In this 13 minute video, I discuss a bit about my 1994 video game, Invaders09, including game features and details on the cheat mode.

Video: Discussing my 1994 video game, Invaders09.
Leave a reply

In this 13 minute video, I discuss a bit about my 1994 video game, Invaders09, including game features and details on the cheat mode.
I have posted the source code to my 1994 CoCo 3 OS-9 Space Invaders-style game to GitHub:
https://github.com/allenhuffman/Invaders09
Current version is 1.04, from 2015.


Maybe one day I’ll do a 1.05. I never did get around to adding High Scores or a Demo Mode.

Radio Shack introduced the Color Computer in 1980. It came 4K or RAM, and Microsoft Color BASIC in the ROM. It could be expanded to 16K RAM, which allowed adding a second ROM for Extended BASIC. A plug-in disk interface cartridge came later, with it’s own ROM containing Disk BASIC.
I’ve often wondered what Microsoft used to write the CoCo BASIC ROMs in.
Around 1982, Radio Shack released the EDTASM+ ROM-Pak for the Color Computer. It was a 6809 assembler for machine language, as well as a debugger. It could load and save files (source code and final binaries) to cassette tape.
There was also Disk EDTASM+, which added some extra features — though the most important one was probably that it could load and save to a disk drive, making that process far faster.
Someone put up a nice EDTAM+ information page on my CoCoPedia.com website.
Since Microsoft created EDTASM, I suspect it may have been (or was at least based on) the tool they used for writing the Color Computer ROMs.
If you want to see it in action, head over to the JS Mocha CoCo emulator where you will find it available from a menu:
http://www.haplessgenius.com/mocha/
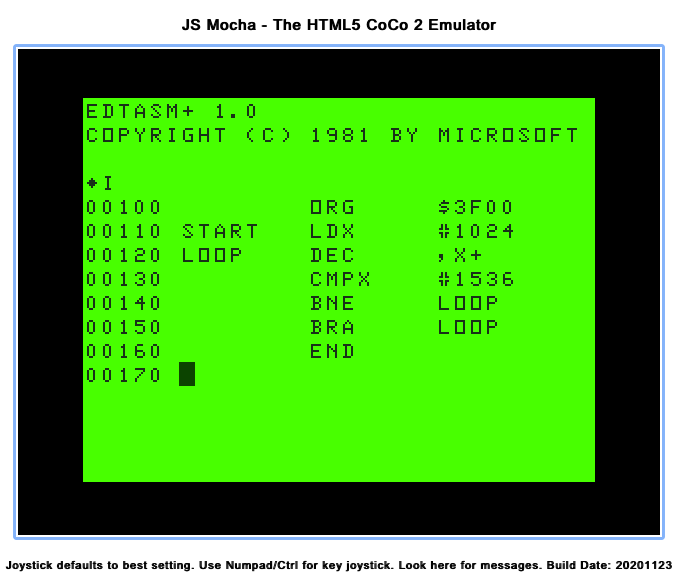
The EDTASM+ ROM-Pak and Bill Barden’s Color Computer Assembly Language Programming book where how I learned 6809 assembly. I later used Disk EDTASM+.
While the CoCo 1 and 2 were basically the same machine, just with redesigned circuit boards and enclosures, the 1986 CoCo 3 was quite different. It could operate in a double speed more, and provided up to 80 columns of text versus the original CoCo’s 32 columns. It also came with 128K — double what the CoCo 1/2 could handle — and could be expanded to 512K (though third party folks figured out how to do 1 an 2 megabyte upgrades).
Unfortunately, Radio Shack never released an update to the EDTASM+ ROM-Pak or disk software. It was still limited to the small memory and screen size of the original 1980 CoCo hardware.
Folks came up with various patches. I had one that patched my Disk EDTASM+ to run in 80 columns on the CoCo 3, in double speed more (faster assembling!) while setting the disk drive step rate to 6ms. It was a much nicer experience coding with long lines!
After this I moved on to OS-9, and used the Microware assemblers (asm and rma) from OS-9 Level 1 and Level 2. I am not sure I touched EDTASM+ again until I played with it on JS Mocha, decades later.
Hitcachi made a clone of the 6809. This replacement chip had some undocumented features such as more registers and more op codes. EDTASM+ couldn’t help with that, but there were some OS-9 compilers that were updated to support it.
That’s when folks like Robert Gault came to our rescue with enhancements for the original EDTASM+. Robert added support for the 6309, and many new features — including CoCo 3 compatibility.
His EDTASM+ looks like this on a CoCo 3 in 80 column mode:
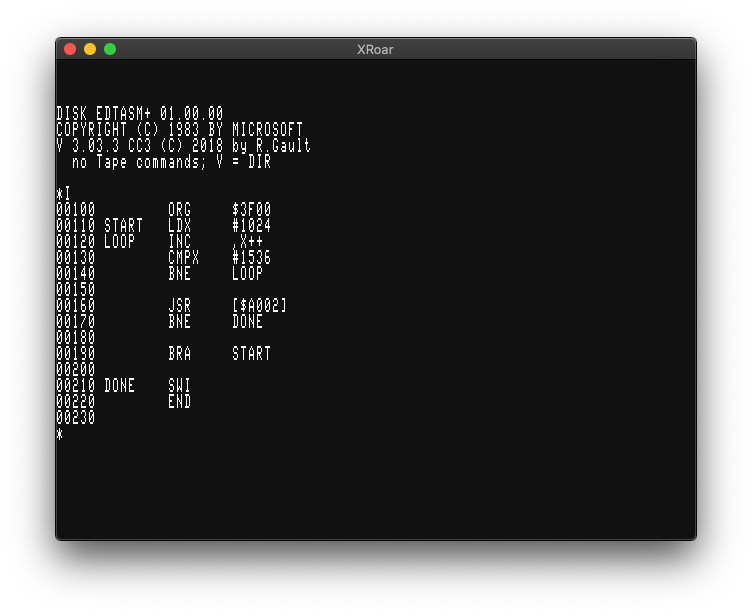
If you notice the copyright date, you’ll see he has continued to update and support it. Today he offers it in a variety of versions that run on the original CoCo 1/2, a CoCo 3, certain emulators, RGB-DOS support (for hard drive users), CoCoSDC (the modern SD card floppy replacement) as well as supporting things like DriveWire.
You can pick up your own copy for $35 as follows:
EDTASM6309 $35 Robert Gault 832 N.Renaud Grosse Pointe Woods, MI 48236 USA e-mail: robert.gault@att.net
There are a number of new features added. Here is the list provided in the README.txt file:
CHANGES TO EDTASM (Tandy Version) 1) Tape is no longer supported; code has been removed. 2) Buffer size increased to over 42K bytes. 3) Directory obtainable from both Editor and ZBUG; V command. 4) Multiple FCB and FDB data per line. 5) FCS supported. 6) SET command now works properly. 7) Screen colors remain as set from Basic before starting EDTASM. 8) Symbol table printed in five names per line on Coco3. 9) On assembly with /NL option, actual errors are printed. 10) Warning error on long branch where short is possible. 11) ZBUG now defaults to numeric instead of symbolic mode. 12) RGB DOS users now have support for drive numbers higher than 3. 13) Hitachi 6309 opcodes are now supported for both assembly and disassembly including latest discoveries. 14) HD6309 detection is included and if present incorporates a ZBUG error trap for illegal opcodes and enables monitoring and changing the E,F,V registers from ZBUG. 15) Coco 3 users can now safely exit to Basic and use their RESET button from EDTASM. 16) Keyboard now has auto repeat keys when keys are held down. 17) Lower case is now supported for commands, opcodes, options, and symbols. Take care when loading or saving files or using symbols, ex. NAME does not equal name, \.A not= \.a, etc. 18) Local names are now supported. Format is A@-Z@ and a@-z@ for 52 local symbols. New sets of locals are started after each blank line in the source code. Local symbols do not appear in or clutter symbol table. 19) Local symbols can only be accessed from ZBUG in expanded form: ex. A@00023 not A@. 20) Now reads source code files that don't have line numbers. Writes normal source files with line numbers ( W filename ) or without line numbers ( W# filename ). 21) Macro parameters now function correctly from INCLUDEd files. 22) While in the Editor, the U key will backup one screen in your source file. 23) DOS.BAS can be used to program the F1 and F2 keys on a Coco3. See below. 24) Coco3 WIDTH80 now uses 28 lines of text. Coco 1&2 versions do require 64K RAM, the Coco 3 version will work with 128K of RAM. You can assemble 6309 code even if your Coco has a 6809 cpu.
It also adds some new commands:
V - obtains a directory from either Editor or ZBUG modes. U - scrolls backwards through source code. FCS - is used exactly like FCC but automatically add $80 to the last character in the string. FCB, FDB - for multiple entries per line entries should be seperated by a comma. Make sure that the comment field for that line DOES NOT CONTAIN ANY COMMAS or an error will result.
If you are wanting to do some CoCo assembly language programming, I highly recommend you sending $35 to Robert and pick up a copy of his version. EDTASM+ is tricky to learn, and his updates make it a bit less tricky.
And tell him Allen sent ya.
Until next time…

Awhile back, the Internet led me to a wondrous thing: an online 6809 emulator, complete with compiler, debugger, and text/graphical output!
This website, “designed and coded” by Gwilym Thomas, is amazing. If has a spot where you can enter 6809 assembly source code, then you can compile and run it!
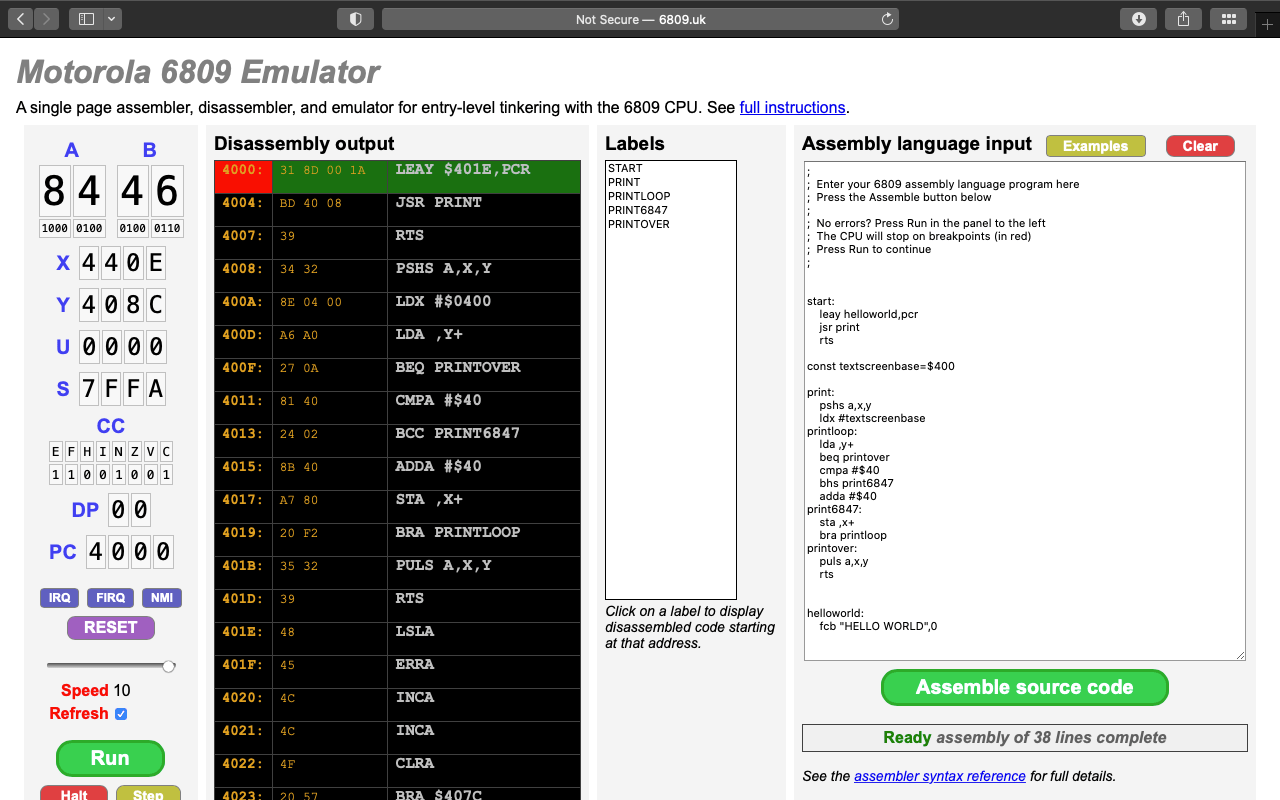
It even has a few sample programs you can select and try out.
While it runs, you see the registers update, as well as a source-level debugger showing what op codes are currently executing. You can set break points, and memory watch points, too.
It also provides text output in the form of the MC6847 VDG chip (used by the CoCo, and a few other systems). The graphics mode is different VDG. While it supports some similar resolutions, it also adds a 16-color display.
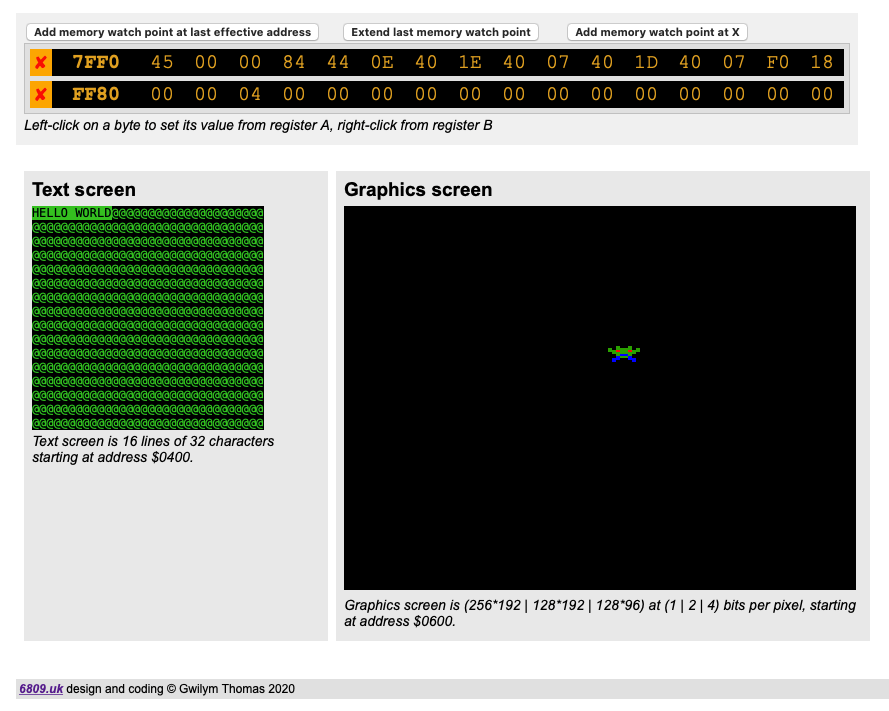
The screen memory is mapped to $400 (1024) just like the CoCo, so you can run stuff like this:
start ldx #1024 loop inc ,x+ cmpx #1536 bne loop bra start
If you past that in to the Assembly language input window and then click Assemble source code, you will see the text characters in the Text screen preview window cycling through values. Neat!
The graphics screen starts just past the text screen at $600 (1536). I think that might be where it started on a non-Disk Extended Color BASIC system. (See my article about memory on the CoCo for more details.)
The documentation notes this about the modes:
The graphics screen is a memory-mapped display of 6144 bytes of RAM beginning at address $0600. There are 3 graphics colour modes, in which either 1, 2, or 4 bits represent a single pixel in 2, 4, or 16 colours respectively. Addresses increase left to right, top to bottom as for the text screen.
Columns and rows are zero-base with (0, 0) at the (left, top). Sequences of bits (1, 2, or 4) from high to low represent pixels from left to right. The 2 colour mode has 256 pixels by 192, the 4 colour 128 by 192, each line being 32 bytes. The 16 colour mode has 128 pixels by 96, each line being 64 bytes.
Example: in 4 colour (2 bit) mode pixel (93, 38) would be in byte $0600+(3832)+trunc (93/4), because there are 4 pixels in a byte. The colour value (0..3) would be stored in bits 5 & 4, ie. shifted left ((4-1)2)-((93 mod 4)*2 times).
http://6809.uk/doc/doku.php?id=interactive_6809_emulator
Changing screen modes is NOT done via simulated VDG registers. Instead, it has code that looks like this:
ldd #$0204 ; select 4 colour graphics mode
swi3
I have not been able to find details on what values represent what mode. Also, the documentation says there is keyboard input:
Click the text screen panel then start typing for the emulator to receive keyboard input. Remember that (due to limitations of the emulated hardware) when lower case characters are printed to the screen they will appear in inverse video.
http://6809.uk/doc/doku.php?id=interactive_6809_emulator
I have not figured out how this works, yet.
As far as the 6809 assembler goes, it does not parse all of the extensions that the LWTOOLS’ lwasm assembler supports, so I have been modifying my projects to be compatible with the emulator’s assembler. This has let me, with minor changes for things like ROM calls, test and debug my code in a way that is impossible on actual hardware.
Here is the documentation:
http://6809.uk/doc/doku.php?id=interactive_6809_emulator
If you create anything interesting in it, please let everyone know in the comments.
In an Internet full of so much garbage, it’s wonderful to find such a gem.
Until next time…

Updates:
A quick tutorial on how to get the Lost Wizard LWTOOLS running under Windows. I have tested this under Windows 11.
To build under Windows, you will need to use a compatibility layer that makes Linux-style code work under Windows. Lost Wizard recommends mingw or Cygwin. This tutorial will use Cygwin.
Go to https://www.cygwin.com/ and download the current Windows installer. It is called “setup-x86_64.exe“.
Run the installer:

Click Next, then choose “Install from Internet”:
Click Next, then either use the default install location, or customize if you know what you are doing. Same thing for installing for “All Users” or “Just Me.” In my example, I am just using the defaults:
Click Next, then select where it will download files. I will just use the defaults:
Click Next, and just use the default Internet Connection settings unless you know what you are doing and need to change them:
Click Next, then select one of the download sites. It shouldn’t matter which one you choose, but since I used to read the old Maddox website hosted on xmission.com, I selected that:
Click Next, and it will retrieve a list of available packages. For building LWTOOLS, you need a C compiler and “make” utility. I went with the standard GCC compiler and standard make.
Expand the “All” then “Devel” items.
Locate the entry that says “gcc-core” (or use the Search box) and click on the “Skip” to the right of it. It should change from “Skip” to a version number (currently 11.3.0-1 as I type this).
Locate the entry that says “make” and do the same (currently 4.3-1 as I type this).
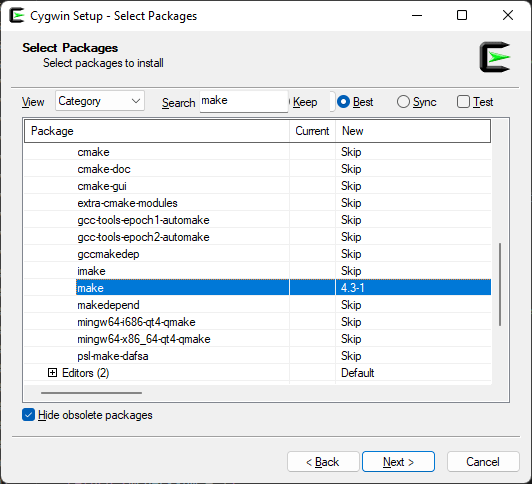
If you would like to download LWTOOLS (and other items) source directly rather than having to download “the most recent release”, you will also need to install “mercurial“. This will give you the “hg” command used to retrieve the latest source code for the projects. (And if you are doing all of this, might as well do this, too.)
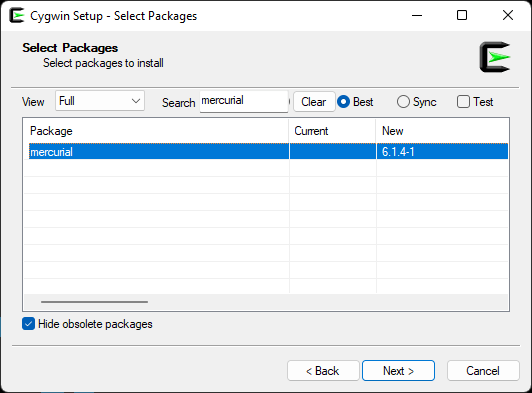
Click Next, and you will see a list of all the required packages that will be download. (When you select an item, this installer will download any other items that are required for the one you selected.)
Click Next, and the download will begin.
When completed, you can click Next and then choose if you want to add a Cygwin icon on your Desktop and/or in the Start Menu. Since you will need to run Cygwin to build LWTOOLS, you may want one or both.
Click Finish. You now have Cygwin!
You can either download the source code and build that, OR you can use Mercurial to retrieve the latest version of the source (which currently includes a bug fix that is not in the release archive yet). Plus, it saves all the steps of extracting the gzipped tar file in 2b ;-)
For either way, you will want to run “Cygwin64 Terminal” that is now installed. This will open up a console prompt.
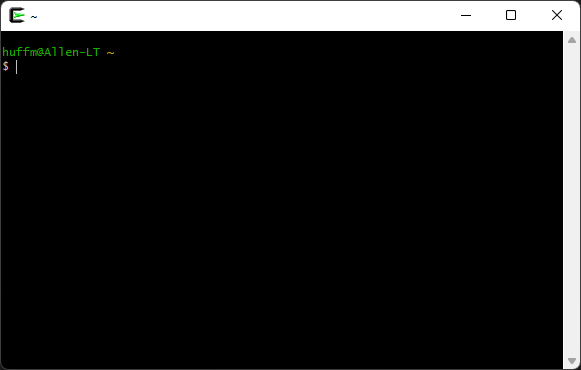
You will need to change directories to where you plan to download the LWTOOLS source code. Cygwin translates the Windows directories like “C:\Users\huffm\Downloads” to a Unix-style directory path like “/cygdrive/c/Users/huffm/Downloads” on my system. If you know how to change directories from a Windows Command Prompt, instead of going to “C:\whatever” you would change backslashes to forward slashes, and start with “/cygdrive/c/whatever”
Use the change directory (“cd”) command and change to where you downloaded the LWTOOLS .gz file.
An easy way to get this path is to type the change directory command in the Cygwin terminal window, followed by a space, (“cd “) and then drag the “Downloads” folder from a Windows Explore window IN to the Cygwin Terminal. It will type out the path to whatever folder you drag and drop there:
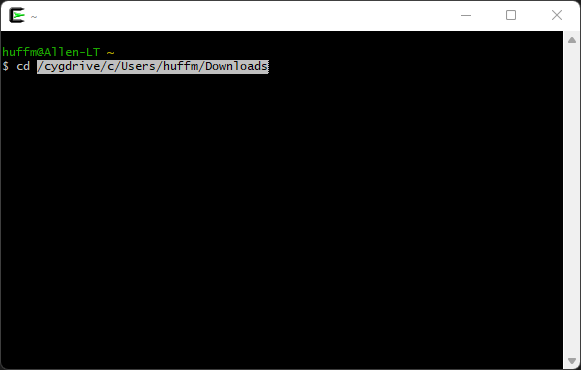
Press enter, and you should now be in the directory where you downloaded the LWTOOLS file. The Cygwin prompt will change to show you what directory you are in. Mine looks like this:
huffm@Allen-LT /cygdrive/c/Users/huffm/Downloads $
From that location, enter this mercurial (“hg”) command:
hg clone http://lwtools.projects.l-w.ca/hg/ lwtools
That will retrieve the latest source and place it in a subdirectory called “lwtools” from here you are. Once complete, proceed to Step 3.
OR, if you want to manually download the latest release…
Go to http://www.lwtools.ca/ and download the latest version (currently 4.19 as I type this). Save it to wherever you chose, above.
The download will be a gzipped .tar file, so you will need some tool to extract it. You can find something in the Windows Store, or just use a command line utility from Cygwin. For this tutorial, we will use the command line.
From this terminal, many Linux-style commands are available, including gzip (which we will use to extract the LWTOOLS .tar file) and tar (which we will use to un-tar that file).
Extract the .gzip file by typing “gzip -d” (for decompress) followed by the lwtools filename:
gzip -d lwtools-4.19.tar.gz
This should extract the “lwtools-4.19.tar” file in to that directory. Now un-tar that file by typing:
tar -xf lwtools-4.19.tar
That will finally leave you with a directory called “lwtools-4.19” (or whatever version you downloaded.
Change directories in to the “lwtools-4.19” directory (or, if you downloaded with Mercurial, in to “lwtools” or whatever you called it):
cd lwtools-4.19
Once you are there, all you need to do is type “make” to begin the build process.
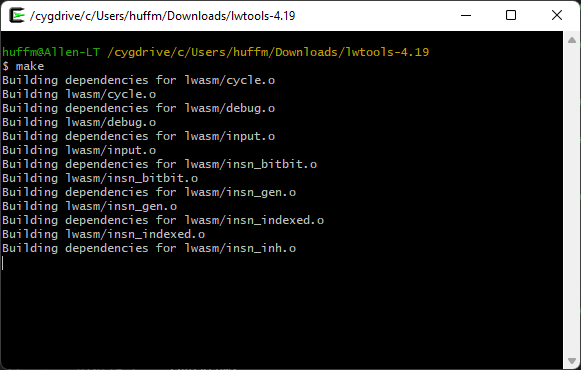
Once complete (it may take awhile), the binaries have been built, but they aren’t located where Cygwin can run them yet. To copy them over in to the proper location, type “make install“:
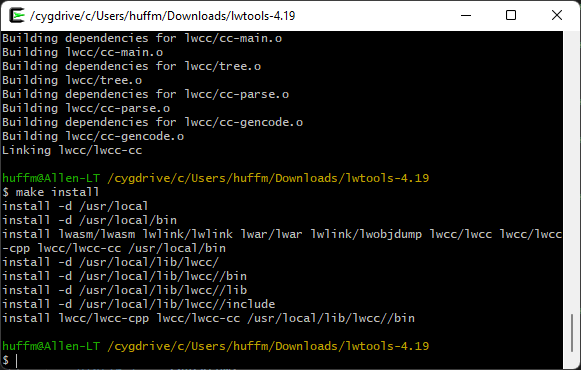
You now have some new command line programs available from within Cygwin. To verify that they worked, you can try typing them to see if they bring up their usage display. Try typing:
lwasm --usage
If you get back a “Usage:” message, you should now be ready to use LWTOOLS to compile 6809 assembly language for the CoCo.
Toolshed is a series of commands for copying files from your PC in to disk image files used by emulators or things like the CoCoSDC.
NOTE: Currently, this will not work. Some rules have changed in the compiler and it will error out. There are about 12 places in the source that can easily be fixed to make it build, but I’m going to wait and see if the Toolshed maintainers have a solution.
hg clone http://hg.code.sf.net/p/toolshed/code toolshed cd toolshed make -C build/unix install cd ..
NitrOS9 is a 6809 (or 6309) operating system based on Microware OS-9/6809.
hg clone http://hg.code.sf.net/p/nitros9/code nitros9 cd nitros9 make dsk
As a simple test, use a text or code editor to create the following “helloworld.asm” file. You will need to know where you save this file, since you will be typing that on the command line to build it. On my system, I have all my .asm files in a directory, and I just “cd” to that directory from the Cygwin terminal.
* helloasm.asm
org $3f00
ldx #message
loop:
lda ,x+
beq done
jsr [$a002]
bra loop
done:
rts
message fcc "HELLO WORLD!"
fcb 13
fcb 0
This simple program will display the message “HELLO WORLD!”. It does this by using the Color BASIC “CHROUT” ROM call. This code starts by loading X with the address of a text message that is a series of characters, followed by a 13 (carriage return) and a 0 to mark the end of the message. The main loop loads the A register with whatever is at X, and if it is zero it ends. Otherwise, it calls the CHROUT routine indirectly by jumping to the location stored at $a002 in the ROM. It will repeat this until it gets to the 0 at the end of the message.
LWTOOLS can build .bin files that can be transferred to a CoCo (or emulator) on a disk image (using other tools), and then you can LOADM that file and EXEC it:
lwasm helloasm.asm -fdecb -ohelloasm.bin
Above, that takes the input file “helloasm.asm” and compiles it in format “decb” (a .bin binary) and calls the output file “helloasm.bin”. (You’d probably want all uppercase for filenames on the CoCo.) That should give a LOADM-able file to try.
But, a nifty feature of LWTOOLS is the ability to generate a BASIC program that loads the assembly language. Use the format “basic” and make the output file a “.bas” instead:
lwasm helloasm.asm -fbasic -ohelloasm.bas
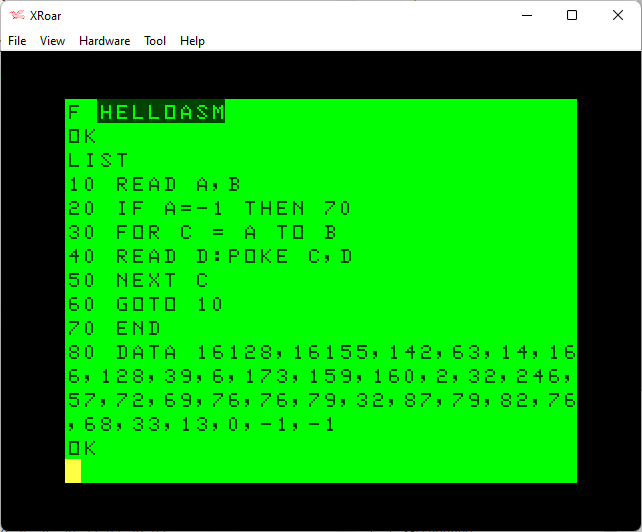
That will create a text file called “helloasm.bas”:
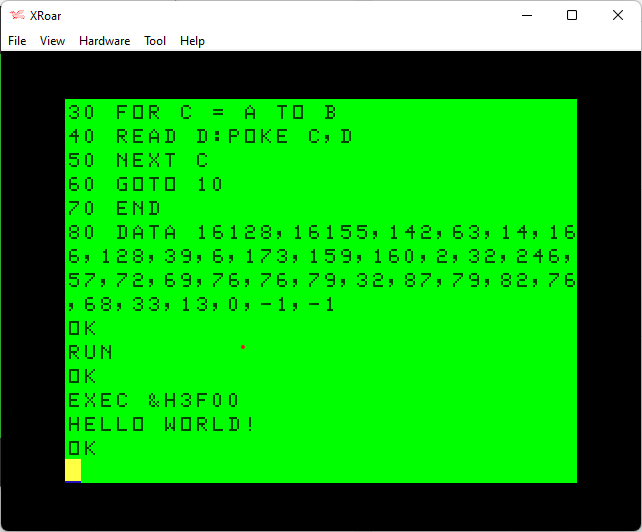
10 READ A,B 20 IF A=-1 THEN 70 30 FOR C = A TO B 40 READ D:POKE C,D 50 NEXT C 60 GOTO 10 70 END 80 DATA 16128,16155,142,63,14,166,128,39,6,173,159,160,2,32,246,57,72,69,76,76,79,32,87,79,82,76,68,33,13,0,-1,-1
I like to use the XRoar emulator, since it lets me load a text file as if it was a cassette file. You can run XRoar, then use Ctrl-L (or File->Load) then select the “helloasm.bas” file. After that is done, typing “CLOAD” in XRoar will load this text file as if it was coming from tape!
Then you can “RUN” the program and load your assembly in to memory. For this example, the address of $3f00 was specified in the source codes “org” address (16128 in decimal) so that is where the code would load. After the “RUN”, you should be able to type “EXEC &H3f00” (or EXEC 16128 if not using Extended Color BASIC) and see the program run:
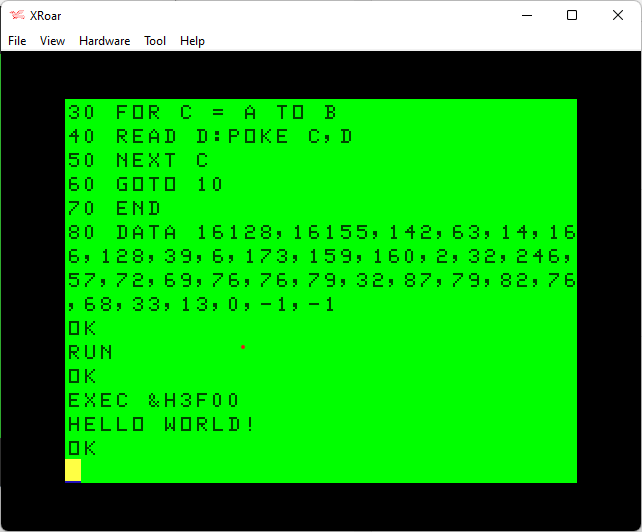
Have fun!
Until next time…
Okay, 6809 folks… In my 64K TRS-80 CoCo memory test article, I used an assembly language program of unknown origin to copy the CoCo’s ROM in to RAM. The “test” part is POKEing a byte in to ROM space and seeing if it now changes (since, on a 64K system, it would be running out of RAM).

That code looks like it was built for speed, moving 6 bytes at a time by using three 16-bit registers (X, Y and U). As a refresher, here is that code:
start:
PSHS CC
ORCC #$50
LDY #$8000
loop1:
STA $FFDE
LDD ,Y
LDX $02,Y
LDU $04,Y
STA $FFDF
STD ,Y++
STX ,Y++
STU ,Y++
loop2:
CMPY #$FEFC
BCS loop1
CMPY #$FF00
BCC done
STA $FFDE
LDD ,Y
STA $FFDF
STD ,Y++
BRA loop2
done:
PULS CC
RTS
I presented this routine as a BASIC loader program so one could easily type it in rather than needing an assembler and typing in assembly source code to compile.
For folks patient enough to type in a whole CoCo screen full of hexadecimal DATA statements, it works fine. But I thought it might be finer to present an even smaller program with less DATA statements.
The program size can almost be cut in half by eliminating the first loop that copies the 6 bytes at a time. Instead, I came up with something like this:
start:
PSHS CC Save CC
ORCC #$50 Mask interrupts
LDX #$8000 Start of ROM
loop:
STA $FFDE Enable ROM
LDD ,X Load D with whatever is at X
STA $FFDF Disable ROM
STD ,X++ Store D at X and increment X
CMPX #$FF00 Is X past end of ROM?
BNE loop If not, repeat
PULS CC Restore CC
RTS Return
The original “need for speed” version compiled to 53 bytes. This new version compiles to 25 bytes. That would make it much easier to type in, like this:
0 REM 64K ROM TO RAM (25) 10 FOR L=16128 TO 16152 20 READ V:POKE L,V 30 NEXT 40 EXEC 16128:POKE 44015,89 80 DATA 52,1,26,80,142,128,0 90 DATA 183,255,222,236,132 100 DATA 183,255,223,237,129 110 DATA 140,255,0,38,241,53 120 DATA 1,57
Is there anything I can do to save a few bytes in that ROM to RAM routine? Please share comments and suggestions.
If the goal is to just test for the existence of 64K, all we really need to do is put the machine in RAM mode and try to modify a byte in the upper 32K. If it can be modified, 64K is there. Maybe there is an even smaller way just to do that?
In 64K, you have memory locations 0-65535 available ($0000-$FFFF). But, the last 255 bytes ($FF00-$FFFF) are used for I/O, and as far as I know, the RAM there cannot be accessed. (Is this correct?) That would mean the last byte of usable RAM on a 64K CoCo would be at $FF00-1 ($FEFF). If that is correct, all we need to do is switch to RAM mode, store a byte at $FEFF and then read it back and see if it is what we put there. If it is, 64K exists.
There is a ROM routine that will output whatever character is loaded in the A register. We could use that to print out a message if 64K exists. Since the goal is to make this as small as possible, the message could simply be ‘Y’. My first attempt was something like this:
start:
PSHS CC Save CC
ORCC #$50 Mask interrupts.
STA $FFDF Disable ROM
LDA #'Y Load A with 'Y'
STA $FEFF Store A in last RAM byte
CLRA Clear A
LDA $FEFF Load A with last RAM byte
CMPA #'Y Compare to 'Y'
BEQ done If Y, done.
LDA #'N Else, load A with 'N'
done:
STA $FFDE Enable ROM
PULS CC Restore CC
JSR [$A002] Output byte in A to console.
RTS Return
I disable the ROM (going in to “all RAM mode”), load A with a ‘Y’ character, then store it at $FEFF. I then clear A, then load A with whatever is at $FEFF. I compare A with ‘Y’ and if it is, I branch to the end where it will re-enable ROM, restore the CC register, then jump to the ROM routine that outputs whatever is in A. If it had no equaled ‘Y’, it would have not branched to ‘done’ and would instead load A with ‘N’, then complete, outputting ‘N’.
Running that should print out Y or N, depending on if 64K is detected.
And it works! But it is larger than the 64K ROM TO RAM code, taking up 32 bytes. I suppose there could be less typing since now the “ROM to RAM” program wouldn’t need to POKE the ‘OK’ prompt to show the user if it can be changed, so this probably is better.
0 REM 64KTEST1.BAS (32) 10 FOR L=16128 TO 16159 20 READ V:POKE L,V 30 NEXT 40 EXEC 16128 50 DATA 52,1,26,80,183,255,223 60 DATA 134,89,183,254,255,79 70 DATA 182,254,255,129,89,39 80 DATA 2,134,78,183,255,222 90 DATA 53,1,173,159,160,2,57
However … If we don’t want to be as user-friendly (printing a ‘Y’ or ‘N’), maybe some bytes could be saved by just setting a byte on the 32-column screen to indicate the result. I tried this:
start:
PSHS CC Save CC
ORCC #$50 Mask interrupts.
STA $FFDF Disable ROM
CLR $FEFF
DEC $FEFF
LDA $FEFF
done:
STA $FFDE Enable ROM
PULS CC Restore CC
STA $0400
RTS Return
For this routine, I save CC and disable interrupts, then disable ROM. I then clear memory location $FEFF, and then try to Decrement whatever is there. If the CLR worked, it should be 0, and a DEC would turn it in to 255. To see what happened, I load A with whatever is at $FEFF, re-enable ROM, restore CC and then store whatever I loaded in to A to the top left of the 32 column screen. If 64K is present, an orange graphics block (255) should appear in the top left of the screen. If not, whatever value in ROM at $FEFF will be stored that. On my CoCo, that is a 0, so I should see an inverted ‘@’ sign appear on a non-64K system. This isn’t perfect, since if ROM just happened to contain 255 at that location, this test would not work.
This is 25 bytes of code. Still no savings, but the BASIC program could be smaller, which is the end goal:
0 REM 64KTEST2.BAS (25) 10 FOR L=16128 TO 16152 20 READ V:POKE L,V 30 NEXT 40 EXEC 16128 50 DATA 52,1,26,80,183,255,223 60 DATA 127,254,255,122,254 70 DATA 255,182,254,255,183 80 DATA 255,222,53,1,183,4,0,57
Line 40 should really be “CLS:PRINT:EXEC 16128”, otherwise the user would have to make sure they weren’t at the end of the screen when they ran it, since the next output would scroll and overwrite whatever the program POKEd to the top left of the screen.
Is this good enough?
Do you have better ideas?
Please share your thoughts in the comments.
Until next time…
In a recent article here, I explored the Logiker Vintage Computing Christmas Challenge 2021. The goal was to create a BASIC program that displayed a test Christmas tree:

The discussion continued in a follow-up article I posted a bit later. Check out those two postings, as well as the comments, for the full discussion. In the end, I used a suggested approach of encoding the length of each line (the number of characters to print as a centered string) in ASCII, so an ‘A’ represented one, ‘B’ would be two, and so on. To convert ASCII to the values needed, the program would do a subtract 64:
0 FORC=1TO14:W=ASC(MID$("ACEGCGKOEKQWCC",C))-64:PRINTTAB(16-W/2)STRING$(W,42):NEXT
On May 30, Sebastian T posted a new comment to that article with a suggestion that would reduce this program’s 64-byte size to 61 by getting rid of the “-64” bytes:
It would be nice to get rid of the “-64” part after the ASC() function, as this would save another 3 bytes, reducing the program size from 64 to 61 bytes.
All you have to do is to replace the characters inside the string with lower ASCII values just as needed, like &H01, &H03, &H05 and so on.
– Sebastian T. (5/30/2022)
Indeed, if instead of having “A”, “B”, “C”, etc. you could put in the raw bytes of 0, 1 and 2, that subtraction would not be needed. It is possible to alter BASIC programs to do this, but they create programs that are impossible for a user to type in from a listing. (I experimented with such a trick when I was working on a BASIC Pac-Man program.)
Or so I thought. Sebastian continued with a very clever approach/solution to typing in an un-typeable program:
You cannot use the keyboard to edit the string in this way, but I did write some self-modifying code that replaced the characters directly in program memory. After this, you can erase the extra code and you are left with a fully functional version that is 61 bytes long.
– Sebastian T. (5/30/2022)
What an interesting approach! Provide a fully typeable BASIC program which contains self-modifying code. Run the routine that self-modifies, then delete the self-modifying routine and save out the final program. Here is Sabastian’s example:
0 FORC=1TO14:W=ASC(MID$(“ACEGCGKOEKQWCC”,C)):PRINTTAB(16-W/2)STRING$(W,42):NEXT 10 ‘ 20 ‘FIND FIRST STRING IN THE BASIC PROGRAM MEMORY AND HACK IT! 30 S=PEEK(25)256+PEEK(26) ‘START OF BASIC CODE IN MEMORY 40 E=PEEK(27)256+PEEK(28) ‘END OF BASIC CODE IN MEMORY 50 FOR A=S TO E 60 IF F THEN READ V : IF V<0 THEN END ELSE POKE A,V 70 IF PEEK(A)=34 THEN F=-1 ‘TOGGLE FLAG UPON REACHING THE FIRST QUOTATION MARK 80 NEXT A 90 DATA 1,3,5,7,3,7,11,15,5,11,17,23,3,3,-1
Sebastian concludes:
Run it once, then do a DEL 10-90. Run it again to verify it still fulfills the original task, and it does!
Some comments:
1) All tests done in XROAR 1.0.1 emulating a COCO 1 with 32k RAM.
2) I removed the “-64” before modifying the string, but you can also do it afterwards, even though the EDIT function will behave a bit funny while skipping over the non-printable characters in the string constant, but it works. I tested both ways.
3) If one of the characters had been 0 or 34 (quotation mark) this would have not worked. But this was not the case, so I got away with this. I’m not sure if there are other forbidden characters to consider, if somebody knows about this please comment.
4) In order to make sure this was still a valid program, I CSAVE’d it in a virtual cassette file, did a cold restart and reloaded the saved program. It works!
5) If you LIST the program, you’ll see a supposedly empty string inside the MID$() function, however it is not empty! I wrote a small memory monitor to verify this.
6) RENUM function won’t work now, though.
In summary, this trickery allows reduction of the final program size from 64 to 61 bytes.
Best regards!
– Sebastian T. (5/30/2022)
What an interesting approach. One can now type in a longer BASIC program, run it, DELete some lines, then end up with a smaller final program.
For BASIC programmers who used modified code for things like this, I suppose they were doing something like this. There would be a master program that could be edited and worked on, with routines at the end to modify strings and such, and then after the modification was ran, a second copy would be saved that could not be easily edited later.
And now we have a two-step way of creating a 61 byte version of that program.
Nicely done, Sebastian!
Until next challenge…
I recently had a request on Fiverr to try to shaper up an out-of-focus video. I thought I might be able to do it using Topaz Labs Video Enhance AI. After several attempts, I concluded that this was not the right tool for the job. While it did have the ability to sharpen video, even on the highest settings it was not sufficient.
Instead, Ida at Topaz Labs support suggested converting the video in to individual images and processing them through their Topaz Labs Sharpen AI product. After a number of attempts to convert the video to individual images, I ended up using the open source FFmpeg program.
Using the option “-i” to specify the input video file, and “-vf” for the video filter with the options “fps” for how many frames per second to process and finally the output filename format.
For fps, if you want to capture every frame of the video, set this to the frames per second of the video file. In this example, the original video was 25 frames per section:
ffmpeg.exe -i VIDEO.MP4 -vf fps=25 out%d.png
For the output filename, you can use C printf-style variables such as %d so it knows where to place the number in the filename. Above, that would produce “out1.png”, “out2.png”, and so on.
Once you have all the frame images, they can be imported in to Sharpen AI and processed. This will produce new output filenames adding “-SharpenAI-Focus” or similar to the filename. You can then reassemble those individual images back in to a movie.
The option “-framerate” is used to generate that many frames per second in the new movie file. It should match the -fps value used above.
“-i” is used to tell FFmpeg what filenames to look for. It will also use the C printf-style parameters. Since Sharpen AI takes “out1.png” and creates a new file called “out1-SharpenAI-Focus.png” (when using the focus mode), I needed to match that filename.
The first video I created would not play, and I found setting “-pix_fmt” would make a playable MP4 file.
ffmpeg.exe -framerate 25 -i out%d-SharpenAI-Focus.png -pix_fmt yuv420p NEWVIDEO.MP4
There are other options that can be used to set quality levels, so I may revise this article in the future when I use this technique the next time.
Until then…

Updates:
I am posting this now in case it helps someone else who is trying to figure this out. My goal is to be able to modify a video recorded in Bullet Time mode to appear as a normal 360 video file. I just need to figure out what bytes to zap in the file…
Over in the Insta360 REDDIT forum, user SalsaGreen pointed me to this Github repository:
https://github.com/nivim/Insta360toBlackBoxCSV
It contains a Python script that parses the .insv files to export accelerometer and exposure data. This gave me a good starting point for exploring the .insv file format.
From there, searches led me to the ExifTool by Phil Harvey, which has support for parsing .insv files. Here is the parsing code:
https://github.com/exiftool/exiftool/blob/master/lib/Image/ExifTool/QuickTimeStream.pl
The last 32-bytes of the file will be this special string of characters:
8db42d694ccc418790edff439fe026bf
If those characters exist, parsing can begin.
The end of the file looks like this, with offsets being bytes from the end of the file:
Offset Length Description ------ ------ ----------- -78 42? Trailer -36 4? ? -32 32 Magic phrase '8db42d694ccc418790edff439fe026bf' 0 0 End of File
The trailer is a series of (up to seven?) entries containing a 2-byte ID followed by a 4-byte offset. I am unsure if the entries are fixed, or if they can be terminated by 0x0000 / 0x00000000 entries if not all segments appear.

Segments defined in the Github Python script include:
This makes the end of the file look like this:
Offset Length Description ------ ------ ----------- -78 2 Trailer entry #1 - ID -76 4 Trailer entry #1 - Size -72 2 Trailer entry #2 - ID -70 4 Trailer entry #2 - Size -66 2 Trailer entry #3 - ID -64 4 Trailer entry #3 - Size -60 2 Trailer entry #4 - ID -58 4 Trailer entry #4 - Size -54 2 Trailer entry #5 - ID -52 4 Trailer entry #5 - Size -48 2 Trailer entry #6 - ID -46 4 Trailer entry #6 - Size -44 2 Trailer entry #7 - ID -40 4 Trailer entry #7 - Size -36 4? ? -32 32 Magic phrase '8db42d694ccc418790edff439fe026bf' 0 0 End of File
Parsing begins at offset -78 by reading the 2-byte ID and 4-byte Size. The data for that ID will be located Size bytes earlier in the file. Data parsers for each segment seek there and begin parsing.
I have now found that ExifTool can be used to display these items. It does not show the Trailer information by default, but here is a command that displays it in .json format:
exiftool -ee -G -s -b -j -a -T filename.insvWORK-IN-PROGRESS: The “maker notes” section appears to use a byte for the type of data, then a byte for the length of that data segment. Some of the bytes appear to be (QuickTime::INSV_MakerNotes)
Hex Dec Description
--- --- -----------
0x0A 10 Serial Number ("IXSE42xxxxxxxx")
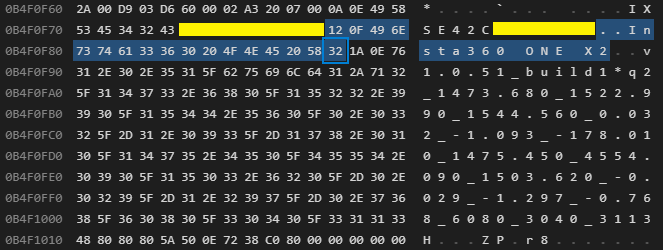
0x12 18 Camera Model ("Insta260 ONE X2")
0x1A 26 Firmware Version ("v1.0.51_build1")
0x2A 42 ? Parameters ?
NOTE: It appears that this section (0x0101) may be hard-coded to only have four entries, and the parser just reads four entries and stops. I was expecting some kind of record size or end of record marker, but looking at the ExifTool source shows it just does a for/next loop of 0-3.
Serial Number
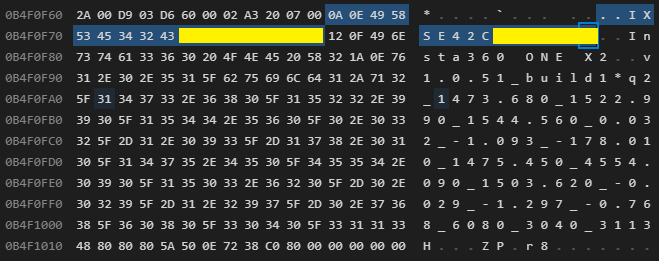
Model
Firmware
Parameters
A simple parser I wrote in C can parse out some of these, then it gets lost at the binary data, so there is more to it than just that:
Magic Phrase: 8db42d694ccc418790edff439fe026bf
Good file.
0x0101 0x0000073a - Maker Notes
-------------------------------------------------------------------------------
Maker Notes - offset -1928
-------------------------------------------------------------------------------
Type: 0x0a (10) - SerialNumber
Length: 0x0e (14)
Data: 49 58 53 45 34 32 xx xx xx xx xx xx xx xx (edited out)
Text: IXSE42xxxxxxxx (edited out)
Type: 0x12 (18) - Model
Length: 0x0f (15)
Data: 49 6e 73 74 61 33 36 30 20 4f 4e 45 20 58 32
Text: Insta360 ONE X2
Type: 0x1a (26) - Firmware
Length: 0x0e (14)
Data: 76 31 2e 30 2e 35 31 5f 62 75 69 6c 64 31
Text: v1.0.51_build12
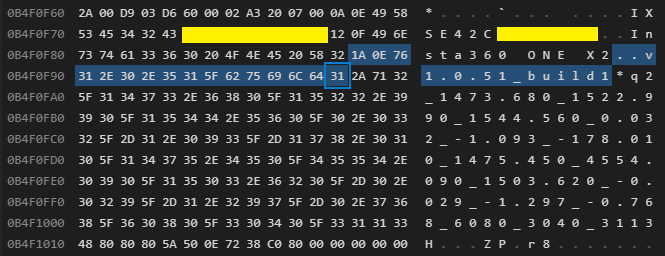
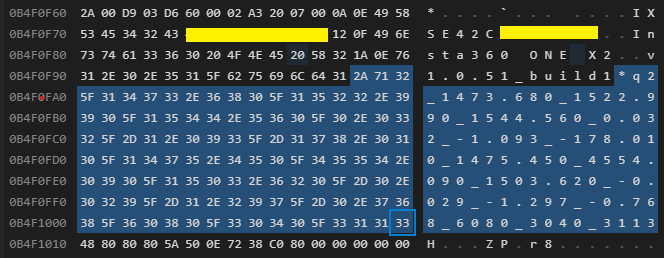
Type: 0x2a (42) - Parameters
Length: 0x71 (113)
Data: 32 5f 31 34 37 33 2e 36 38 30 5f 31 35 32 32 2e
39 39 30 5f 31 35 34 34 2e 35 36 30 5f 30 2e 30
33 32 5f 2d 31 2e 30 39 33 5f 2d 31 37 38 2e 30
31 30 5f 31 34 37 35 2e 34 35 30 5f 34 35 35 34
2e 30 39 30 5f 31 35 30 33 2e 36 32 30 5f 2d 30
2e 30 32 39 5f 2d 31 2e 32 39 37 5f 2d 30 2e 37
36 38 5f 36 30 38 30 5f 33 30 34 30 5f 33 31 31
33
Text: 2_1473.680_1522.990_1544.560_0.032_-1.093_-178.010_1475.450_4554.090_1503.620_-0.029_-1.297_-0.768_6080_3040_3113
0x0000 0x00000000 - Unknown
0x0000 0x00000000 - Unknown
0x0000 0x00000000 - Unknown
0x0000 0x00000000 - Unknown
0x0000 0x00000000 - Unknown
0x0000 0x000f16f4 - Unknown
More work to be done on this part…
TODO
TODO
TODO
TODO
To be continued…
/*--------------------------------------------------------------------------*/
// .insv parser test.
//
// 2022-06-08 0.00 allenh - Initial brute-force version.
// 2022-06-09 0.01 allenh - Code cleanup, more defines.
/*--------------------------------------------------------------------------*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h> // for memset()
#include <stdint.h>
#include <stdbool.h>
#define FILENAME "VID_20220607_102410_00_322.insv"
//#define FILENAME "VID_20220607_104109_00_323.insv"
/*--------------------------------------------------------------------------*/
// Defines / Constants / Enums
/*--------------------------------------------------------------------------*/
#define TRAILER_OFFSET -78
#define TRAILER_SIZE 42
#define MAGIC_PHRASE_OFFSET -32
#define MAGIC_PHRASE_SIZE 32
#define MAGIC_PHRASE_STRING "8db42d694ccc418790edff439fe026bf"
enum
{
HID_MAKER_NOTES = 0x0101,
HID_ACCELEROMETER = 0x0300,
HID_EXPOSURE = 0x0400,
HID_TIMESTAMPS = 0x0600,
HID_GPS = 0x0700
} HidEnum;
enum
{
MAKER_NOTES_SERIALNUMBER = 0x0a,
MAKER_NOTES_MODEL = 0x12,
MAKER_NOTES_FIRMWARE = 0x1a,
MAKER_NOTES_PARAMTERS = 0x2a
} MakeNotesEnum;
/*--------------------------------------------------------------------------*/
// Prototypes
/*--------------------------------------------------------------------------*/
bool checkForMagicPhrase (FILE *fp);
bool parseTrailer (FILE *fp);
bool parseMakerNotes (FILE *fp, long int offset);
const char *getHidString (unsigned int hid);
const char *getMakerNotesString (unsigned int id);
uint32_t freadU32 (FILE *fp);
uint16_t freadU16 (FILE *fp);
uint8_t freadU8 (FILE *fp);
void hexDump (void *ptr, size_t size);
/*--------------------------------------------------------------------------*/
// Main
/*--------------------------------------------------------------------------*/
int main (int argc, char **argv)
{
(void)argc;
(void)argv;
FILE *fp = NULL;
fp = fopen (FILENAME, "rb");
if (fp != NULL)
{
if (checkForMagicPhrase (fp) == true)
{
printf ("Good file.\n");
parseTrailer (fp);
}
}
else
{
perror ("Unable to open");
}
fclose (fp);
return errno;
}
/*--------------------------------------------------------------------------*/
// Functions
/*--------------------------------------------------------------------------*/
/*--------------------------------------------------------------------------*/
// Check for the 32-byte magic phrase at the end of the file.
/*--------------------------------------------------------------------------*/
bool checkForMagicPhrase (FILE *fp)
{
bool status = false;
if (fp != NULL)
{
int retVal = 0;
retVal = fseek (fp, MAGIC_PHRASE_OFFSET, SEEK_END);
if (retVal == 0) // If successful, the function returns zero.
{
size_t bytesRead = 0;
char buffer[MAGIC_PHRASE_SIZE+1];
memset (buffer, 0x0, sizeof(buffer));
bytesRead = fread (buffer, sizeof(buffer[0]), MAGIC_PHRASE_SIZE, fp);
if (bytesRead == MAGIC_PHRASE_SIZE)
{
if (strncmp (buffer, MAGIC_PHRASE_STRING, sizeof(buffer)) == 0)
{
// Match.
printf ("Magic Phrase: %s\n", buffer);
status = true;
}
}
}
}
return status;
}
/*--------------------------------------------------------------------------*/
// Parse Trailer.
/*--------------------------------------------------------------------------*/
bool parseTrailer (FILE *fp)
{
bool status = false;
if (fp != NULL)
{
int retVal = 0;
long int offset = 0;
offset = TRAILER_OFFSET;
while (offset < TRAILER_OFFSET+TRAILER_SIZE)
{
retVal = fseek (fp, offset, SEEK_END);
if (retVal == 0)
{
uint16_t hid = 0;
uint32_t size = 0;
hid = freadU16 (fp);
size = freadU32 (fp);
printf ("0x%04x 0x%08x - %s\n", hid, size, getHidString (hid));
switch (hid)
{
case HID_MAKER_NOTES:
parseMakerNotes (fp, offset-size);
break;
}
offset = offset + sizeof(uint16_t) + sizeof(uint32_t);
}
}
}
return status;
}
/*--------------------------------------------------------------------------*/
// Parse INSV_MakerNotes section.
/*--------------------------------------------------------------------------*/
bool parseMakerNotes (FILE *fp, long int offset)
{
bool status = false;
uint8_t type = 0;
uint8_t length = 0;
size_t bytesRead = 0;
uint8_t buffer[255];
printf ("-------------------------------------------------------------------------------\n");
printf ("Maker Notes - offset %ld\n", offset);
printf ("-------------------------------------------------------------------------------\n");
// There can be only four?
for (int entryNumber=0; entryNumber < 4; entryNumber++)
{
if (offset >= TRAILER_OFFSET) // Hack.
{
break;
}
fseek (fp, offset, SEEK_END);
type = freadU8 (fp);
length = freadU8 (fp);
printf (" Type: 0x%02x (%u) - %s\n", type, type, getMakerNotesString (type));
printf ("Length: 0x%02x (%u)\n", length, length);
bytesRead = fread (buffer, sizeof(uint8_t), length, fp);
if (bytesRead == length)
{
printf (" Data: ");
hexDump (buffer, length);
printf (" Text: %s\n", buffer);
}
offset = offset + length + sizeof(uint8_t) + sizeof(uint8_t);
printf ("\n");
}
return status;
}
/*--------------------------------------------------------------------------*/
// Return pointer to string for Hid.
/*--------------------------------------------------------------------------*/
const char *getHidString (unsigned int hid)
{
const char *ptr = "Unknown";
switch (hid)
{
case HID_MAKER_NOTES:
ptr = "Maker Notes";
break;
case HID_ACCELEROMETER:
ptr = "Accelerometer";
break;
case HID_EXPOSURE:
ptr = "Exposure";
break;
case HID_TIMESTAMPS:
ptr = "Timestamps";
break;
case HID_GPS:
ptr = "GPS";
break;
}
return ptr;
}
/*--------------------------------------------------------------------------*/
// Return pointer to string for MakerNotes ID.
/*--------------------------------------------------------------------------*/
const char *getMakerNotesString (unsigned int id)
{
const char *ptr = "Unknown";
switch (id)
{
case MAKER_NOTES_SERIALNUMBER:
ptr = "SerialNumber";
break;
case MAKER_NOTES_MODEL:
ptr = "Model";
break;
case MAKER_NOTES_FIRMWARE:
ptr = "Firmware";
break;
case MAKER_NOTES_PARAMTERS:
ptr = "Parameters";
break;
}
return ptr;
}
/*--------------------------------------------------------------------------*/
// Read U32, convert and return.
/*--------------------------------------------------------------------------*/
uint32_t freadU32 (FILE *fp)
{
uint32_t val = 0;
uint8_t a,b,c,d;
a = freadU8 (fp);
b = freadU8 (fp);
c = freadU8 (fp);
d = freadU8 (fp);
val = (a) | (b << 8) | (c << 16) | (d << 24);
return val;
}
/*--------------------------------------------------------------------------*/
// Read U16, convert and return.
/*--------------------------------------------------------------------------*/
uint16_t freadU16 (FILE *fp)
{
uint16_t val = 0;
uint8_t msb = 0;
uint8_t lsb = 0;
msb = freadU8 (fp);
lsb = freadU8 (fp);
val = (msb << 8) | (lsb);
return val;
}
/*--------------------------------------------------------------------------*/
// Read U8.
/*--------------------------------------------------------------------------*/
uint8_t freadU8 (FILE *fp)
{
uint8_t val = 0;
val = fgetc (fp);
return val;
}
/*--------------------------------------------------------------------------*/
// Dump bytes as HEX, with a tab at the start of lines after the first.
/*--------------------------------------------------------------------------*/
void hexDump (void *ptr, size_t size)
{
int col = 1;
if (ptr != NULL)
{
for (int idx=0; idx<size; idx++)
{
printf ("%02x ", ((uint8_t*)ptr)[idx]);
if ((col % 16) == 0)
{
printf ("\n\t");
col = 0;
}
col++;
}
printf ("\n");
}
}
// End of main.c
I am posting this in case someone else is doing the same searches I am.
I am trying to find details on the Insta360 ONE X2 file formats for photos (.insp) and videos (.insv). They contain meta-data I’d like to be able and parse to determine what kind of files they are. Going by filename is not enough.Th
This came up again today when someone contacted me with a ONE X2 video that was recorded in Bullet Time mode. It was not meant to be, but because the file is saved that way, the Insta360 Studio program will not allow reframing/editing the video.
Insta360 support (via app chat) has an auto responder if you ask about changing Bullet Time files to normal videos, so they have a way to do it — if you send them the files.
In the case of Bullet Time, is is recorded at 100 fps in 3K mode. It stores both lens videos in the same file. This is the same format used when recording normal 360 video at 3K / 100 fps. It appears only the meta-data is making the file appear one way or the other.
To be continued…