Starting with that un-optimized version, I will change it to work on the CoCo 1/2/3’s 32-column screen by adjusting it to be properly centered on that display.
Unfortunately, this design is 17 rows tall, and the CoCo’s standard display is only 16. It won’t fit:
We should still be able to enter the challenge by having the program print this pattern, even if it scrolls off the screen a bit. To get one extra line there, we can get rid of the line feed at the end of the final PRINT statement in line 210 by adding a semi-colon to the end:
210 PRINT" * *";
And so it begins…
And so it begins
The goal is to make this as small as possible. There were many ways to approach last year’s Christmas tree challenge, and you can read about the results and a follow-up with suggestions folks gave to save a byte or two.
A simple thing is to remove the spaces at the front and replace them with the TAB() command:
Although this only looks like it saves a character per line (“TAB(8)” versus “seven spaces”), the code itself will be smaller since the TAB command tokenizes down to one (or maybe two?) bytes.
Also, the ending quote is not needed if it’s the last thing on a line, so they could be removed:
But, each line number consumes 5-bytes on it’s own, so a better way to save space would be to pack the lines together. Each line you eliminate saves five bytes. That would become pretty unreadable though, but let’s do it anyway:
This could still be made better, since the text lines were kept under the input buffer limitation size, but when you enter that line, BASIC compresses it (tokenizes keywords like PRINT, TAB and GOTO) making it take less space. You can then sometimes EDIT the line, Xtend to the end and type a few more characters.
That may or may not be allowed for the Logiker challenge. And since I want to provide code here you could copy and then load in to an emulator, I’ll keep it to the limit of what you could type in.
In the next installment, I’ll see if my brane can figure out a way to generate this code using program logic rather than brute-force PRINT statements.
A few years back, Color Computer community member Rietveld Rietveld took an Arcade1Up Rampage cabinet and converted it so I could run other software — such as emulators. Images have been shown of it running the Color Computer emulator and software.
Now, with the official 1.0 release of the NitrOS9 “Ease of Use”, that has been installed on this arcade machine and, by request, my OS-9 game Invaders09 has been ran on it.
I never imagined that my “arcade” game would eventually be running on a (sorta) arcade machine. Thanks, Rietveld!
The clear subroutine in this code is used to clear the screen and initialize it with a grid of green squares. The subroutine begins by loading the value 96 into the accumulator register A using the LDA instruction. This value represents the color value for green, which will be used to fill the screen with green squares.
Next, the LDX instruction is used to load the value 1024 into the X register. This value is the memory address of the top left corner of the screen, and it will be used as the starting point for the POKE operations that will be used to fill the screen with green squares.
The loop label marks the start of a loop that will be used to fill the screen with green squares. Inside the loop, the STA ,X+ instruction is used to store the value in the accumulator register A at the memory location pointed to by the X register, and then increment the X register by one. This has the effect of setting the value at the current memory location to the color value for green, and then moving to the next memory location on the screen.
The CMPX instruction is then used to compare the value in the X register to the value 1536. If the X register is less than 1536, it means that there are still memory locations on the screen that need to be filled with the color value for green. In this case, the BNE instruction is used to branch to the loop label, causing the loop to be repeated and the next memory location on the screen to be filled with the color value for green.
If the X register is equal to 1536, it means that all of the memory locations on the screen have been filled with the color value for green, and the loop can be exited. In this case, the BNE instruction will not be executed, and the RTS instruction will be executed, causing the subroutine to return to the main program. This completes the execution of the clear subroutine.
– ChatGPT AI
Now, it may have figured some of this out because I previously fed it a longer (and fully commented) bit of 6809 code that contained that routine as one of its several functions. That’s the only way I can see it knew the screen location and a green block.
Recently on LinkedIn, I saw a post by Rogelio Perea about his Tandy Model 102 portable computer. Although I never owned one, I remember this machine well. I always wanted one. Having a “portable” computer really wasn’t a thing back in those days, and this one even had a modem built in!
I recalled how, when I worked for Radio Shack, I wrote a program on our display Model 102 that we used to track our customer repairs. We had to have everything on paper in those days, but would type things in to the computer so we could find them quicker when a customer inquired about their repair status. I wish I had a copy, but I think the only place it ever existed was the memory of that specific computer.
I do, however, have the program it was based on. It started out as a PEN-PAL program for the Radio Shack Color Computer:
*ALLRAM* used BASIC arrays to store the userlog and message base in memory, and would load/save them to tape. My Pen-Pal program did the same thing, but was updated to load from either Tape or Disk.
That Pen-Pal program was also the basis for a custom program I wrote for a lady who ran a large newspaper route where I lived at the time. Her name was Laverne Ricks, and I remember this because I put it on the title screen of the program I wrote for her:
According to comments in the source code, I wrote this on 7/8/1987. This was the summer after I graduated high school, and I had just moved to Lufkin, Texas. Since this was before I got a job at Radio Shack, I am not sure how she and I got connected (possibly through the Lufkin Area CoCo Club or someone at Radio Shack).
The initial version of the program has a menu very similar to the Pen-Pal program:
You can see I had made it look a bit nicer by using graphical black block characters instead of rows of equal signs ;-)
I also found a second version, where I added built-in help:
THIS must be why I wrote the BASIC windowing routine I have written about before. It offered several screens of help:
Neat!
The program has ways to Add a new record:
Ah, the days before spell checkers. You should see the misspellings in my furniture store inventory program I did a year or so later… But I digress.
And you could use arrow keys to flip through them:
Y
You could Delete entries, Edit them, and Insert new ones (at the location you were currently viewing, which was important since a Paper Route was organized by delivery location rather than alphabetical or whatever). There was a way to Jump to a specific entry as well.
And, of course, you could Search by field:
Looking at it 35 years later, I’m pretty impressed with the features it offered. I have no idea what I based all of this on since I’d only owned a VIC-20 and a CoCo at that point and certainly had never worked with any kind of database software that I can recall.
Side note: A short while later, I would do something like this again for someone who ran a garbage collection route, though I think it was for a Tandy 1000 and was using a Deskmate Database.
This is what let me to search out Laverne Ricks and see where she was these days. Sadly, she passed away in 2011.
Earlier this month, I received a message on my Sub-Etha Software Facebook page from author (and former/current CoCo programmer) Carl England:
I knew CHR$(13) was a carriage return, so this was creating a file name that contained carraige returns. What would that do?
I typed it in to find out…
How appropriate, because the first thing I said when i saw this code was “weird.”
Of course, now I have a file on my disk that would be hard to delete. Carl said just doing:
KILL A$
…would take care of it. Provided, of course, you did that after running the program, while A$ still existed. Otherwise you’d have to manually type that line again and replace the SAVE with KILL.
Fun.
Character 8 is a backspace, so I could sorta see what this was doing. “TEST” then four backspaces, then a period, then three more backspaces?
Well.
Also weird.
I could have had so much fun with this trick back when I was swapping disks with friends.
Welcome back to the days when an IBM Compatible PC required a floppy disk just to start up. You would boot to PC-DOS (on an actual I.B.M. machine) or MS-DOS (for a clone, like the Tandy 1000 that had just come out in 1984 as the first PC compatible for under $1000). And … then what?
Just like there wasn’t much you could do with a PC with only a DOS boot disk, having just OS-9 is rather limited as well. Beyond typing some commands, what could you do?
There was a simple line-based text editor that would let you make text files. You could then “list” the text file and have that redirected to a printer, if you had one.
I guess you could say this was very limited word processing. Just without much word processing (though the EDIT command has search and replace functions).
There was also a 6809 assembler and debugger. You could write programs in 6809 assembly language.
And that was the very first time I ever wrote an OS-9 Level 1 assembly language program, and also the first time I ever used the asm assembler. I was more familiar with the rma assembler that came out for OS-9 Level 2 on the CoCo 3.
What else? Well, just like DOS, if you wanted to do more, you’d need software. Initially, Radio Shack didn’t sell anything for OS-9 other than BASIC09. Investing in that would allow someone who knew normal BASIC to start writing programs for OS-9. (I plan to do a “Converting Color BASIC to BASIC09” series at some point.)
But it was still neat.
Multi-User
Multi-user support is great, but if you only have one keyboard it won’t get you very far. But, OS-9 came with drivers for the CoCo’s banger RS-232 port, and also a “time sharing monitor” program that could monitor such serial port and then launch the “login” program if a terminal was hooked up to such serial port.
You could plug up an RS232 terminal to the CoCo’s serial port, and then launch “tsmon /t1 &” (the ampersand made the program run in the background so the shell prompt would return immediately). Now both you at the keyboard and another user via the serial port could be using the system at the same time. (Albeit at 300 baud.)
Cool.
If that terminal was another CoCo, then a remote login might look like this:
Above, I added a new entry to the PASSWD file for “ALLEN” with a password, and made new directories /D0/USERS/ALLEN. I set that login entry to point to that directory so when I logged in, I would have been changed in to /d0/USERS/ALLEN ready to make new files there.
It’s a bit more work than this to be useful, but that’s basically the idea. It was really a game changer compared to using BASIC in ROM.
Conclusion
So what could you do with this 1984 OS-9 Level 1? Write programs in assembly, or buy BASIC09 and write programs in that langauge.
However, since text-based OS-9 applications were compatible across hardware, there were actually existing OS-9/6809 programs that could run on the CoCo. Third party software specifically for CoCo OS-9 would soon follow, which was interesting because CoCo OS-9 could do graphics.
Since most of us will not have a 64K Radio Shack TRS-80 Color Computer laying around, as well as a disk drive and the original OS-9 floppy disks, I suppose running an emulator on your PC/Mac/Linux machine will have to suffice.
I personally use the XRoar emulator since I can run it on my Mac, Windows PC or Raspberry Pi. It allows me to emulate everything from a 1980 4K CoCo with Color BASIC 1.0, on up to a 512k CoCo 3. It has been invaluable in articles I have written, because I can quickly switch between Color, Extended and Disk BASIC systems of various versions using various amounts of RAM. There are other options available such as VCC for Windows, or the cross-platform MAME, but I do not know the specifics of how (or if) they can emulate an old 64K CoCo. (I think VCC is CoCo 3 only.)
Over at the Color Computer Archive, disk images have been preserved from the original V1.00.00 release of CoCo OS-9:
There was a later V1.01.00 update, and then an even later V2.00.00 update, but I want just just focus on what 1984 had to offer.
Inside that .zip file you will find two disk images:
OS9L1V1B.DSK – boot program (for Disk BASIC 1.0 users) and disk drive speed test utility.
OS9L1V1M.DSK – the actual OS-9 operating system itself, contained on this 156K 35-track single sided disk image.
As long as your CoCo or emulator is set to have 64K and Disk Extended Color BASIC 1.1, you can just mount the second one (OS9L1V1M.DSK) and then type “DOS” to boot in to OS-9. It will take awhile, since we are also emulating a slow floppy drive.
OS-9 Level 1 on a 64K Radio Shack TRS-80 Color Computer (emulated).
A “set time” utility is there asking for date and time — anyone here old enough to remember with early PCs all did the same thing as they booted to PC-DOS? Life before realtime clocks – the struggle was real!
Sadly, the set time utility is not Y2K compliant and will not let you enter “22” to mean 2022. You can type something like “22/7/27 8:58” but it will treat that as the year 1922.
22 means 1922. Sorry, folks living in 2022.
I should point out that, internally, it seems the clock code understood years past 2000 — but the utility did not allow you to enter them. If you set the time to just before midnight on December 31, 1999, then wait, you will see it rolls over from 1999 to the year of 19100:
From 1999 to 19100 in ten seconds flat!
The NitrOS9 project, which has created an open source update from the old OS-9, has fixed all these issues. Anyone interested in running OS-9 on a CoCo these days should be using that, but for this article, we will be sticking strictly with stock OS-9 as it existed in 1984. Which means maybe I should have entered the year to be 1984…
But I digress…
OS-9 Beginner’s Guide
I used to teach week-long courses on OS-9 for Microware, but we’ll keep this article much simpler and just look at commands and how the disk directories are set up.
As mentioned earlier, there is a “set time” utility, and in the previous screen shot you can see I used a command called “date” which will display the date. Typing it with the option of “t” added — “date t” — will display the date and add the time at the end.
If you type “dir” you will get a directory of the OS-9 disk:
OS9:DIR
DIRECTORY OF . 00:05:38
OS9BOOT CMDS SYS
DEFS STARTUP
Unlike Disk BASIC, OS-9 has a real file system that support longer filenames, upper and lowercase, subdirectories and much more. Since the CoCo VDG chip lacked true lowercase characters (lowercase existed, but would be displayed as inverted uppercase characters), by default CoCo OS-9 displays everything in uppercase even if the underlying text is using lowercase. You can type commands in upper or lowercase since the file system is not case sensative.
We see five filenames, but can’t tell if they are files or directories. There is a convention in OS-9 to make filenames lowercase, and directory names UPPERCASE. Since we can’t see the difference, we can use the option “e” on the dir command to display a longer listing:
OS9:DIR E
DIRECTORY OF . 00:08:28
CREATED ON OWNER NAME
ATTR START SIZE
==============================
83/06/02 1921 0 OS9BOOT
------WR A 3032
83/06/02 1956 0 CMDS
D-EWREWR 3C 620
83/06/02 2002 0 SYS
D-EWREWR 164 A0
83/06/02 2002 0 DEFS
D-EWREWR 17F C0
83/06/02 2003 0 STARTUP
----R-WR 15F E
Yuck! But we’ll get to what this means in a moment. You will see the screen pauses at the end. This is a feature built-in to OS-9 and it can be turned on or off. Press SPACE and you will see the listing continues, but there wasn’t anything left other than an empty line before returning to the “OS9:” command prompt.
Looking at that listing, if we made it expand to a wider display, it becomes much easier to understand. It might look like this on a 40 or 80 column OS-9 system:
DIRECTORY OF . 00:08:28
CREATED ON OWNER NAME ATTR START SIZE
=====================================================
83/06/02 1921 0 OS9BOOT ------WR A 3032
83/06/02 1956 0 CMDS D-EWREWR 3C 620
83/06/02 2002 0 SYS D-EWREWR 164 A0
83/06/02 2002 0 DEFS D-EWREWR 17F C0
83/06/02 2003 0 STARTUP ----R-WR 15F E
CREATED ON – The first column is the date (YY/MM/DD) and time (HHMM) the file/directory was created.
OWNER – The second column is the owner of the file/directory. OS-9 Level 1 is a multi-user system, and each user can have its own unique user number. 0 is reserved for the administrator (super user).
NAME – The third column is the file/directory name. OS-9 Level 1 allowed filenames to be up to 28 characters long, and use upper and lowercase. Spaces are not allowed, and there are some other restrictions, like files cannot start with a number and most special characters are not allowed. But still, far more advanced than DOS was.
ATTR – Attributes of the file. This is how we can tell if something is a file or a directory. There are eight attributes, and the first is D if it is a directory, or – if it is a file. We can skip the next one, and focus on the next two sets of 3 attributes. They are “EWR” — the first three are PUBLIC Execution (for binaries), Write (writeable), and Read (readable). The next three are the same but for the OWNER. Thus, you can have a file that ONLY the user can read, or everyone can read. You can make a file that only the user can write to, but the public can read but NOT write to. The same thing for directories. Private directories could exist, usable only by the owner, or public, that other users on the system could read and/or write to.
START – This is a hexadecimal value of what logical sector the file/directory starts at on the disk system. OS-9 splits a disk up in to logical sectors of 256-bytes each. We don’t need to worry about this.
SIZE – This is the file size, also shown in hexadecimal. We see the “startup” file is E (&HE to BASIC users, or 0xE to C programmers) long – 14 bytes.
Here are what those files are:
OS9BOOT – The OS-9 boot file, which contains the kernel, device drivers, etc. This will be all the files necessary to get the system up and running to the OS9: command prompt.
CMDS – We see that this is a directory. It contains various command line utility programs.
SYS – Another directory. This one contains system text files.
DEFS – Another directory. This one has definition text files used by the assembler/compiler and such.
STARTUP – This is a text file with public Read and owner Write/Read. It is basically AUTOEXEC.BAT for OS-9.
Let’s try the “list” command on the STARTUP file, which we know is 14 bytes long:
OS9:LIST STARTUP
SETIME </TERM
The contents of the file is displayed, much like using “cat” under Linux or “type” under MS-DOS. We see the contents is one line, “SETIME </TERM” and if we counted those characters, we’d get 13 characters. The file size is 14, because it contains those thirteen characters plus a carriage return at the end of the line.
By default, OS-9 will boot and then run whatever is in this STARTUP file. This allows us to customize things if we wanted to, or remove that set time prompt completely.
Let’s see what is in the various directories.
CMDS
OS9:DIR CMDS
DIRECTORY OF CMDS 00:26:46
ASM ATTR BACKUP
BINEX BUILD CMP
COBBLER COPY DATE
DCHECK DEBUG DEL
DELDIR DIR DISPLAY
DSAVE DUMP ECHO
EDIT EXBIN FORMAT
FREE IDENT LINK
LIST LOAD LOGIN
MAKDIR MDIR MERGE
MFREE OS9GEN PRINTERR
PROCS PWD PXD
RENAME SAVE SETIME
SHELL SLEEP TEE
TMODE TSMON UNLINK
VERIFY XMODE
There is quite a bit available! We see some commands that may look familiar — like DATE (show the date), DEL (delete a file), COPY (copy a file), DIR (directory), DELDIR (delete directory), ECHO (echo text), LIST (list a file), MAKDIR (make directory), RENAME (rename a file) and so on. OS-9 has a full file system with most of the standard commands you would expect.
If you have ever used “CHKDSK” on a PC or “fsck” on Linux, you will find OS-9 DCHECK familiar. If you have ever merged files on a Linux system, MERGE will be familiar.
OS-9 is very Unix-like in design, and with Linux being based on UNIX, it will have some familiar aspects to a Linux user.
We will explore these commands later, but let’s keep looking.
SYS
OS9:DIR SYS
DIRECTORY OF SYS 00:33:34
ERRMSG PASSWORD MOTD
Not much there. All three of these are text files.
ERRMSG – Contains a text listing of error messages (OS-9 will use an error number like ERROR #216, and this text file will show you that it means “PATH NAME NOT FOUND”.) You could type “LIST SYS/ERRMSG” if you wanted to see them all. You can also type the command PRINTERR to activate long error messages. Now instead of just getting “ERROR #216” it will be followed by the text description from the file. This will make error messages slower, though, since each time it will have to seek through the text file to find the entry and display it.
PASSWORD – As a multi-user system, OS-9 has a password file that can have entries for each user. You could create a password file with an entry for “admin” that would let them log in, change to the user’s “home” directory, and set their user ID to 0 (super user). Or you could make an entry for “bob” that sets his home directory somewhere else and makes him user 42, non-super user. Type “LIST SYS/PASSWORD” to see what is in there. You will see nothing is encrypted. Ah, those early days of operating systems! This file is used by the “login” command.
MOTD – Message of the Day text file. This file will be displayed to a user after they log in using the login command. We don’t see it because by default this OS-9 just boots directly to an OS9: command prompt.
DEFS
OS9:DIR DEFS
DIRECTORY OF DEFS 00:39:53
OS9DEFS RBFDEFS SCFDEFS
SYSTYPE
There are text files used by the 6809 assembler. They are sorta like .h header files in C. They contain various text definitions for bit values or whatever.
OS9DEFS – Definitions for the operating system.
RBFDEFS – Definitions for the “random block file” manager (disk).
SCFDEFS – Definitions for the “sequential character file” manager (console, serial ports, etc.)
SYSTYPE – Definitions for the system.
Unless we are programming for those, we would never use these files.
So what can we do?
In the next installment, we’ll explore some of the commands, and discuss some of the things that make OS-9 very unique (and the reason why it can run as a disk-based operating system, or completely out of ROM with no file system at all).
1984 was a big year for home computers. Not only was the Apple Macintosh released with that famous 1984 Superbowl ad, but Microware’s OS-9 operating system made a debut at Radio Shack.
Des Moines-based Microware had created a product called RT/68 for the Motorola 6800 processor. It was advertised in the February 1977 issue of Byte Magazine:
This led to them working for/with Motorola to create a high performance BASIC programming language for the Motorola 6809 processor. This led to them creating an operating system to support it. That operating system was called OS-9. (I assume the 9 was chosen because of the 6809 processor.)
I do not know the details of how it happened, but at some point Tandy/Radio Shack and Microware decided to bring out a version of OS-9 for the Radio Shack TRS-80 Color Computer. It was introduced in the 1984 Radio Shack catalogs, along with a 64K version of the Color Computer that was needed to run it. (OS-9 required 64K on the CoCo, but OS-9 itself could be embedded in ROM to run on industrial equipment with as little as 4K RAM.)
OS-9 was listed in the 1984 Radio Shack catalog, as well as the two 1984 Radio Shack Computer catalogs (RSC-10 and RSC-11):
Here is how the 64K version of the Color Computer was presented in the 1984 catalog:
And this is a how OS-9 was described in the short entry of the 1984 catalog:
At the time, I remember my Radio Shack salesman telling me OS-9 was needed to make full use of the 64K in my Color Computer. The Microsoft BASIC ROMs in the CoCo were limited to using less than 32K, regardless of if you had more than that installed in your machine.
The computer catalog went in to more details on both the machine and the operating system:
New 64K CoCo in the OS-9 in the Radio Shack Computer Catalog RSC-10OS-9 in the Radio Shack Computer Catalog RSC-10
I found it interesting that the same entry appeared in the second1984 computer catalog (RSC-11), but without the color. (I did not go through it word-for-word to see if there were any text changes, so let me know if I missed something.)
Radio Shack Computer Catalog RSC-11
Humble beginnings! Over the next few years, CoCo OS-9 offerings would continue to grow, adding compilers like C, and eventually a more advanced OS-9 Level 2 for the CoCo 3 with an optional mouse-driven GUI.
But in 1984, there was far less you could actually do with OS-9 except write programs for it in either 6809 assembly (notice the assembler was included) or the sold-separately BASIC-09. (It was actually just “BASIC09” in the documentation, without the dash.)
I thought it might be fun to boot up this original version of CoCo OS-9 and see what all it could do.
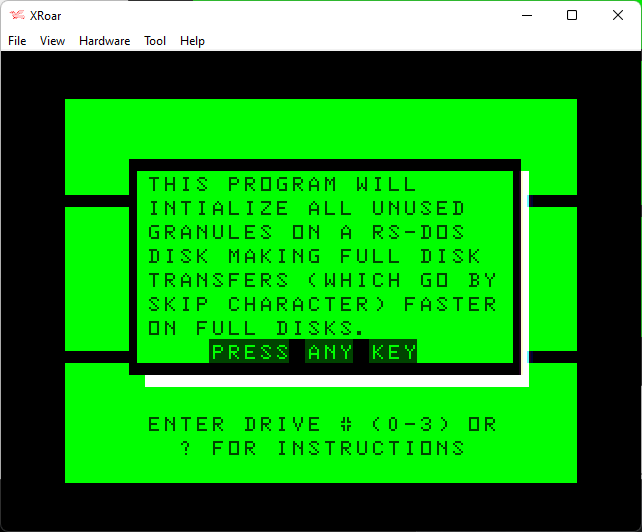
In 1987, I wrote a simple routine to display a pop-up window on the 32-column text screen of the CoCo. I am not sure what I wrote this for, but it appears I did use this routine (or a version of it) in my TIDY DISK program a year later:
Tidy Disk – help screen 1
It is sometimes interesting to look back on something I did 35 years ago and see how (or if) I would do it differently today. So let’s do that.
On the Color Computer Archive site is a disk image containing two versions of this routine. The first was done on 8/8/1987, and it looks like a 1.1 was created the next day. I am pleased to see I was retaining versions back then.
Using the wonderful toolshed utility decb, I was able to get a text version of the tokenized BASic program easily:
$decb dir WNDO.DSK
Directory of: WNDO.DSK,
WNDO BAS 0 B 1
WNDO11 BAS 0 B 1
$decb list -t WNDO.DSK,WNDO.BAS
999 END
1000 REM WINDOW SUBROUTINE
1001 REM S-START W-IDTH
1002 REM A$-TEXT L-ENGTH
1005 PRINT@S,STRING$(W+1,140)CHR$(141);:FORA=1TOL:PRINT@A*32+S,CHR$(133)STRING$(W,32)CHR$(128);:NEXTA:PRINT@32*L+S,CHR$(131)STRING$(W+1,128);:B=1
1010 FORA=W TOW-8STEP-1:IFMID$(A$,A,1)=" "THENPRINT@S+1+32*B,LEFT$(A$,A);:A$=RIGHT$(A$,LEN(A$)-A)ELSENEXTA:PRINT@S+1+32*B,A$;:GOTO1020
1015 B=B+1:GOTO1010
1020 PRINT@S+32*(L-1)+(W/2-5),"press any key";
1025 IFINKEY$=""THEN1025ELSERETURN
$ decb list -t WNDO.DSK,WNDO11.BAS
999 END
1000 REM WINDOW SUBROUTINE 1.1
1001 REM BY ALLEN C. HUFFMAN
1002 REM 8/8, 8/9/87
1003 C=4
1005 PRINT@S,CHR$(140)STRING$(W,140)CHR$(141);:FORA=1TOL:PRINT@A*32+S,CHR$(133)STRING$(W,32)CHR$(133+16*C);:NEXTA:PRINT@32*L+S,CHR$(131)STRING$(W,131+16*C)CHR$(135+16*C);:B=1
1010 FORA=W TOW-8STEP-1:IFMID$(A$,A,1)=" "THENPRINT@S+1+32*B,LEFT$(A$,A);:A$=RIGHT$(A$,LEN(A$)-A)ELSENEXTA:PRINT@S+1+32*B,A$;:GOTO1020
1015 B=B+1:GOTO1010
1020 PRINT@S+32*(L-1)+W/2-6,"press"CHR$(128)"any"CHR$(128)"key";
1025 IFINKEY$=""THEN1025ELSERETURN
It appears the first version had help in the comments, and the second replaced that with my name and version dates. Looking at a WinMerge diff of the two versions, I see this:
It looks like I basically added color support rather than just a black drop shadow, and must have fixed a bug where width needed 1 added to it. The only other change was printing “PRESS ANY KEY” with black blocks between each word in stead of spaces. I can therefore tell I used at least this 1.1 version in my TIDY DISK program.
The subroutine requires the user to set a few variables before calling it:
S – PRINT @ position for the top left of the pop-up.
W – width of the pop-up (in characters).
L – length (height) of the pop-up (in lines).
A$ – message to display inside the pop-up. The message will be word-wrapped by the routine.
It appears I also allowed the user to set the color. In line 1003, the routine sets it to 3 (white), but the user could also set C ahead of time and then GOSUB to 1005 to bypass that line and use their own color. So I’ll add:
C – color of the drop shadow (use GOSUB 1005) if setting C.
GOSUB 1000 uses a default color, or set it yourself and GOSUB 1005. Nice.
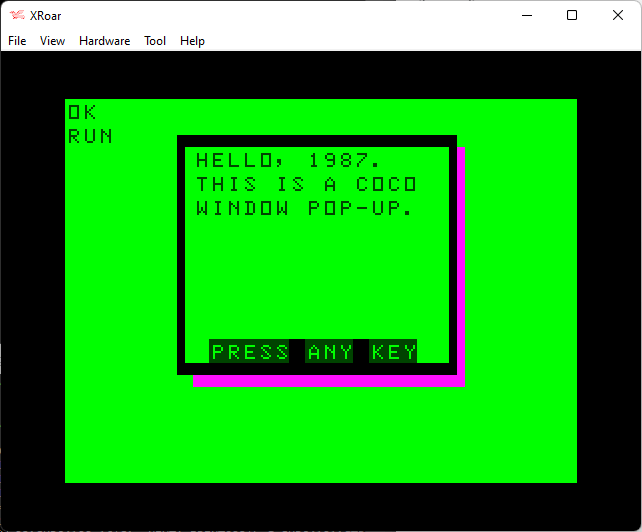
10 C=6:S=39:W=16:L=10
20 A$="HELLO, 1987. THIS IS A COCO WINDOW POP-UP."
30 GOSUB 1005
The routine itself is not very smart. It doesn’t calculate anything. The user has to specify top left, width and height and do all that work. If you want a nicely centered box, you have to figure that out. But, if you wanted to make windows at different positions, I guess it allowed that flexibility. (I expect that’s why I wrote it this way.)
We can do better.
How many lines is it, anyway?
For most uses, a centered pop-up seems good enough. The issue is knowing how many lines the message is going to take to display after being word-wrapped. The current routine scans the string starting at “width” and moving backwards until it finds a space character. It then uses LEFT$ to print just that portion, and then trims that part off using RIGHT$.
To know how many lines it will take, we have to scan the string first to count them. Then we do it again to print them. This will slow things down, but make things easier on the user.
Anatomy of a Word Wrap
There are some good old articles here about word wrap routines, with some very fast and clever ones contributed by others (way better than mine). Check out those articles for better methods that what I am about to present.
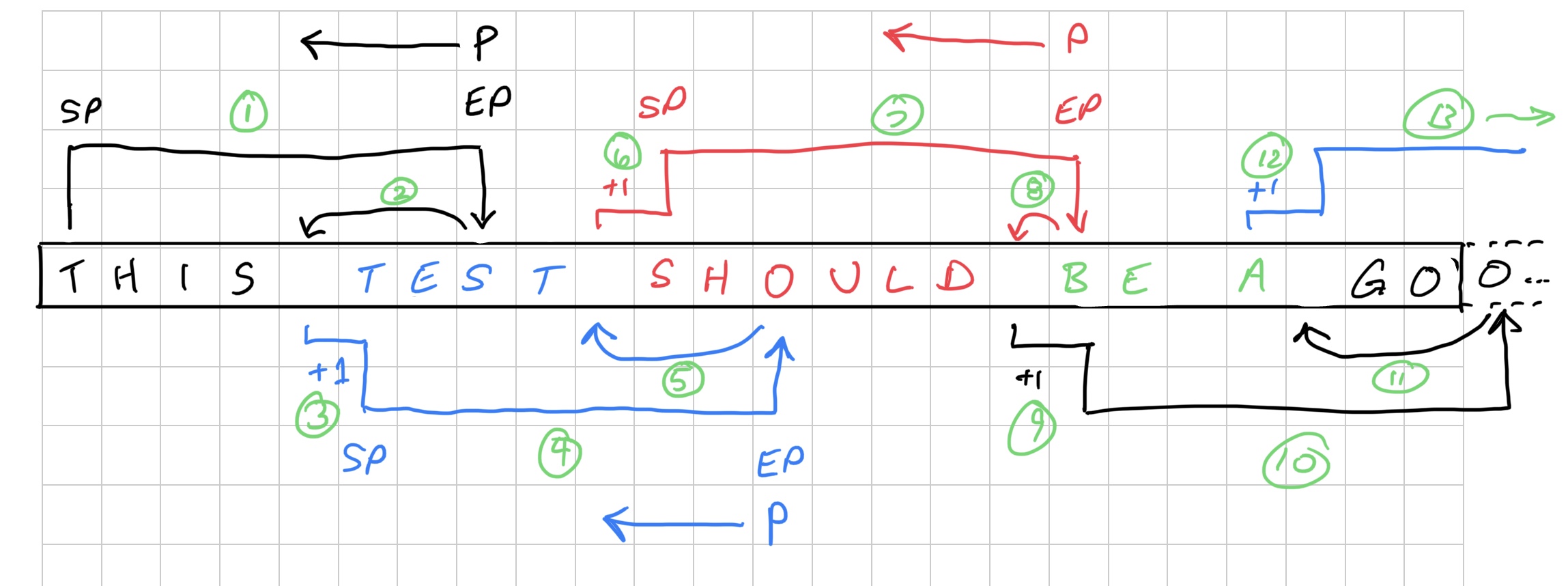
Because I need to scan the line twice — one time to count the lines, and the second for the actual word wrap — I cannot mess with the user’s string. Instead, I’ll just use variables that sell me the Start Position (SP) within the string and End Position (EP) of the width-sized chunk I am going to scan. I’ll use a Position (P) variable and start at the end and scan backwards looking for a space. If I find one, I can count that as a line (increase the line count) and then move to the next character (to skip the space) and reset the Start Position to that. The process will repeat.
Since I do not want to duplicate code, I’ll embed the “print this section of the string” code in this routine, but use another variable to determine if I actually print it or now. I’m calling it Show (SH), and if SH=0 then it just counts, otherwise it prints as it counts each line.
It’s messy, but it works.
Here is a diagram showing the process:
Anatomy of a Word Wrap routine…
When the space is located, it knows that from SP to that space position is something to print (a line).
Easy peasy.
Except it took me way too much brane power to figure this out, and I am sure it could be massively improved.
The routine will use the user’s width (W) variable to know how wide to make the box, and adjust the text space inside accordingly (W-2, leaving room for the borders).
The user can specify C for color, or if it’s not set (0) it will be assigned a color.
The starting location (S) must also be set. This is the top left of the pop-up box, in PRINT@ format (i.e. 0 is the top left of the screen, 32 is the start of the second line, etc.)
Here is what I came up with, along with a few lines at the start to test it out. It will keep displaying random sized pop-ups with the same text over and over and over. I used this to make sure it would work with the various size and color valuies.
NOTE: If you send in a width that is too narrow, it won’t work properly. Ideally I should check for that and have a minimum size. (I’ll try to add that in the final version, since I know it needs to be at least wide enough to fit “PRESS ANY KEY”.)
10 A$="THIS IS A LONG STRING THAT I WANT TO USE TO TEST WORD WRAPPING IN MY WINDOW ROUTINE."
20 W=RND(10)+20:S=48-W/2:C=RND(8)-1
30 CLS:GOSUB 1000
40 GOTO 20
999 END
1000 REM WINDOW SUBROUTINE 2.0
1001 REM BY ALLEN C. HUFFMAN
1002 REM 8/8, 8/9/87 & 7/27/22
1993 REM S-START W-IDTH
1004 REM A$-TEXT C-COLOR
1005 REM
1010 IF C=0 THEN C=4
1020 SH=0:GOSUB 1120
1030 PRINT@S,CHR$(140)STRING$(W-2,140)CHR$(141);
1040 FOR A=1 TO LC+1
1050 PRINT@S+32*A,CHR$(133)STRING$(W-2,32)CHR$(133+16*C);
1060 NEXTA
1070 PRINT@S+32*(LC+1),CHR$(131)STRING$(W-2,131+16*C)CHR$(135+16*C);
1080 SH=1:GOSUB 1120
1090 PRINT@S+32*LC+W/2-7,"press"CHR$(128)"any"CHR$(128)"key";
1100 IF INKEY$="" THEN 1100 ELSE RETURN
1110 ' CALC LINE COUNT/PRINT
1120 LC=1:SP=1:LN=LEN(A$)
1130 EP=SP+W-2:P=EP
1140 IF EP>LN THEN 1190
1150 IF MID$(A$,P,1)<>" " THEN P=P-1 ELSE 1170
1160 IF P>SP THEN 1150 ELSE 1190
1170 IF SH<>0 THEN PRINT@S+32*LC+1,MID$(A$,SP,P-SP);
1180 LC=LC+1:SP=P+1:GOTO 1130
1190 IF SH<>0 THEN PRINT@S+32*LC+1,MID$(A$,SP);
1200 LC=LC+1:RETURN
1210 RETURN
One bad thing about this is all the variables I am using. And it could also be made faster by combining lines and such.
Here are some things I would like to do next:
Check for a minimum width (if W<x then W=x).
Combine lines to make it smaller and faster.
Rename variables to all start with Z.
Z? Since my subroutine uses many variables, the calling program would have to make sure to not use any of them since the subroutine would change them. Today I like the approach of starting all my subroutine variables with Z, and just noting that “Zx variables are reserved for subroutines.” That way I can use any variables I want in my main program — other than the ones that are specifically used to pass values in to the subroutine — without worrying about a conflict.
I guess that means there will be a part 2. Until then, please comment with any ideas you have on improving this.