My old appleause.com blog has been shut down, and the articles form there merged into this blog. I originally started that site back in 2007 with the intent of blogging about Apple stuff, mostly my research. Those articles are obsolete now. Firewire to SATA interface research? How quaint.
The one surprising thing was that I posted about resurrecting my Furby many years ago, even to the day I still get a few comments on that article each year. Crazy.
And if you wondered, I always pronounced appleause.com (like Apple + Applause) as Apple-Oz…
And if anyone wants a cool domain name for an Apple blog and wants to obtain that domain, let me know. I had big plans for it, and still do, but likely won’t have the time to work on it any time soon.
This post is an indirect follow-up to an earlier post I made about floating point numbers and the frequency 902.1 Mhz. If you check out that original posting, there was a follow-up to it as well.
My day job is maintaining software that runs solid-state microwave generators. As such, it deals with frequencies such as 902.1 MHz or 902100000 Hz. The Windows-based generator control software initially used 32-bit floating point values to represent frequencies in MHz, such as:
The user interface would round frequencies to the nearest 100,000 Hz, such as 902.1 MHz or 915.4 MHz. This allowed the limitations of a 32-bit floating point to not be a problem.
Limitations of 32-bit floating point
As discussed in my 902.1 posts referenced at the start of this post, certain values cannot be represented as a 32-bit floating point. 902.1 turns into 902.099976, for example:
float mhz = 902.1;
printf ("mhz = %f\n", mhz);
Comparing floating point values as one would compare integers may not work as expected:
float mhz = 902.1;
if (mhz == 902.1)
{
printf ("mhz IS 902.1\n");
}
else
{
printf ("mhz is NOT 902.1\n");
}
Running that on a 32-bit compiler will print the message:
mhz is NOT 902.1
But if you change the variable type from float to double (64-bit floating point), that gives it enough precision for this to work:
double mhz = 902.1; // changed from float to double
printf ("mhz = %f\n", mhz);
if (mhz == 902.1)
{
printf ("mhz IS 902.1\n");
}
else
{
printf ("mhz is NOT 902.1\n");
}
Running that will print:
mhz IS 902.1
So, yeah. Folks who don’t do much with floating point may find this surprising. I sure did when I first learned it.
Floating point is great if you have it…
Few of the embedded systems I have programmed on were using CPUs with hardware floating point. Instead, any floating point calculations were done using a software library. Bringing in floating point library code made the program grow larger. This is not optimal when dealing with systems with limited program memory. It also made the code slower, which was not optimal on systems with slower processors.
While the Windows program, running on a modern 64-bit CPU, could use floating point easily, the embedded firmware, running on 16-bit CPUs, was written to use integers for smaller code size and faster operation. (No, of course this is not the case on every system. This is just an example you are reading on some random blog on the internet…)
Instead of trying to represent a frequency as MHz in floating point, the firmware would use a 32-bit integer as hz.
float f_mhz = 902.1; // on 64-bit Windows system
uint32_t hz = 902100000; // on 16-bit firmware
When I explain this to someone who is unfamiliar of “the problems with floating point,” I show them quick examples like this. For fun (everybody needs a hobby), tonight I wrote up a longer example that prints out the frequencies of 902 MHz to 928 MHz (matching the L-Band RF frequency used by the microwave systems at my work) in steps of .1 MHz.
The example then converts that frequency value to a float and a double, then converts each back to a 32-bit unsigned integer and prints them all out.
Some comparisons are done (float compared to double, and float converted to 32-bit integer compared to double converted to 32-bit integer) with the output marking values that differ as floating points (“F”) and/or unsigned integers (“U”).
mhz float uint32_t double uint32_t ==? ----- ---------- --------- ---------- --------- --- 902.0 902.000000 902000000 902.000000 902000000 902.1 902.099976 902099968 902.100000 902100000 F U 902.2 902.200012 902200000 902.200000 902200000 F 902.3 902.299988 902299968 902.300000 902300000 F U 902.4 902.400024 902400000 902.400000 902400000 F 902.5 902.500000 902499968 902.500000 902500000 U 902.6 902.599976 902600000 902.600000 902600000 F 902.7 902.700012 902700032 902.700000 902700000 F U 902.8 902.799988 902800000 902.800000 902800000 F 902.9 902.900024 902900032 902.900000 902900000 F U 903.0 903.000000 903000000 903.000000 903000000 903.1 903.099976 903099968 903.100000 903100000 F U 903.2 903.200012 903200000 903.200000 903200000 F 903.3 903.299988 903299968 903.300000 903300000 F U 903.4 903.400024 903400000 903.400000 903400000 F 903.5 903.500000 903500032 903.500000 903500000 U 903.6 903.599976 903600000 903.600000 903600000 F 903.7 903.700012 903700032 903.700000 903700000 F U 903.8 903.799988 903800000 903.800000 903800000 F 903.9 903.900024 903900032 903.900000 903900000 F U 904.0 904.000000 904000000 904.000000 904000000 904.1 904.099976 904099968 904.100000 904100000 F U 904.2 904.200012 904200000 904.200000 904200000 F 904.3 904.299988 904299968 904.300000 904300000 F U 904.4 904.400024 904400000 904.400000 904400000 F 904.5 904.500000 904499968 904.500000 904500000 U 904.6 904.599976 904600000 904.600000 904600000 F 904.7 904.700012 904700032 904.700000 904700000 F U 904.8 904.799988 904800000 904.800000 904800000 F 904.9 904.900024 904900032 904.900000 904900000 F U 905.0 905.000000 905000000 905.000000 905000000 905.1 905.099976 905099968 905.100000 905100000 F U 905.2 905.200012 905200000 905.200000 905200000 F 905.3 905.299988 905299968 905.300000 905300000 F U 905.4 905.400024 905400000 905.400000 905400000 F 905.5 905.500000 905500032 905.500000 905500000 U 905.6 905.599976 905600000 905.600000 905600000 F 905.7 905.700012 905700032 905.700000 905700000 F U 905.8 905.799988 905800000 905.800000 905800000 F 905.9 905.900024 905900032 905.900000 905900000 F U 906.0 906.000000 906000000 906.000000 906000000 906.1 906.099976 906099968 906.100000 906100000 F U 906.2 906.200012 906200000 906.200000 906200000 F 906.3 906.299988 906299968 906.300000 906300000 F U 906.4 906.400024 906400000 906.400000 906400000 F 906.5 906.500000 906499968 906.500000 906500000 U 906.6 906.599976 906600000 906.600000 906600000 F 906.7 906.700012 906700032 906.700000 906700000 F U 906.8 906.799988 906800000 906.800000 906800000 F 906.9 906.900024 906900032 906.900000 906900000 F U 907.0 907.000000 907000000 907.000000 907000000 907.1 907.099976 907099968 907.100000 907100000 F U 907.2 907.200012 907200000 907.200000 907200000 F 907.3 907.299988 907299968 907.300000 907300000 F U 907.4 907.400024 907400000 907.400000 907400000 F 907.5 907.500000 907500032 907.500000 907500000 U 907.6 907.599976 907600000 907.600000 907600000 F 907.7 907.700012 907700032 907.700000 907700000 F U 907.8 907.799988 907800000 907.800000 907800000 F 907.9 907.900024 907900032 907.900000 907900000 F U 908.0 908.000000 908000000 908.000000 908000000 908.1 908.099976 908099968 908.100000 908100000 F U 908.2 908.200012 908200000 908.200000 908200000 F 908.3 908.299988 908299968 908.300000 908300000 F U 908.4 908.400024 908400000 908.400000 908400000 F 908.5 908.500000 908499968 908.500000 908500000 U 908.6 908.599976 908600000 908.600000 908600000 F 908.7 908.700012 908700032 908.700000 908700000 F U 908.8 908.799988 908800000 908.800000 908800000 F 908.9 908.900024 908900032 908.900000 908900000 F U 909.0 909.000000 909000000 909.000000 909000000 909.1 909.099976 909099968 909.100000 909100000 F U 909.2 909.200012 909200000 909.200000 909200000 F 909.3 909.299988 909299968 909.300000 909300000 F U 909.4 909.400024 909400000 909.400000 909400000 F 909.5 909.500000 909500032 909.500000 909500000 U 909.6 909.599976 909600000 909.600000 909600000 F 909.7 909.700012 909700032 909.700000 909700000 F U 909.8 909.799988 909800000 909.800000 909800000 F 909.9 909.900024 909900032 909.900000 909900000 F U 910.0 910.000000 910000000 910.000000 910000000 910.1 910.099976 910099968 910.100000 910100000 F U 910.2 910.200012 910200000 910.200000 910200000 F 910.3 910.299988 910299968 910.300000 910300000 F U 910.4 910.400024 910400000 910.400000 910400000 F 910.5 910.500000 910499968 910.500000 910500000 U 910.6 910.599976 910600000 910.600000 910600000 F 910.7 910.700012 910700032 910.700000 910700000 F U 910.8 910.799988 910800000 910.800000 910800000 F 910.9 910.900024 910900032 910.900000 910900000 F U 911.0 911.000000 911000000 911.000000 911000000 911.1 911.099976 911099968 911.100000 911100000 F U 911.2 911.200012 911200000 911.200000 911200000 F 911.3 911.299988 911299968 911.300000 911300000 F U 911.4 911.400024 911400000 911.400000 911400000 F 911.5 911.500000 911500032 911.500000 911500000 U 911.6 911.599976 911600000 911.600000 911600000 F 911.7 911.700012 911700032 911.700000 911700000 F U 911.8 911.799988 911800000 911.800000 911800000 F 911.9 911.900024 911900032 911.900000 911900000 F U 912.0 912.000000 912000000 912.000000 912000000 912.1 912.099976 912099968 912.100000 912100000 F U 912.2 912.200012 912200000 912.200000 912200000 F 912.3 912.299988 912299968 912.300000 912300000 F U 912.4 912.400024 912400000 912.400000 912400000 F 912.5 912.500000 912499968 912.500000 912500000 U 912.6 912.599976 912600000 912.600000 912600000 F 912.7 912.700012 912700032 912.700000 912700000 F U 912.8 912.799988 912800000 912.800000 912800000 F 912.9 912.900024 912900032 912.900000 912900000 F U 913.0 913.000000 913000000 913.000000 913000000 913.1 913.099976 913099968 913.100000 913100000 F U 913.2 913.200012 913200000 913.200000 913200000 F 913.3 913.299988 913299968 913.300000 913300000 F U 913.4 913.400024 913400000 913.400000 913400000 F 913.5 913.500000 913500032 913.500000 913500000 U 913.6 913.599976 913600000 913.600000 913600000 F 913.7 913.700012 913700032 913.700000 913700000 F U 913.8 913.799988 913800000 913.800000 913800000 F 913.9 913.900024 913900032 913.900000 913900000 F U 914.0 914.000000 914000000 914.000000 914000000 914.1 914.099976 914099968 914.100000 914100000 F U 914.2 914.200012 914200000 914.200000 914200000 F 914.3 914.299988 914299968 914.300000 914300000 F U 914.4 914.400024 914400000 914.400000 914400000 F 914.5 914.500000 914499968 914.500000 914500000 U 914.6 914.599976 914600000 914.600000 914600000 F 914.7 914.700012 914700032 914.700000 914700000 F U 914.8 914.799988 914800000 914.800000 914800000 F 914.9 914.900024 914900032 914.900000 914900000 F U 915.0 915.000000 915000000 915.000000 915000000 915.1 915.099976 915099968 915.100000 915100000 F U 915.2 915.200012 915200000 915.200000 915200000 F 915.3 915.299988 915299968 915.300000 915300000 F U 915.4 915.400024 915400000 915.400000 915400000 F 915.5 915.500000 915500032 915.500000 915500000 U 915.6 915.599976 915600000 915.600000 915600000 F 915.7 915.700012 915700032 915.700000 915700000 F U 915.8 915.799988 915800000 915.800000 915800000 F 915.9 915.900024 915900032 915.900000 915900000 F U 916.0 916.000000 916000000 916.000000 916000000 916.1 916.099976 916099968 916.100000 916100000 F U 916.2 916.200012 916200000 916.200000 916200000 F 916.3 916.299988 916299968 916.300000 916300000 F U 916.4 916.400024 916400000 916.400000 916400000 F 916.5 916.500000 916499968 916.500000 916500000 U 916.6 916.599976 916600000 916.600000 916600000 F 916.7 916.700012 916700032 916.700000 916700000 F U 916.8 916.799988 916800000 916.800000 916800000 F 916.9 916.900024 916900032 916.900000 916900000 F U 917.0 917.000000 917000000 917.000000 917000000 917.1 917.099976 917099968 917.100000 917100000 F U 917.2 917.200012 917200000 917.200000 917200000 F 917.3 917.299988 917299968 917.300000 917300000 F U 917.4 917.400024 917400000 917.400000 917400000 F 917.5 917.500000 917500032 917.500000 917500000 U 917.6 917.599976 917600000 917.600000 917600000 F 917.7 917.700012 917700032 917.700000 917700000 F U 917.8 917.799988 917800000 917.800000 917800000 F 917.9 917.900024 917900032 917.900000 917900000 F U 918.0 918.000000 918000000 918.000000 918000000 918.1 918.099976 918099968 918.100000 918100000 F U 918.2 918.200012 918200000 918.200000 918200000 F 918.3 918.299988 918299968 918.300000 918300000 F U 918.4 918.400024 918400000 918.400000 918400000 F 918.5 918.500000 918499968 918.500000 918500000 U 918.6 918.599976 918600000 918.600000 918600000 F 918.7 918.700012 918700032 918.700000 918700000 F U 918.8 918.799988 918800000 918.800000 918800000 F 918.9 918.900024 918900032 918.900000 918900000 F U 919.0 919.000000 919000000 919.000000 919000000 919.1 919.099976 919099968 919.100000 919100000 F U 919.2 919.200012 919200000 919.200000 919200000 F 919.3 919.299988 919299968 919.300000 919300000 F U 919.4 919.400024 919400000 919.400000 919400000 F 919.5 919.500000 919500032 919.500000 919500000 U 919.6 919.599976 919600000 919.600000 919600000 F 919.7 919.700012 919700032 919.700000 919700000 F U 919.8 919.799988 919800000 919.800000 919800000 F 919.9 919.900024 919900032 919.900000 919900000 F U 920.0 920.000000 920000000 920.000000 920000000 920.1 920.099976 920099968 920.100000 920100000 F U 920.2 920.200012 920200000 920.200000 920200000 F 920.3 920.299988 920299968 920.300000 920300000 F U 920.4 920.400024 920400000 920.400000 920400000 F 920.5 920.500000 920499968 920.500000 920500000 U 920.6 920.599976 920600000 920.600000 920600000 F 920.7 920.700012 920700032 920.700000 920700000 F U 920.8 920.799988 920800000 920.800000 920800000 F 920.9 920.900024 920900032 920.900000 920900000 F U 921.0 921.000000 921000000 921.000000 921000000 921.1 921.099976 921099968 921.100000 921100000 F U 921.2 921.200012 921200000 921.200000 921200000 F 921.3 921.299988 921299968 921.300000 921300000 F U 921.4 921.400024 921400000 921.400000 921400000 F 921.5 921.500000 921500032 921.500000 921500000 U 921.6 921.599976 921600000 921.600000 921600000 F 921.7 921.700012 921700032 921.700000 921700000 F U 921.8 921.799988 921800000 921.800000 921800000 F 921.9 921.900024 921900032 921.900000 921900000 F U 922.0 922.000000 922000000 922.000000 922000000 922.1 922.099976 922099968 922.100000 922100000 F U 922.2 922.200012 922200000 922.200000 922200000 F 922.3 922.299988 922299968 922.300000 922300000 F U 922.4 922.400024 922400000 922.400000 922400000 F 922.5 922.500000 922499968 922.500000 922500000 U 922.6 922.599976 922600000 922.600000 922600000 F 922.7 922.700012 922700032 922.700000 922700000 F U 922.8 922.799988 922800000 922.800000 922800000 F 922.9 922.900024 922900032 922.900000 922900000 F U 923.0 923.000000 923000000 923.000000 923000000 923.1 923.099976 923099968 923.100000 923100000 F U 923.2 923.200012 923200000 923.200000 923200000 F 923.3 923.299988 923299968 923.300000 923300000 F U 923.4 923.400024 923400000 923.400000 923400000 F 923.5 923.500000 923500032 923.500000 923500000 U 923.6 923.599976 923600000 923.600000 923600000 F 923.7 923.700012 923700032 923.700000 923700000 F U 923.8 923.799988 923800000 923.800000 923800000 F 923.9 923.900024 923900032 923.900000 923900000 F U 924.0 924.000000 924000000 924.000000 924000000 924.1 924.099976 924099968 924.100000 924100000 F U 924.2 924.200012 924200000 924.200000 924200000 F 924.3 924.299988 924299968 924.300000 924300000 F U 924.4 924.400024 924400000 924.400000 924400000 F 924.5 924.500000 924499968 924.500000 924500000 U 924.6 924.599976 924600000 924.600000 924600000 F 924.7 924.700012 924700032 924.700000 924700000 F U 924.8 924.799988 924800000 924.800000 924800000 F 924.9 924.900024 924900032 924.900000 924900000 F U 925.0 925.000000 925000000 925.000000 925000000 925.1 925.099976 925099968 925.100000 925100000 F U 925.2 925.200012 925200000 925.200000 925200000 F 925.3 925.299988 925299968 925.300000 925300000 F U 925.4 925.400024 925400000 925.400000 925400000 F 925.5 925.500000 925500032 925.500000 925500000 U 925.6 925.599976 925600000 925.600000 925600000 F 925.7 925.700012 925700032 925.700000 925700000 F U 925.8 925.799988 925800000 925.800000 925800000 F 925.9 925.900024 925900032 925.900000 925900000 F U 926.0 926.000000 926000000 926.000000 926000000 926.1 926.099976 926099968 926.100000 926100000 F U 926.2 926.200012 926200000 926.200000 926200000 F 926.3 926.299988 926299968 926.300000 926300000 F U 926.4 926.400024 926400000 926.400000 926400000 F 926.5 926.500000 926499968 926.500000 926500000 U 926.6 926.599976 926600000 926.600000 926600000 F 926.7 926.700012 926700032 926.700000 926700000 F U 926.8 926.799988 926800000 926.800000 926800000 F 926.9 926.900024 926900032 926.900000 926900000 F U 927.0 927.000000 927000000 927.000000 927000000 927.1 927.099976 927099968 927.100000 927100000 F U 927.2 927.200012 927200000 927.200000 927200000 F 927.3 927.299988 927299968 927.300000 927300000 F U 927.4 927.400024 927400000 927.400000 927400000 F 927.5 927.500000 927500032 927.500000 927500000 U 927.6 927.599976 927600000 927.600000 927600000 F 927.7 927.700012 927700032 927.700000 927700000 F U 927.8 927.799988 927800000 927.800000 927800000 F 927.9 927.900024 927900032 927.900000 927900000 F U 928.0 928.000000 928000000 928.000000 928000000
In the last column, F means that the float (32-bit) floating point and the double (64-bit) floating point do not match. U means the float (32-bit) converted to 32-bit integer does not match the double (64-bit) converted to integer.
All this to say, as I am beginning to experiment with new routines dealing with frequencies, I am creating all of them to handle those frequencies as Hz using 32-bit unsigned integers. This will allow these routines to also work well on embedded systems that lack floating point hardware, as well as ensure any weird “902.1” issues won’t cause someone else to waste hours of their time dealing with some math that is slightly off. . .
Over the years I have shared many tidbits about Color BASIC.
This is another one.
A recent post by Juan Castro to the Groups.IO Color Computer mailing list caught my attention, mostly because he called me out by name in the subject line:
As a reminder, Color BASIC allows 1 or 2 character variable names. They must start with a letter (A-Z) and the second character can be either letter (A-Z) or number (A-0). BUT, the BASIC interpreter does let you type longer names for variables, but it only honors the first two characters. Here is a screenshot from a past blog post here (which I’d link to if I was not so lazy):
Color BASIC variables may be very long, but only the first two characters are used.
This is a reminder that, if you try to use variables longer than two characters, you have to make sure you always keep the first two characters unique since “LONGVARIABLE” and “LOST” and “LO” are all the same variable to BASIC.
…but not all variable name limits are the same.
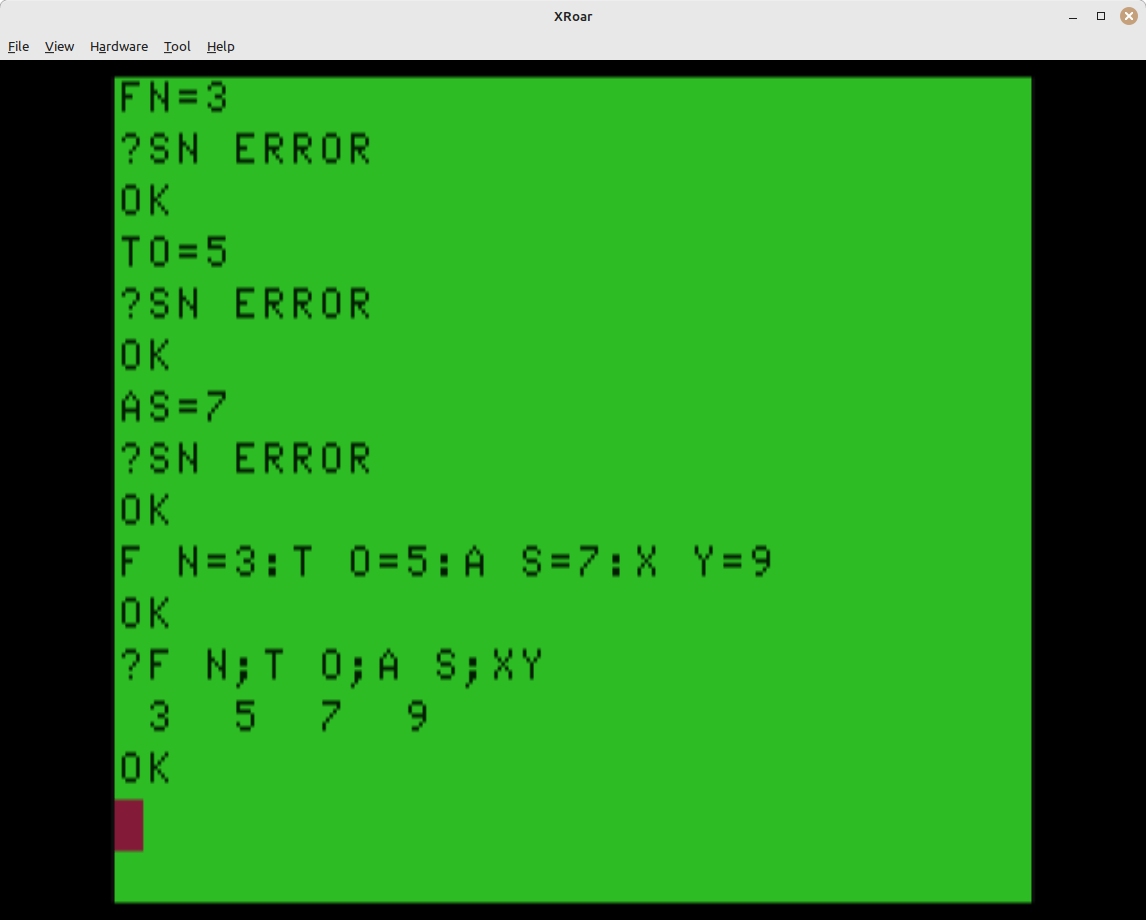
To break the rule I just said, in Color BASIC, some variable names are forbidden. A forbidden variable is one you cannot use because it is already reserved for a keyword or token. For example, FOR is a keyword:roar
FOR I=1 TO 10 PRINT I NEXT I
Because of this, even though BASIC only honors the first two characters of a variable name, you still cannot use “FOR” as a variable.
FOR=42 ?SN ERROR
But you can use “FO”, since that is not long enough to be recognized as a BASIC token or keyword.
FO=42 PRINT FO 42
There are a number of two-character tokens, such as “TO” in the FOR/NEXT statement (“FOR I=1 TO 10”), and “AS” in the Disk BASIC FIELD statement (“FIELD #1,5 AS A$”), as well as “FN” which is used in DEF FN.
AS=42 ?SN ERROR
FN=42 ?SN ERROR
TO=42 ?SN ERROR
This means if you wrote something for Color BASIC or Extended Color BASIC that uses “AS” as a variable, that would not work under Disk Extended Color BASIC.
BASIC ignores spaces
In recent years, someone pointed me to the fact that when scanning a BASIC line (either type in directly or when parsing a line of code in a program), spaces get ignored by the scanner. This means:
N M = 42 PRINT N M 42
That one surprised me when I learned it. This is probably why, when printing two variables, a semicolon is required between them:
N = 10 M = 20 PRINT N;M 10 20
And if you had done this (remember to CLEAR between these tests so variables are erased each time):
N = 10 M = 20 NM = 30 PRINT N M 30 PRINT N;M;N M 10 20 30
By the way, if you have ever wondered about that space printed in front of numeric variables when you do things like “PRINT X”, I covered why this happens in an earlier blog and included a simple patch to BASIC that removes that feature.
How to turn a forbidden variable into a non-forbidden one for fun and profit
Well, Juan Casto showed that using this “BASIC ignores spaces” quirk as a way to use forbidden variables. From his post:
Now it seems obvious. BASIC’s interpreter looks for keywords like “FOR” and will not recognize “F O R” or “FO R” as that token. The detokenizer honors the spaces.
But when it comes to variables, the spaces are ignored by the parser, so “T O” will not match as a token for “TO”, but will be processed as a variable “TO”.
Go figure.
Admittedly, space in two-character variable names look silly, but now I can finally update my old *ALLRAM* BBS to use the variable “TO$” for who a message is to:
FR$="ALLEN HUFFMAN" T O$="JUAN CASTRO" SB$="THAT'S REALLY COOL"
I suspect this was discovered by the early pioneers of BASIC, likely soon after the original Color Computer was released in 1980. If you know of a reference to this behavior from some early newsletter or magazine article, please let me know.
And as to Juan … thanks for sending me down a BASIC rabbit hole again…
Over the years, I have posted about things that fall into the category of “how did this ever work?” I think I need to make an actual WordPress Category on this blog for these items, and I will do so with this post.
Every embedded programming job I have had came with a bunch of pre-existing code that “worked.” There are always new features to be added, and bugs to be fixed, but overall things were already at an “it works, ship it” state.
And every embedded programming job I have had came with code that “works” but decided to not work later, leading me down a rabbit hole of code exploring to understand what it did and why it was suddenly did not.
This was often followed by finding a problem in the code that made me wonder how it ever worked in the first place.
SPI and interrupts on the PIC24 processor
This post is not specifically about SPI and interrupts on the PIC24 processor. I just happened to run into this particular issue in that environment.
On the seven hardware systems I maintain code for, there are various devices such as ADC, DAC, EEPROM, attenuators, phase shifters, frequency synthesizers, etc. that are hooked up to the CPU using I/O, I2C or SPI bus.
In the code main loop, the firmware reads or writes to these devices as needed, such as sampling RF detectors or making adjustments to power control attenuators.
Recently, we were testing a pulse modulation mode (PWM) where the RF signal is turning on and off. When on, the power is measured (detector read) inside an interrupt that was tied to the PWM signal. This code has been in place since before I joined 6+ years ago and, other than some bugs and enhancements along the way, “it works.”
However, this SPI code ended up being the cause of some odd problems that initially looked like I2C communications were failing. Our Windows-based host program that communicated over I2C would start having communication faults with the boards running firmware.
After a few days of Whac-A-Mole(tm) trying to rework things that could be problematic, I finally learned the root cause of the issue:
SPI and interrupts
The main loop was doing SPI operations (in our case, using the CCS PCD compiler and its API calls such as spi_init, spi_xfer, etc.). One of those SPI operations was for reading RF detectors. When PWM mode was enabled, the an interrupt service routine would be enabled and the main loop RF detectors reads would shut off and we would begin reading the RF detectors inside the interrupt routine as each pulse happened.
When a SPI operation happens, the code may need to reconfigure the SPI hardware between MODE 0 and MODE 1 transfers, for example, or to change the baud rate.
If the main code configured the SPI hardware for a specific mode and baud then began doing some SPI transfers and the pulse occurred, code would jump into the interrupt routine which might have to reconfigure the hardware differently and then read the detectors. Upon completion, execution returned back to the main loop and the SPI hardware could be in the wrong mode to complete that transaction.
Bad things would happen.
But why now?
The original code allowed pulsing at 100 Hz to 1000 Hz. This meant than 100 to 1000 times a second there was a chance that the SPI hardware could get messed up by the interrupt code. Yet, if we saw this happen, it was infrequent enough to be noticed.
At some point, I modified the code to support 10,000 Hz. This meant there was now 10,000 times a second that the problem could happen.
Over the years we had seen some issues at 10,000 Hz, including what we thought was RF interference causing communication problems (and solved through a hardware modification). Since this mode was rarely used, the true depth of the issue was never experienced.
“It works.”
Simple solutions…
A very simple solution was added which appears to have eliminated this issue completely. Some functions where added that could be called from the main loop code around any access to the SPI hardware. Here is a pseudo-code example of what I added:
Then, inside the interrupt service routine, that code could simply check that flag and skip reading at that pulse, knowing it would just catch the next one (I said this was the simple fix, not the best fix):
void pwm_isr (void) { if (0 == g_spi_lock) // SPI is free. { // Do SPI stuff… } }
Then all I had to do was add the claim and release around all the non-ISR SPI code…
“And just like that,” the problems all went away. Many of the problems we had been unaware of since some — like doing an EEPROM read — were typically not done while a system was running with RF enabled and pulsing active. Once I learned what the problem was, I could recreate it within seconds just by doing various things that caused SPI activity while in PWM mode. ;-)
That was my quick-and-dirty fix, but you may know a better one. If you feel like sharing it in a comment, please do so.
But the question remains…
How did this ever work?
Once the bug was understood, recreating it was simple. Yet, this code has been in use for years and “it worked.”
My next task is going to be reviewing all the other firmware projects and seeing if any of them do any type of SPI or I2C stuff from an interrupt that could mess up similar code happening from the main loop.
And I bet I find some.
In code that “just works” and has been working for years.
Just when I thought I was out, they pull me back in.
In part 3 I showed a simple assembly language routine that would uppercase a string.
In part 5, this routine was made more better by contributions from commenters.
Today, I revisit this code and update it to use “what I now know” (thank you, Sean Conner) about being able to pass strings into a USR function without using VARPTR.
First, here is the code from part 5:
* UCASE.ASM v1.01 * by Allen C. Huffman of Sub-Etha Software * www.subethasoftware.com / alsplace@pobox.com * * 1.01 a bit smaller per Simon Jonassen * * DEFUSRx() uppercase output function * * INPUT: VARPTR of a string * RETURNS: # chars processed * * EXAMPLE: * CLEAR 200,&H3F00 * DEFUSR0=&H3F00 * A$="Print this in uppercase." * PRINT A$ * A=USR0(VARPTR(A$)) * ORGADDR EQU $3f00
opt 6809 * 6809 instructions only opt cd * cycle counting
org ORGADDR
start jsr INTCNV * get passed in value in D tfr d,x * move value (varptr) to X ldy 2,x * load string addr to Y beq null * exit if strlen is 0 ldb ,x * load string len to B ldx #0 * clear X (count of chars conv)
loop lda ,y+ * get next char, inc Y ; lda ,y * load char in A cmpa #'a * compare to lowercase A blt nextch * if less, no conv needed cmpa #'z * compare to lowercase Z bgt nextch * if greater, no conv needed lcase suba #32 * subtract 32 to make uppercase leax 1,x * inc count of chars converted nextch jsr [CHROUT] * call ROM output character routine ; leay 1,y * increment Y pointer cont decb * decrement counter bne loop * not done yet ; beq exit * if 0, go to exit ; bra loop * go to loop
exit tfr x,d * move chars conv count to D jmp GIVABF * return to caller
null ldd #-1 * load -2 as error return jmp GIVABF * return to caller
In the header comment you can see an example of the usage, and that it involved using VARPTR on a string to get the string’s descriptor location in memory, then pass that address into the USR function.
Now that I know we can just pass a string in directly, I thought it would be fun (?) to update this old code to use that method. Here is what I came up with. Note that I changed the “*” comments to “;” since the a09 assembly does not support those. If you wanted to run this in EDTASM, you would have to change those back.
; UCASE3.ASM v1.02 ; by Allen C. Huffman of Sub-Etha Software ; www.subethasoftware.com / alsplace@pobox.com ; ; 1.01 a bit smaller per Simon Jonassen ; 1.02 converted to allow passing a string in to USR ; ; DEFUSRx() uppercase output function ; ; INPUT: string ; RETURNS: # chars converted or -1 if error ; ; EXAMPLE: ; CLEAR 200,&H3F00 ; DEFUSR0=&H3F00 ; A$="Print this in uppercase." ; PRINT A$ ; A=USR0(A$) ; PRINT "CHARS CONVERTED:";A ; A=USR0("This is another test"); ; PRINT "CHARS CONVERTED:";A ; ORGADDR EQU $3f00
start jsr CHKSTR ; ?TM ERROR if not a string. ; X will be VARPTR, B will be string length tstb beq reterror ; exit if strlen is 0 ldy 2,x ; load string addr to Y ldx #0 ; clear X (count of chars conv)
loop lda ,y+ ; get next char, inc Y cmpa #'a ; compare to lowercase A blo nextch ; if less, no conv needed cmpa #'z ; compare to lowercase Z bhi nextch ; if greater, no conv needed suba #32 ; subtract 32 to make uppercase leax 1,x ; inc count of chars converted nextch jsr [CHROUT] ; call ROM output character routine decb ; decrement counter bne loop ; not done yet
tfr x,d ; move chars conv count to D bra return
reterror ldd #-1 ; load -1 as error return jmp GIVABF ; return to caller
Here are the changes… In the original version, I have this:
start jsr INTCNV * get passed in value in D tfr d,x * move value (varptr) to X ldy 2,x * load string addr to Y beq null * exit if strlen is 0 ldb ,x * load string len to B ldx #0 * clear X (count of chars conv)
That first jsr INTCNV expects a number parameter and, if not a number, it exits with ?TM ERROR. If it gets past that, the number is in the D register and it gets transferred over to X. In this case, the number is the value returned by VARPTR:
A=USR0(VARPTR(A$))
That value is the address of the 5-byte string descriptor that contains the address of the actual string data and the length of that data. Y is loaded with 2 bytes in from wherever X points which makes Y contain the address of the string data.
After this is a bug, I think. Looking at the comments, I think that “beq null” should be one line lower, like this:
start jsr INTCNV * get passed in value in D tfr d,x * move value (varptr) to X ldy 2,x * load string addr to Y ldb ,x * load string len to B beq null * exit if strlen is 0 ldx #0 * clear X (count of chars conv)
That way, Y is loaded with the address of the string data, then b is loaded with the length of that data, and the branch-if-equal check is now checking B. If the length is 0, it is an empty string so no processing can be done on it. (That’s a bug, right?)
The new code is this:
start jsr CHKSTR ; ?TM ERROR if not a string. ; X will be VARPTR, B will be string length tstb beq reterror ; exit if strlen is 0 ldy 2,x ; load string addr to Y ldx #0 ; clear X (count of chars conv)
The first line is something I learned from Sean Conner‘s excellent writeup on USR. That is an undocumented ROM call which checks is a variable is a string. If it isn’t, it will return back to BASIC with a ?TM ERROR. By having that check there, if the user tries to pass in a number, that error will be seen. As a bonus, if you try to EXEC that code, that, too, will show ?TM ERROR.
After that, B should be the length of the string so tstb checks that to be 0 (empty string) then the rest of the code is similar.
As I write this, I could have altered the order of my new code to do the tstb/beq after the ldy and then it would be closer to how the original worked. But since the original appears buggy, I won’t worry about that.
Now if I load this and set it up, I should see this:
DEF USR0=&H3F00
A=USR0(42) ?TM ERROR
A=USR0("This is a test") THIS IS A TEST
Also, I notice that the value I return can be -1 if you pass in an empty string…
A=USR0("") OK PRINT A -1
…and if it is non-empty, it is only the count of the characters that had to be converted. So “Hello World” converts the “ello” and “orld” for a return value of 8. It does not touch the uppercase “H” and “W” or the space.
I am not sure that is really useful. The code could be modified to return the length of the string it processed, but at least this way you know that a positive non-zero return value means it did do some work.
What do you use your computer for? [_] Word Processing [_] Businesss [_] Games/Fun [_] Telecom [_] Programming [_] Home Apps. [_] Music/MIDI [_] Graphics
I wrote a BASIC program which will create 68 files named “0.TXT” to “67.TXT”. Each file is 2304 bytes so it takes up a full granule. (That is not really important. It just helps makes things obvious if you look at the disk with a hex editor and want to know which file is at which sector.)
After making these files, it uses code from some of my other examples to scan through the directory and display it (FILEGRAN.BAS code, shown later in this post) and then it scans the directory and prints which granule each 1-gran file is using.
I can start with a freshly formatted disk then run this program and see where RS-DOS put each file.
Will it match the order RS-DOS used when making one huge file that takes up all 68 grans? Let’s find out…
10 '68FILES.BAS 20 PRINT "RUN THIS ON A BLANK DISK." 30 INPUT "DRIVE #";DR 40 'SWITCH TO THAT DRIVE 50 DRIVE DR 60 'GOTO 140 70 'MAKE FILES 0-67 80 FOR G=0 TO 67 90 F$=MID$(STR$(G),2)+".TXT" 100 PRINT "MAKING ";F$; 110 OPEN "O",#1,F$ 120 CLOSE #1:PRINT 130 NEXT 140 'FILEGRAN.BAS 150 'DIR WITHOUT FILE SIZES 160 CLEAR 512:DIM SP$(1) 170 ' S - SECTOR NUMBER 180 FOR S=3 TO 11 190 ' SP$(0-1) - SECTOR PARTS 200 DSKI$ DR,17,S,SP$(0),SP$(1) 210 ' P - PART OF SECTOR 220 FOR P=0 TO 1 230 ' E - DIR ENTRY (4 P/SECT.) 240 FOR E=0 TO 3 250 ' GET 32 BYTE DIR ENTRY 260 DE$=MID$(SP$(P),1+E*32,32) 270 ' FB - FIRST BYTE OF NAME 280 FB=ASC(LEFT$(DE$,1)) 290 ' SKIP DELETED FILES 300 IF FB=0 THEN 440 310 ' WHEN 255, DIR IS DONE 320 IF FB=255 THEN 470 330 ' PRINT NAME AND EXT. 340 'PRINT LEFT$(DE$,8);TAB(9);MID$(DE$,9,3); 350 ' FIRST TWO CHARS ONLY 360 PRINT LEFT$(DE$,2);"-"; 361 'PRINT #-2,LEFT$(DE$,2);","; 370 ' FILE TYPE 380 'PRINT TAB(13);ASC(MID$(DE$,12,1)); 390 ' BINARY OR ASCII 400 'IF ASC(MID$(DE$,13,1))=0 THEN PRINT "B"; ELSE PRINT "A"; 410 ' STARTING GRANULE 420 PRINT USING("## ");ASC(MID$(DE$,14,1)); 421 'PRINT #-2,ASC(MID$(DE$,14,1)) 430 CL=CL+1:IF CL=5 THEN CL=0:PRINT 440 NEXT 450 NEXT 460 NEXT 470 END
I modified this program to output to the printer (PRINT #-2) and then capture that output in the Xroar emulator in a text file. That gave me data which I put in a spreadsheet.
Next, I used a second program on a freshly formatted disk to create one big file fully filling up the disk. (The very last PRINT to the file will create a ?DF ERROR, which I now think is a bug. It should not do that until I try to write the next byte, I think.)
10 '1BIGFILE.BAS 20 PRINT"RUN THIS ON A BLANK DISK." 30 INPUT "DRIVE #";DR 40 'SWITCH TO THAT DRIVE 50 DRIVE DR 60 'MAKE ONE BIG 68 GRAN FILE 70 OPEN "O",#1,"1BIGFILE.TXT" 80 FOR G=0 TO 67 90 PRINT G; 100 T$=STRING$(128,G) 110 FOR T=1 TO 18 120 PRINT "."; 130 PRINT #1,T$; 140 NEXT 150 PRINT 160 NEXT 170 CLOSE #1 180 END
I ran another test program which would read the directory, then print out the granule chain of each file on the disk.
10 ' FILEGRAN.BAS 20 ' 30 ' 0.0 2025-11-20 BASED ON FILEINFO.BAS 40 ' 50 ' E$(0-1) - SECTOR HALVES 60 ' FT$ - FILE TYPE STRINGS 70 ' 80 CLEAR 1500:DIM E$(1),FT$(3) 90 FT$(0)="BPRG":FT$(1)="BDAT":FT$(2)="M/L ":FT$(3)="TEXT " 100 ' 110 ' DIR HOLDS UP TO 72 ENTRIES 120 ' 130 ' NM$ - NAME 140 ' EX$ - EXTENSION 150 ' FT - FILE TYPE (0-3) 160 ' AF - ASCII FLAG (0/255) 170 ' FG - FIRST GRANULE # 180 ' BU - BYTES USED IN LAST SECTOR 190 ' SZ - FILE SIZE 200 ' GM - GRANULE MAP 210 ' 220 DIM NM$(71),EX$(71),FT(71),AF(71),FG(71),BU(71),SZ(71),GM(67) 230 ' 240 INPUT "DRIVE";DR 250 ' 260 ' FILE ALLOCATION TABLE 270 ' 68 GRANULE ENTRIES 280 ' 290 DIM FA(67) 300 DSKI$ DR,17,2,G$,Z$:Z$="" 310 FOR G=0 TO 67 320 FA(G)=ASC(MID$(G$,G+1,1)) 330 NEXT 340 ' 350 ' READ DIRECTORY 360 ' 370 DE=0 380 FOR S=3 TO 11 390 DSKI$ DR,17,S,E$(0),E$(1) 400 ' 410 ' PART OF SECTOR 420 ' 430 FOR P=0 TO 1 440 ' 450 ' ENTRY WITHIN SECTOR PART 460 ' 470 FOR E=0 TO 3 480 ' 490 ' DIR ENTRY IS 32 BYTES 500 ' 510 E$=MID$(E$(P),E*32+1,32) 520 ' 530 ' NAME IS FIRST 8 BYTES 540 ' 550 NM$(DE)=LEFT$(E$,8) 560 ' 570 ' EXTENSION IS BYTES 9-11 580 ' 590 EX$(DE)=MID$(E$,9,3) 600 ' 610 ' FILE TYPE IS BYTE 12 620 ' 630 FT(DE)=ASC(MID$(E$,12,1)) 640 ' 650 ' ASCII FLAG IS BYTE 13 660 ' 670 AF(DE)=ASC(MID$(E$,13,1)) 680 ' 690 ' FIRST GRANUAL IS BYTE 14 700 ' 710 FG(DE)=ASC(MID$(E$,14,1)) 720 ' 730 ' BYTES USED IN LAST SECTOR 740 ' ARE IN BYTES 15-16 750 ' 760 BU(DE)=ASC(MID$(E$,15,1))*256+ASC(MID$(E$,16,1)) 770 ' 780 ' IF FIRST BYTE IS 255, END 790 ' OF USED DIR ENTRIES 800 ' 810 IF LEFT$(NM$(DE),1)=CHR$(255) THEN 1500 820 ' 830 ' IF FIRST BYTE IS 0, FILE 840 ' WAS DELETED 850 ' 860 IF LEFT$(NM$(DE),1)=CHR$(0) THEN 1480 870 ' 880 ' SHOW DIRECTORY ENTRY 890 ' 900 PRINT NM$(DE);TAB(9);EX$(DE);" ";FT$(FT(DE));" "; 910 IF AF(DE)=0 THEN PRINT"BIN"; ELSE PRINT "ASC"; 920 ' 930 ' CALCULATE FILE SIZE 940 ' SZ - TEMP SIZE 950 ' GN - TEMP GRANULE NUM 960 ' SG - SECTORS IN LAST GRAN 970 ' GC - GRANULE COUNT 980 ' 990 SZ=0:GN=FG(DE):SG=0:GC=0 1000 ' 1010 ' GET GRANULE VALUE 1020 ' GV - GRAN VALUE 1030 ' 1040 GV=FA(GN):GM(GC)=GN:GC=GC+1 1050 ' 1060 ' IF TOP TWO BITS SET (C0 1070 ' OR GREATER), IT IS THE 1080 ' LAST GRANULE OF THE FILE 1090 ' SG - SECTORS IN GRANULE 1100 ' 1110 IF GV>=&HC0 THEN SG=(GV AND &H1F):GOTO 1280 1120 ' 1130 ' IF NOT, MORE GRANS 1140 ' ADD GRANULE SIZE 1150 ' 1160 SZ=SZ+2304 1170 ' 1180 ' MOVE ON TO NEXT GRANULE 1190 ' 1200 GN=GV 1210 GOTO 1040 1220 ' 1230 ' DONE WITH GRANS 1240 ' CALCULATE SIZE 1250 ' 1260 ' FOR EMPTY FILES 1270 ' 1280 IF SG>0 THEN SG=SG-1 1290 ' 1300 ' FILE SIZE IS SZ PLUS 1310 ' 256 BYTES PER SECTOR 1320 ' IN LAST GRAN PLUS 1330 ' NUM BYTES IN LAST SECT 1340 ' 1350 SZ(DE)=SZ+(SG*256)+BU(DE) 1360 PRINT " ";SZ(DE) 1370 ' 1380 ' SHOW GRANULE MAP 1390 ' 1400 C=0:PRINT " "; 1410 FOR I=0 TO GC-1 1420 PRINT USING"##";GM(I); 1430 C=C+1:IF C=10 THEN PRINT:PRINT " ";:C=0 ELSE PRINT " "; 1440 NEXT:PRINT 1450 ' 1460 ' INCREMENT DIR ENTRY 1470 ' 1480 DE=DE+1 1490 NEXT:NEXT:NEXT 1500 END 1510 ' SUBETHASOFTWARE.COM
Since there is only one big file on this disk, fully filling it, it only has one 68-entry granule chain to print. I modified the code to PRINT#-2 these values to the virtual printer so I could then copy the numbers into the same spreadsheet:
Now it seems clearly obvious that RS-DOS does something different when making a new file, versus what it does when expanding an existing file into a new granule.
I wanted a way to visualize this so, of course, I wrote a program to help me create a full ASCII representation of the granules, then edited the rest by hand.
Interesting! For small files, it alternates tracks starting before Track 17 (FAT/Directory) then after, repeating. For a big file, it starts like that before Track 17, then after and continues to the end of Track 35, then goes before Track 17 and works back to the start of the disk.
The Micro Works Digisector DS-69 / DS-68B digitizers were really cool tech in the 1980s. Looking back, I got to play with video digitizers, the Super Voice speech synthesizer that could “sing”, and even the E.A.R.S. “electronic audio recognition system” for voice commands. All of this on my Radio Shack Color Computer 3 in the late 1980s.
How many decades did it take for this tech to become mainstream in our phones or home assistants? We did it first ;-)
The DS-69 could capture 128×128 or 256×56 photos with 16 grey levels (4-bit greyscale). It also had a mode where it would capture 64 grey scales, though there was no viewer for this and I cannot find any attempts I made to use this mode.
I did, however, find some BASIC which I *think* I wrote that attempted to read a .PIX file and print it out to a printer using different ASCII characters to represent 16 different levels of grey. For example, a space would be bright white at level 0, and a “#” might be the darkest at level 15.
First, GREYTEST.BAS just tried to print blocks using these characters. I was testing.
5 DIM GR(15):FORA=0TO15:READGR(A):NEXT 10 PRINT#-2,"Grey Scale Printer Test:":PRINT#-2 15 FORA=0TO10:FORB=0TO15:PRINT#-2,STRING$(5,GR(B));:NEXT:PRINT#-2:NEXT 99 END 100 REM * Grey Scale Characters (0-15) 105 DATA 32,46,58,45,105,43,61,84,86,37,38,83,65,36,77,20
I asked the Google search engine, and its Gemini A.I. answered:
Dec. ASCII Value Character ----- --------------------------- 32 Space (invisible character) 46 . (period or full stop) 58 : (colon) 45 - (hyphen or minus sign) 105 i (lowercase i) 43 + (plus sign) 61 = (equals sign) 84 T (uppercase T) 86 V (uppercase V) 37 % (percent sign) 38 & (ampersand) 83 S (uppercase S) 65 A (uppercase A) 36 $ (dollar sign) 77 M (uppercase M) 20 NAK (Negative Acknowledge - a non-printable control character)
I must have been manually counting how many “dots” made up the characters and sorting them. I recall starting with the HPRINT font data in ROM (which is what my MiniBanners program used) to count the set dots in each letter, but the printer fonts would be different so I expect this table came from trial and error.
The 20 NAK (non printable) is an odd one, so I wonder if my printer DID print something for that – like a solid block graphic.
Proving memory is not always faulty, I also found TEST.BAS which appeared to open a .PIX file and print it out using this code:
0 POKE150,44:PRINT#-2,CHR$(27)CHR$(33)CHR$(27)CHR$(77)CHR$(27)CHR$(64)CHR$(15) 1 PRINT#-2 5 DIM GR(15):FORA=0TO15:READGR(A):NEXT 10 OPEN"D",#1,"SMILE.PIX",1:FIELD#1,1ASA$ 11 PRINTLOF(1) 15 FORA=1TO64:PRINTA:FORB=0TO127:GET#1,A+B*64:GR=ASC(A$) 20 PRINT#-2,CHR$(GR(GR AND15)); 25 NEXT:PRINT#-2:NEXT:CLOSE 99 END 100 REM * Grey Scale Characters (0-15) 105 DATA 32,46,58,47,62,63,61,84,86,37,38,90,65,69,77,35
I see line 10 opens the file with DIRECT mode with a field size of 1 assigned to string variable A$. This means doing a GET #1,X (where X is a byte offset in the file) would get that byte into A$ so I could get the ASCii value of it (0-15) and use that to know which character to print.
I have no idea if this worked… So let’s give it a try.
I see the program print “8192”, which is the Length Of File. A 128×128 image of bytes would be 16384 in size, so I am guessing each byte has two pixels in it, each 4-bits.
I see I am ANDing off the upper bits in line 20. It looks like I am throwing away every other pixel since no attempt I made to read those other 4-bits. This is likely because this was printing on an 80 column printer, which would not print 128 characters on a line. Instead, 64 would fit.
And, wow! It actually works! I had to reduce the font size down for it to display in the WordPress blog, but here is the output. Step back from the monitor if you can’t see it.
Since this is a symmetrical pattern, if we can figure out how to draw one quadrant, we can draw the others.
The pattern is 19 characters wide, which contains a center column of asterisks, and a left and right column that are spaces except for the center row of asterisks.
“As if they had planned it,” this means the pattern in each quadrants is 8 characters, matching the number of bits in a byte.
I typed it up to figure out what the bit pattern would be. (Actually, I typed up a bit of it, then pasted that into Copilot and had it tell me the bit pattern.)
That’s a mess, but in the left the “.” would represent the blank space down the left side up to the row of 19 asterisks. After that is the 8-bit pattern with “-” representing a space in the pattern (0 bit) and the “*” representing the asterisk (1 bit).
This let me quickly cobble together a proof-of-concept:
1 READ V 2 A$=STRING$(19,32):MID$(A$,10,1)="*" 3 FOR B=0 TO 7 4 IF V AND 2^B THEN MID$(A$,9-B,1)="*":MID$(A$,B+11,1)="*" 5 NEXT 6 PRINT A$:A$(L)=A$ 7 L=L+1:IF L<8 THEN 1 8 PRINT STRING$(18,42) 9 FOR B=7 TO 0 STEP -1:PRINT A$(B):NEXT 10 DATA 2,81,48,114,9,4,162,81
Line 10 are the 8 rows of byte data for a quadrant of the snowflake.
Line 1 reads the first value from the DATA statement.
Line 2 builds a string of 19 spaces, then sets the character at position 10 (in the center) to an asterisk. Every row has this character set.
Line 3 begins a loop representing each bit in the byte (0-7).
Line 4 checks the read DATA value and ANDs it with the bit value (2 to the power of the the FOR/NEXT loop value). If it is set, the appropriate position in the left side of the string is set to an asterisk, and then the same is done for the right side. To mirror, the left side is center-minus-bit, and the right side is center-plus-bit.
Line 5 is the NEXT to continue doing the rest of the bits.
Line 6 prints the completed string, then stores that string in an A$() array. L has not been used yet so it starts at 0.
Line 7 increments L, and as long as it is still ess than 8 (0-7 for the first eight lines of the pattern) it goes back to line 1 to continue with the next DATA statement.
Line 8 once 8 lines have been done, the center row of 19 asterisks is printed.
Line 9 is a loop to print out the A$() lines we saved, backwards. As they were built in line 6, they went from 0 to 7. Now we print them backwards 7 to 0.
…and there we have a simple way to make this pattern, slowly:
Logiker 2025 pattern on a CoCo.
On a CoCo 3, adding a WIDTH 40 or WIDTH 80 before it would show the full pattern:
Logiker 2025 pattern on a CoCo 3.
My example program can be made much smaller by packing lines together and removing unnecessary spaces. One minor optimization I already did was doing the bits from 0 to 7 which removed the need to use “STEP -1” if counting backwards. Beyond that, this is the raw proof-of-concept idea of using bytes.
Other options folks have used in past challenges included rune-length type encoding (DATA showing how many spaces, then how many asterisks, to make the pattern) so that probably is worth investigating to see if it helps here.
Then, of course, someone will probably figure out a math pattern to make this snowflake.
A correction, and discovering the order RS-DOS writes things…
A correction from part 2… This example program had “BIN” and “ASC” mixed up. 0 should represent BINary files, and 255 for ASCii files. I fixed it in line 920. (I will try to edit/fix the original post when I get a moment.)
10 ' FILEINFO.BAS 20 ' 30 ' 0.0 2023-01-25 ALLENH 40 ' 0.1 2023-01-26 ADD DR 50 ' 0.2 2023-01-27 MORE COMMENTS 55 ' 0.3 2025-11-18 BIN/ASC FIX 60 ' 70 ' E$(0-1) - SECTOR HALVES 80 ' FT$ - FILE TYPE STRINGS 90 ' 100 CLEAR 1500:DIM E$(1),FT$(3) 110 FT$(0)="BPRG":FT$(1)="BDAT":FT$(2)="M/L ":FT$(3)="TEXT " 120 ' 130 ' DIR HOLDS UP TO 72 ENTRIES 140 ' 150 ' NM$ - NAME 160 ' EX$ - EXTENSION 170 ' FT - FILE TYPE (0-3) 180 ' AF - ASCII FLAG (0/255) 190 ' FG - FIRST GRANULE # 200 ' BU - BYTES USED IN LAST SECTOR 210 ' SZ - FILE SIZE 220 ' 230 DIM NM$(71),EX$(71),FT(71),AF(71),FG(71),BU(71),SZ(71) 240 ' 250 INPUT "DRIVE";DR 260 ' 270 ' FILE ALLOCATION TABLE 280 ' 68 GRANULE ENTRIES 290 ' 300 DIM FA(67) 310 DSKI$ DR,17,2,G$,Z$:Z$="" 320 FOR G=0 TO 67 330 FA(G)=ASC(MID$(G$,G+1,1)) 340 NEXT 350 ' 360 ' READ DIRECTORY 370 ' 380 DE=0 390 FOR S=3 TO 11 400 DSKI$ DR,17,S,E$(0),E$(1) 410 ' 420 ' PART OF SECTOR 430 ' 440 FOR P=0 TO 1 450 ' 460 ' ENTRY WITHIN SECTOR PART 470 ' 480 FOR E=0 TO 3 490 ' 500 ' DIR ENTRY IS 32 BYTES 510 ' 520 E$=MID$(E$(P),E*32+1,32) 530 ' 540 ' NAME IS FIRST 8 BYTES 550 ' 560 NM$(DE)=LEFT$(E$,8) 570 ' 580 ' EXTENSION IS BYTES 9-11 590 ' 600 EX$(DE)=MID$(E$,9,3) 610 ' 620 ' FILE TYPE IS BYTE 12 630 ' 640 FT(DE)=ASC(MID$(E$,12,1)) 650 ' 660 ' ASCII FLAG IS BYTE 13 670 ' 680 AF(DE)=ASC(MID$(E$,13,1)) 690 ' 700 ' FIRST GRANUAL IS BYTE 14 710 ' 720 FG(DE)=ASC(MID$(E$,14,1)) 730 ' 740 ' BYTES USED IN LAST SECTOR 750 ' ARE IN BYTES 15-16 760 ' 770 BU(DE)=ASC(MID$(E$,15,1))*256+ASC(MID$(E$,16,1)) 780 ' 790 ' IF FIRST BYTE IS 255, END 800 ' OF USED DIR ENTRIES 810 ' 820 IF LEFT$(NM$(DE),1)=CHR$(255) THEN 1390 830 ' 840 ' IF FIRST BYTE IS 0, FILE 850 ' WAS DELETED 860 ' 870 IF LEFT$(NM$(DE),1)=CHR$(0) THEN 1370 880 ' 890 ' SHOW DIRECTORY ENTRY 900 ' 910 PRINT NM$(DE);TAB(9);EX$(DE);" ";FT$(FT(DE));" "; 920 IF AF(DE)=0 THEN PRINT"BIN"; ELSE PRINT "ASC"; 930 ' 940 ' CALCULATE FILE SIZE 950 ' SZ - TEMP SIZE 960 ' GN - TEMP GRANULE NUM 970 ' SG - SECTORS IN LAST GRAN 980 ' 990 SZ=0:GN=FG(DE):SG=0 1000 ' 1010 ' GET GRANULE VALUE 1020 ' GV - GRAN VALUE 1030 ' 1040 GV=FA(GN) 1050 ' 1060 ' IF TOP TWO BITS SET (C0 1070 ' OR GREATER), IT IS THE 1080 ' LAST GRANULE OF THE FILE 1090 ' SG - SECTORS IN GRANULE 1100 ' 1110 IF GV>=&HC0 THEN SG=(GV AND &H1F):GOTO 1280 1120 ' 1130 ' ELSE, MORE GRANS 1140 ' ADD GRANULE SIZE 1150 ' 1160 SZ=SZ+2304 1170 ' 1180 ' MOVE ON TO NEXT GRANULE 1190 ' 1200 GN=GV 1210 GOTO 1040 1220 ' 1230 ' DONE WITH GRANS 1240 ' CALCULATE SIZE 1250 ' 1260 ' FOR EMPTY FILES 1270 ' 1280 IF SG>0 THEN SG=SG-1 1290 ' 1300 ' FILE SIZE IS SZ PLUS 1310 ' 256 BYTES PER SECTOR 1320 ' IN LAST GRAN PLUS 1330 ' NUM BYTES IN LAST SECT 1340 ' 1350 SZ(DE)=SZ+(SG*256)+BU(DE) 1360 PRINT " ";SZ(DE) 1370 DE=DE+1 1380 NEXT:NEXT:NEXT 1390 END 1400 ' SUBETHASOFTWARE.COM
To test this routine, I created a program that let me type a file size (in bytes) and then it would make a .TXT file with that size as the filename (i.e, for 3000 bytes, it makes “3000.TXT”) and then I could run it through this program and see if everything matched.
It opens a file with the size as the filename, then writes out “*” characters to fill the file. This will be painfully slow for large files. If you want to make it much faster, share your work in a comment.
10 ' MAKEFILE.BAS 20 ' 30 ' 0.0 2025-11-18 ALLENH 40 ' 50 INPUT "FILE SIZE";SZ 60 F$=MID$(STR$(SZ),2)+".TXT" 70 OPEN "O",#1,F$ 80 FOR A=1 TO SZ:PRINT #1,"*";:NEXT 90 CLOSE #1 100 DIR 110 GOTO 50 120 ' SUBETHASOFTWARE.COM
I was able to use this program in the Xroar emulator to create files of known sizes so I could verify the FILEINFO.BAS program was doing the proper thing.
It seems to be, so let’s move on…
A funny thing happened on the way to the disk…
I have been digging in to disk formats (OS-9 and RS-DOS) lately, and learning more things I wish I knew “back in the day.” For instance, I was curious how RS-DOS allocates granules (see part 1) when adding files to the disk. I wrote a test program that would write out 2304-byte blocks of data (the size of a granule) full of the number of the block. i.e., for the first write, I’d write 2304 0’s, then 2304 1’s and so on. My simple program looks like this:
10 'GRANULES.BAS 20 OPEN "O",#1,"GRANULES.TXT" 30 FOR G=0 TO 67 40 PRINT G; 50 T$=STRING$(128,G) 60 FOR T=1 TO 18 65 PRINT "."; 70 PRINT #1,T$; 80 NEXT 90 PRINT 100 NEXT 110 CLOSE #1
I ran this on a freshly formatted disk and let it fill the whole thing up. The very last write errors with a ?DF ERROR (disk full) so it never makes it to the close. I guess you can’t write that last byte without an error?
Now I should be able to look a the bytes on the disk and see where the 0’s went, the 15’s went, and so on, and see the order RS-DOS allocated those granules.
I made a simple test program for this:
0 'GRANDUMP.BAS 10 CLEAR 512 20 FOR G=0 TO 67 30 T=INT((G)/2):IF T>16 THEN T=T+1 40 IF INT(G/2)*2=G THEN S1=10:S2=18 ELSE S1=1:S2=9 50 'PRINT "GRANULE";G;TAB(13);"T";T;TAB(20);"S";S1;"-";S2 54 DSKI$0,T,S1,A$,B$ 55 PRINT "GRANULE";G;ASC(A$) 60 NEXT G
Ignore the commented out stuff. Initially I was just getting it to convert a granule to Track/Sectors with code to skip Track 17 (FAT/Directory). And, to be honest, I had an AI write this and I just modified it ;-)
I then modified it to PRINT#-2 to the printer, and ran it in Xroar with the printer redirected to a text file. That gave me the following output:
Now I can see the order that RS-DOS allocates data on an empty disk.
The number in the third column represents the value of the bytes written to that 2304 granule. When I see “GRANULE 67” contains “34” as data, I know it was the 35th (numbers 0-34) granule written out.
Granules 0-33 are on tracks 0-16, then track 17 is skipped, then the remaining granules 34-67 are on tracks 18-34.
You can see that RS-DOS initially writes the data close to track 17, reducing the time it takes to seek from the directory to the file data. This makes sense, though as a teen, I guess I had some early signs of O.C.D. because I thought the directory should be at the start of the disk, and not in the middle ;-)
I brought this data into a spreadsheet, then sorted it by the “data” value (column 3). This let me see the order that granules are allocated (written to). I will add some comments:
GRANULE 33 0 <- first went to gran 33 GRANULE 32 1 <- second went to gran 32
And down the rabbit hole I go. Again. I have tasked an A.I. with creating some simple scripts to manipulate RS-DOS disk images (just for fun; the toolshed “decb” command already exists and works great and does more). While I understood the basic structure for an RS-DOS disk, I did not understand “how” RS-DOS actually allocated those granules. Now I have some insight. Perhaps I can make my tools replicate writing in the same way that RS-DOS itself does.
Look for a part 4. I have some more experiments to share.