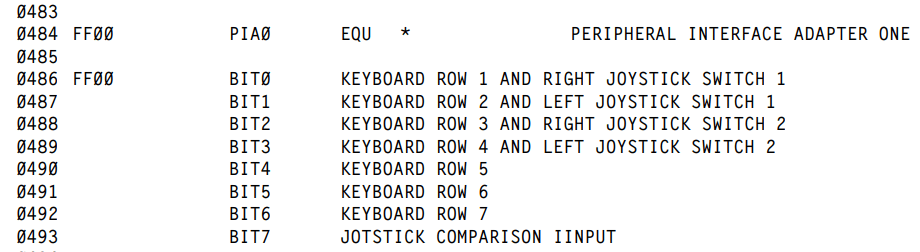
See also: part 1, part 2, part 3, part 4, part 5, part 6, part 7 and more (coming “soon”).
Previously, a code snippet shared by Jim McClellan on Facebook motivated me to benchmark various methods of reading the CoCo keyboard in BASIC:
10 KBD=PEEK(135) AND PEEK(65282)
20 PRINT KBD
30 GOTO 10Unfortunately, as I started my stream of consciousness article, I discovered that this sample code did not work on the Xroar emulator I was using. I recalled there had been some differences to Color BASIC’s keyboard scanning code in later versions, and thought this might be why.
Indeed, the knowledgeable Lost Wizard William Astle chimed in via comments:
I think it would only work on Color Basic 1.2 or 1.3. The reason for that is Color Basic 1.2 introduced an optimization where it only does the full matrix scan if no keys (or joystick buttons!) are pressed. It does this by writing a 0 to FF02 to “strobe” all columns. That means there will be at least one 0 bit in FF00 representing a key pressed if anything is down at all. If it detects nothing, it just exits, leaving the column strobe set to 0.
Prior to Color Basic 1.2, the matrix scan was always run. In that case, if no keys are down, it will have strobed all columns in sequence (by writing a zero bit to successive bits of FF02). This zero bit is shifted over by a ROL instruction so it eventually shifts off into carry and the final result in FF02 is FF. Eventually, most versions will eventually strobe no columns by writing FF to FF02 which is used to detect joystick buttons. The debounce check also puts a nonzero, non FF value in FF02 corresponding with the column where a key was detected. Depending on the Color Basic version, the final results of KEYIN and FF02 are (assuming I read the code correctly):
1.0: FF if no key jor joystick button, non-FF if key down (or debounce fails)
1.1: FF if no key or joystick button, non-FF if key down (or debounce fails)
1.2: 0 if no key or joystick button, FF if key or joystick button, not 0 or FF if debounce fails
1.3: same as 1.2; no modifications to KEYIN
Coco3: always FF (the check for a key optimization is removed) except when debounce fails
Basically, this trick only works on Color Basic 1.2 and 1.3. And even then, it isn’t actually reliable since you won’t get FF if debounce fails. Instead, you’ll potentially get a value with a single zero bit which will corrupt your key code. The odds of the timing being just right for that to happen are really small. However, it is possible.
So my considered opinion based on the variances between ROM versions is that this trick must not be used.
As a side note: aside from the system initialization code, KEYIN has the most significant changes between Color Basic versions.
William Astle
With this note, I now have to change my original plan for this article. I was going to see how much faster this code would be with normal tricks (HEX versus decimal constants, variables instead of constants, etc.) to see which approach would make any game using this code faster.
But since this sample only works with specific versions of Color BASIC, I now need to come up with a more portable non-portable way to do this. This sent me back to some other Facebook posts from Ben Jimenez and Jim Gerrie back in April 2020:
10 CLS
20 POKE 341,255:POKE 342,255:POKE 343,255:POKE 344,255
30 I$=INKEY$:IF I$="" THEN GOTO 20
40 PRINT ASC(I$)
50 GOTO 20When I run this under Xroar using Color BASIC 1.1, I see that it will print a repeating series of numbers as I hold down each arrow key. I also notice that it repeats for some other keyboard presses, but not all.
But why? A new mystery!
I suspect this is because those POKEs must have something to do with the row or column the four arrow keys are in the keyboard matrix:
1 2 3 4 5 6 7 8
| | | | | | | |
1 --- @ --- A --- B --- C --- D --- E --- F --- G
| | | | | | | |
2 --- H --- I --- J --- K --- L --- M --- N --- O
| | | | | | | |
3 --- P --- Q --- R --- S --- T --- U --- V --- W
| | | | | | | |
4 --- X --- Y --- Z -- UP -- DWN - LFT - RGT - SPACE
| | | | | | | |
5 --- 0 -- 1! -- 2" -- 3# -- 4$ -- 5% -- 6& -- 7'
| | | | | | | |
6 -- 8( -- 9) -- :* -- ;+ -- ,< -- -= -- .> -- /?
| | | | | | | |
7 -- ENT - CLR - BRK - ALT - CTL - F1 -- F2 - SHIFT
All four arrow keys are in row 4, and they repeat. I am betting that the other keys that repeat are the ones in the same columns UP, DOWN, LEFT and RIGHT are in (col 4-7). A quick test shows that @, A and B to not repeat (they use columns 1, 2 and 3), but C, D E and F do (columns 4-7) and G does not (column 8).
Mystery solved.
Whatever those POKEs are doing, they are resetting something involving columns 4, 5, 6 and 7. This sends me back into the Color BASIC Unraveled disassembly to see what memory locations 341 (&H155) to 344 (&H158) are:
0152 KEYBUF RMB 8 KEYBOARD MEMORY BUFFER
Eight bytes, and we are setting four of them to 255 (all bits set to 1). No help so far. I start making notes:
KEYBUF - Keyboard memory buffer: 338 &H152 339 &H153 340 &H154 341 &H155 - POKEd to 255 (&HFF) 342 &H156 - POKEd to 255 (&HFF) 343 &H157 - POKEd to 255 (&HFF) 344 &H158 - POKEd to 255 (&HFF) 345 &H159
Next, I search the code to see where this KEYBUF is being used, and then things get confusing. The disassembly has multiple code listings that reference this — different code for different versions of the ROM. Great.
KEYIN konfusion
As William Astle referenced, this buffer is used by the KEYIN routine and there are multiple implementations. The code is described as:
KEYIN SCAN THE KEYBOARD FOR A KEY DEPRESSION - Return zero flag = 1 if no new key down. Return the ASCII value of the key in ACCA if a new key is depressed.
Ah, this looks familiar. As soon as I read this, I remembered something from learning CoCo 6809 programming using the EDTASM cartridge.
POLCAT ROM routine digression
Microsoft, thinking ahead to potential changes in the ROM code, set aside a few “documented ROM calls” that assembly language programmers could use. If you wrote an assembly program for Color BASIC 1.0 and wanted to use the KEYIN routine in ROM by jumping directly to its address in the ROM, that program would not work in later Color BASIC 1.2 versions that had KEYIN at a different address.
Instead, Microsoft placed a few hooks in ROM starting at location &HA000. Each entry was the address of a routine elsewhere in the ROM. By using a “jump by reference” assembly instruction, you could end up at wherever those addresses point. POLCAT was the entry for getting a keystroke, and it points to KEYIN:
0002 A000 A1 CB POLCAT FDB KEYIN GET A KEYSTROKE 0003 A002 A2 82 CHROUT FDB PUTCHR OUTPUT A CHARACTER 0004 A004 A7 7C CSRDON FDB CASON TURN ON CASSETTE MOTOR, START READING 0005 A006 A7 0B BLKIN FDB GETBLK READ A BLOCK FROM CASSETTE 0006 A008 A7 F4 BLKOUT FDB SNDBLK WRITE A BLOCK TO CASSETTE 0007 A00A A9 DE JOYIN FDB GETJOY READ JOYSTICKS 0008 A00C A7 D8 WRTLDR FDB WRLDR TURN ON MOTOR AND WRITE $55’S TO CASSETTE
That was the official documented way to see if a key was pressed. The implementation of what POLCAT points to changes between ROM versions, so while this compatible call would return a key, the way that it obtained that key changed.
Here’s a short assembly program using POLCAT (KEYIN).

When I assemble that in EDTASM (“A/IM/WE/AO”) and execute from ZBUG (“Z”, “G START”), I can start pressing keys and see them POKEd to the top left corner of the screen, and moving forward as I press different keys. Holding down a key does not repeat. Thus, the KEYIN routine does not support keyboard repeat.
But I digress.
When Jim’s original code PEEKs two values from memory location 135 (last key pressed) and 65282 (&HFF02, the PIA chip that reads the eight keyboard columns of the keyboard matrix), it apparently relying on code in the Color BASIC ROM that is resetting things so it always updates. In the 1.1 ROM I am using, the ROM code is different so that method does not work.
However, the second bit of code (from either Jim or Ben) using the four POKEs and INKEY$ does appear to work on 1.1 as well as 1.2.
Dam this stream of consciousness!
Sorry to disappoint, but I’ll let someone else write an article explaining the differences in KEYIN. I can already see this is over my head without spending substantial time diffing through the various ROM versions…
At this point, I see WHAT works, but cannot explain WHY. In the next installment, I’ll move beyond the WHY and get back to the original goal of trying to make the WHAT work as fast as possible.
To be continued…