$(PEEK(L+1) AND 127)
70 IF PEEK(L+1) AND 128 THEN AN$=AN$+"$"
80 PRINT AN$;
90 AL=PEEK(L+2)*256+PEEK(L+3)
100 PRINT TAB(4);AL;
110 PRINT TAB(11);PEEK(L+4);
120 FOR I=0 TO PEEK(L+4)-1
130 PRINT TAB(14+I*4);PEEK(L+5+I*2)*256+PEEK(L+5+I*2+1);
140 NEXT:PRINT
150 L=L+AL:IF L<EA THEN 60
And, with a bit of work, a program could be written to dump the 5-byte entrees for each array. I’ll add that to my “TODO” list…
FRETOP: Start of String Storage – 33/34 (&H21/&H22)
This location represents where reserved string memory begins. String space is reserved using the CLEAR command, with 200 bytes allocated by default. Strings are stored at the top of memory. Thus, on startup, this should print 200 bytes less than the end of BASIC memory:
PRINT PEEK(33)*256+PEEK(34)
If you change the amount of reserved string space, this number will change accordingly. Here we start out with 200 bytes reserved for strings, then change that to 0 bytes, then to 500 bytes:
If you wanted to know how much room is available for a BASIC program plus variables, you could take this value and subtract the start of BASIC location:
However, there is still some extra overhead so this value won’t match with what PRINT MEM shows. I guess it’s better to just PRINT MEM:
Maybe we’ll figure out what those “missing” 17 bytes are being used for.
STRTAB: Start of String Variables – 35/36 (&H22/&H24)
This location represents where the next string will be stored. Sorta.
PRINT PEEK(35)*256+PEEK(36)
Didn’t we just cover this? Not exactly. FRETOP shows where the string memory starts, but strings are actually stored from the top of memory, and grow downward. Meaning, if you have 200 bytes reserved, and place a ten byte string there (A$=”1234567890″), it will be located at the END of that 200 bytes, not at the start. This value points to where strings are stored within the reserved area.
If string memory were set to 16 bytes by using CLEAR 16, string memory would look like this:
At this point, we could add another one byte string, but anything longer would result in an ?OS ERROR (out of string space).
Here is a test program (and notice we are adding +”” to the end of each string. If that isn’t done, the string will be stored inside the BASIC program itself, and not in string memory.)
MEMSIZE should never move, as it is the highest memory location available to BASIC. FRETOP will move, depending on how many bytes are reserved for strings using the CLEAR command.
After the two strings in the previous example were added, it would look like this:
With these memory locations, we can determine how large a BASIC program is. We can detect how much string space is reserved, and calculate how much is being used or is free. We can figure out how much variable storage is being used, as well as array storage.
Most of these locations are never meant to be set by a program, but there is one exception. The CLEAR command can also be used to prevent BASIC from growing past a certain memory location. If you use a second parameter such as CLEAR 200,16000, it changes the MEMSIZ to that value.
The CLEAR command erases all variables, so there would be nothing for BASIC to relocate. Instead, this just changes MEMSIZE and adjusts the string values FRETOP and STRTOP and accordingly.
While it would be possible to manually POKE those six values and accomplish the same thing, there could always be unintended consequences. (But for fun, a BASIC program could be written that moves the string memory somewhere else, then POKEs the values to update it so BASIC keeps running.)
Conclusion
There might be some interesting things one could do by monitoring string space closely… Perhaps all the research I did for this article may be leading somewhere…
Until then…
BONUS CONTENT
Here is the program I used to calculate the tables in this article.