See also: part 1, part 2, part 3, part 4, part 5, part 6, part 7, part 8 and part 9.
Updates:
- 2/14/2017 – added section header.
INSTR and GOTO/GOSUB
Here’s a quickie that discusses making INSTR faster, and GOTO versus GOSUB.
Side Note: In the code examples, I am using spaces for readability. Spaces slow things down, so instead of “FOR A=1 TO 1000” you would write “FORA=1TO1000”. If you remove the unnecessary spaces from these examples, they get faster.
In the previous installment, I discussed ways to speed up doing things based on INPUT by using the INSTR command. INSTR will return the position of where a string is inside another string:
PRINT INSTR("ABC", "B")
2
Above, INSTR returns 2, indicating the string “B” was found starting at position 2 in the search string “ABC”. If the string is not found, it returns zero:
PRINT INSTR("ABC", "X")
0
You could use this in weird ways. For instance, if you wanted to match only certain animals, you could do something like this:
10 INPUT "ENTER AN ANIMAL";A$
20 A=INSTR("CATDOGCOWCHICKEN", A$)
30 IF A>0 THEN PRINT "I KNOW THAT ANIMAL!" ELSE PRINT "WHAT'S THAT?"
40 GOTO 10

…but why would you want to do that? And, it just matches strings, so any combination that appears in the search string will be matched:

Above, searching for “A” was a match, since there is an “A” in that weird animal string, as well as a “C”. There was no “B”, so…
Okay, nevermind. Forget I mentioned it.
I am sure there are many good uses for INSTR, but I mostly use it to match single letter commands (as mentioned previously) like this:
10 A$=INKEY$:IF A$="" THEN 10
20 LN=INSTR("ABCD", A$):IF LN=0 THEN 10
30 ON LN GOTO 100,200,300,400
Since INSTR returns 0 when there is no match, it’s an easy way to validate that the character entered is valid.
According to the documentation in the CoCo 3 BASIC manual, the full syntax is this:
INSTR(start-position, search-string, target-string)
You can use the optional start-position to begin scanning later in the string. For instance:
PRINT INSTR(3, "ABCDEF", "A")
That would print 0 since we are searching for “A” in the string “ABCDEF” starting at the third character (so, searching “CDEF”).
The manual also notes conditions where a 0 can be returned:
- The start-position is greater than the number of characters in the search-string: INSTR(4, “ABC”, “A”)
- The search-string is null: INSTR(“”, “A”)
- It cannot find the target: INSTR(“ABC”, “Z”)
I was surprised today to (re)discover that INSTR considers a null (empty) string to be a match, sorta:
PRINT INSTR("ABC", "")
1
If the search-string is empty, it returns with the current search-position (which starts at 1, for the first character). This seems like a bug to me, but indeed, this behavior is the same in later, more advanced Microsoft BASICs.
I bring this up now because I was almost going to show you something really clever. Normally, I use INSTR with a string I get back from INKEY$. But, you can also use INKEY$ directly. And, since ON GOTO/GOSUB won’t go anywhere if the value is 0, I thought it might be clever to use it like this:
10 ON INSTR("ABCD",INKEY$) GOTO 100,200,300,400
…and this is smaller and much faster and works great … if there is a key waiting! If no key is waiting, INKEY$ returns a null (“”) and … INSTR returns a 1, and then ON GOTO goes to 100 even though that was not the intent.
Darnit. I thought I had a great way to speed things up. Consider the speed of this version:

I thought by replacing line 30 with…
ON INSTR("ABC",INKEY$)GOSUB70,80,90
…I would be set. But, since an empty INKEY$ is returning “”, it’s always GOSUBing to line 70.
I tried a hacky workaround, by adding a bogus character tho the start of the string, and making that GOSUB to a RETURN located real close to that code (so it didn’t have to search as far to find it):

…but, the overhead of that extra GOSUB/RETURN that happens EVERY TIME there is no key waiting was enough to make it slightly slower. If it wasn’t for that, we could do this maybe 30% faster and use less variables :)
So, unfortunately, I guess I have no optimization to show you… Just a failed attempt at one.
But wait, there’s more!
I posted about this on the CoCo mailing list and in the CoCo Facebook group to figure out if this behavior was a bug. There were several responses confirming this behavior in other versions of BASIC and languages.
On the list, Robert Hermanek responded with a great solution:
Issue is just getting a return of 1 when searching for empty string? Then why not:
10 ON INSTR(” ABC”,INKEY$) GOTO 10,100,200,300
…notice the space before A.
-RobertH
His brilliant suggestion works by adding a bogus character to the search-string, and making any match of that string (or “”) GOTO the same line. Thus, problem solved!
This won’t work with ON GOSUB since every GOSUB expects a RETURN. Each time you use GOSUB, it takes up seven bytes (?) of memory to remember where to RETURN to in the program. If you did something like this, you’ll see the issue:
10 PRINT MEM:GOSUB 10
I make a quick change to my program to use GOTO instead:
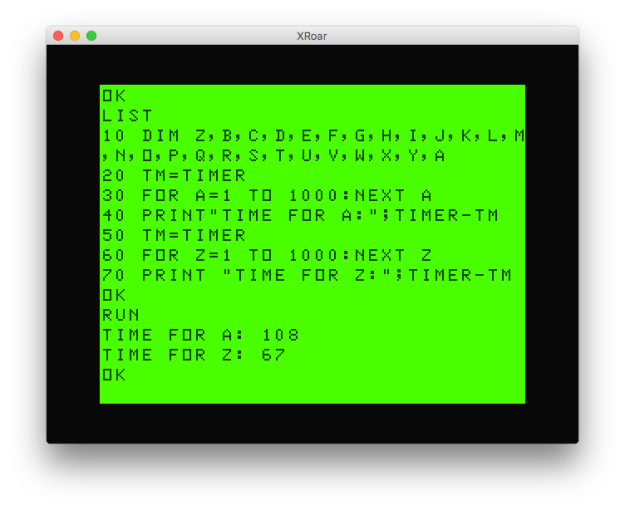
10 TIMER=0:TM=TIMER
20 FOR A=1 TO 1000
30 ON INSTR(" ABC",INKEY$) GOTO 40,70,80,90
40 NEXT
50 PRINT TIMER-TM:END
70 PRINT"A PRESSED":GOTO 40
80 PRINT"B PRESSED":GOTO 40
90 PRINT"C PRESSED":GOTO 40
For my timing test inside the FOR/NEXT loop, I made the first GOTO point to the NEXT in line 40, but if I wanted to wait “forever” until a valid key was pressed, I would make that 30.
This version shows a time of 412, so let’s compare that to doing it with A$:
10 TIMER=0:TM=TIMER 20 FORA=1 TO 1000 30 A$=INKEY$:IFA$="" THEN 40 ELSE ON INSTR("ABC",A$) GOTO 70,80,90 40 NEXT 50 PRINT TIMER-TM:END 70 PRINT"A PRESSED":GOTO 40 80 PRINT"B PRESSED":GOTO 40 90 PRINT"C PRESSED":GOTO 40
This produces 486. We now have a way to avoid using A$ and speed up code just a bit.
This made me wonder … what is faster? Using GOTO, or doing a GOSUB/RETURN? Let’s try to predict…
Both GOTO and GOSUB will have to take time to scan through the program to find the destination line, but GOSUB will also have to take time to store the “where are we” return location so RETURN can get back there. This makes me think GOSUB will be slower.
BUT, we need a GOTO to return from a GOTO, and a RETURN to return from a GOSUB. GOTO always has to scan through the program line by line to find the destination, while RETURN just jumps back to a location that was saved by GOSUB. So, if we have to scan through many lines, the return GOTO is probably slower than a RETURN.
Let’s try.
10 TIMER=0:TM=TIMER 20 FOR A=1 TO 1000 30 GOSUB 1000 40 NEXT 50 PRINT TIMER-TM:END 1000 RETURN
That prints 140.
10 TIMER=0:TM=TIMER 20 FOR A=1 TO 1000 30 GOTO 1000 40 NEXT 50 PRINT TIMER-TM:END 1000 GOTO 40
That prints 150.
I expect it is because line 1000 says “GOTO 40” and since 40 is lower than 1000, BASIC has to start at the top and go line by line looking for 40. If you GOTO to a higher number, it starts from the current line and moves forward. The speed of GOTO (and GOSUB) varies based on where the lines are:
GOTO should be quick when going to a line right after it:
10 TIMER=0:TM=TIMER 20 FOR A=1 TO 1000 30 GOTO 31 31 GOTO 32 32 GOTO 33 40 NEXT 50 PRINT TIMER-TM:END
That prints 170.
Line 30 has to scan one line down to find 31, then 31 scans one line down to find 32, and 32 scans one line down to find 40.
But if you change the order of the GOTOs:
10 TIMER=0:TM=TIMER 20 FOR A=1 TO 1000 30 GOTO 32 31 GOTO 40 32 GOTO 31 40 NEXT 50 PRINT TIMER-TM:END
…that prints 175.
It is the same number of GOTOs, but line 30 scans two lines ahead to find 32, then 32 has to start at the top and scan four lines in to find line 31, then line 31 has to scan two lines ahead to find 40.
If we add more lines (even REMs), more things have to be scanned:
0 REM 1 REM 2 REM 3 REM 4 REM 5 REM 6 REM 7 REM 8 REM 9 REM 10 TIMER=0:TM=TIMER 20 FOR A=1 TO 1000 30 GOTO 32 31 GOTO 40 32 GOTO 31 40 NEXT 50 PRINT TIMER-TM:END
We are now up to 192 and the one with the lines in order is still 170.
The more lines GOTO (or GOSUB) has to search, the slower it gets. So while MAYBE there might be a case where a GOTO could be quicker than a RETURN, it seems that even with a tiny program, GOSUB wins.
So … the question is, is the time we save doing the INKEY like this:
30 ON INSTR(" ABC",INKEY$) GOTO 40,70,80,90
…going to offset the time we lose because those functions all have to GOTO back, rather than using a RETURN?
If this was a normal “wait for a keypress” then it probably wouldn’t matter much. We are just waiting, so there is no time to save by making that faster.
If we were reading keys for an action game, the actual “is there a keypress?” code would be faster, giving more time for the actual program. But, every time a key was pressed, the time taken to get in and out of that code would be slower. I guess it depends on how often the key is pressed.
A game like Frogger, where a key would be pressed every time the frog jumps to the next spot, might be worse than a game like Pac-Man where you press a direction and then don’t press anything again until the character is at the next intersection to turn down.
I am not sure how I would benchmark that, yet, but let’s try this… We’ll modify the code so “” actually is honored as an action:
10 TIMER=0:TM=TIMER
20 FOR A=1 TO 1000
30 ON INSTR(" UDLR",INKEY$) GOTO 100,200,300,400,500
40 NEXT
50 PRINT TIMER-TM:END
100 REM IDLE LOOP
110 GOTO 40
200 REM MOVE UP
210 GOTO 40
300 REM MOVE DOWN
310 GOTO 40
400 REM MOVE LEFT
410 GOTO 40
500 REM MOVE RIGHT
510 GOTO 40
Now if no key is waiting (“”), INSTR will return a 1 causing the code to GOTO 100 where the background (keep objects moving, animate stars, etc.) action would happen. Any other value would go to the handler for up, down, left or right.
This prints 457. Doing the same thing with GOSUB:
10 TIMER=0:TM=TIMER
20 FOR A=1 TO 1000
30 ON INSTR(" UDLR",INKEY$) GOSUB 100,200,300,400,500
40 NEXT
50 PRINT TIMER-TM:END
100 REM IDLE LOOP
110 RETURN
200 REM MOVE UP
210 RETURN
300 REM MOVE DOWN
310 RETURN
400 REM MOVE LEFT
410 RETURN
500 REM MOVE RIGHT
510 RETURN
…prints 487. It appears GOSUB/RETURN is slower for us than GOTO here. But why? GOSUB seemed faster in the first example. Is ON GOSUB slower than ON GOTO?
Quick side test:
10 TIMER=0:TM=TIMER 20 FOR A=1 TO 1000 30 ON 1 GOSUB 1000 40 NEXT 50 PRINT TIMER-TM:END 1000 RETURN
That prints 249. GOSUB by itself was 140, so ON GOSUB is much slower.
10 TIMER=0:TM=TIMER 20 FOR A=1 TO 1000 30 ON 1 GOTO 1000 40 NEXT 50 PRINT TIMER-TM:END 1000 GOTO 40
…also prints 249, and GOTO by itself was 150. I am a bit surprised by this. I will have to look in to this further for an explanation.
But I digress…
We can still slow down GOTO. If we had a bunch of extra lines for GOTO to have to scan through:
0 REM 1 REM 2 REM 3 REM 4 REM 5 REM 6 REM 7 REM 8 REM 9 REM
…that will slow down every GOTO to an earlier number. With those REMs added, we have:
GOTO/GOTO version with REMs: 473 (up from 457 without REMs)
GOSUB/RETURN version with REMs: 487 (it never passes through the REMs)
It appears that, while GOSUB/RETURN may be faster on it’s own, when I put it in this test program, GOTO/GOTO is slightly faster, but that can change depending on how big the program is. More research is needed…
So I guess, for now, I’m going to avoid using a variable for INKEY$ and use GOTO/GOTO for my BASIC game…
Until next time…